 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBias Discovery in Machine Learning Models for Mental Health
May 24, 2022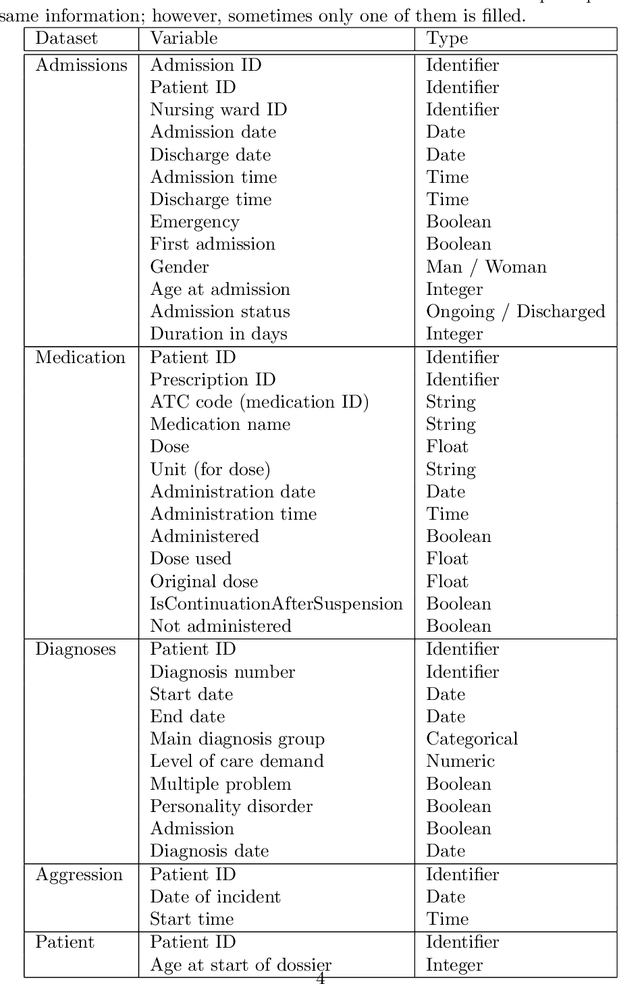
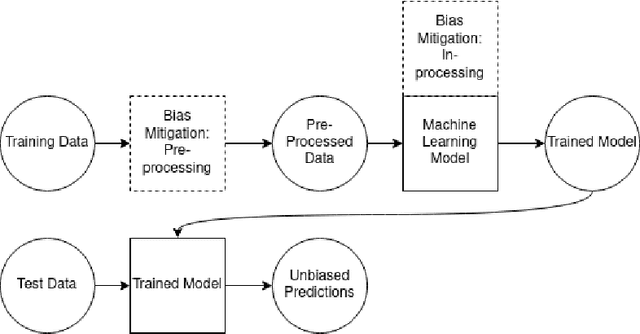
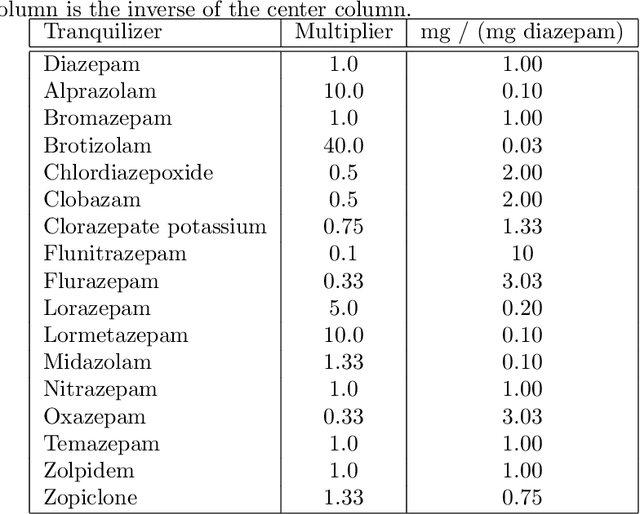
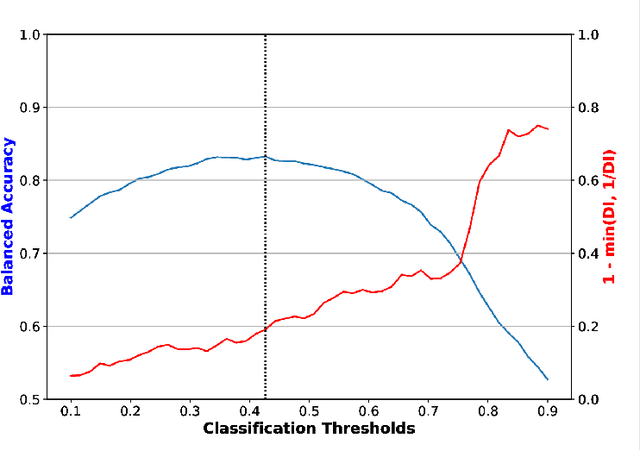
Fairness and bias are crucial concepts in artificial intelligence, yet they are relatively ignored in machine learning applications in clinical psychiatry. We computed fairness metrics and present bias mitigation strategies using a model trained on clinical mental health data. We collected structured data related to the admission, diagnosis, and treatment of patients in the psychiatry department of the University Medical Center Utrecht. We trained a machine learning model to predict future administrations of benzodiazepines on the basis of past data. We found that gender plays an unexpected role in the predictions-this constitutes bias. Using the AI Fairness 360 package, we implemented reweighing and discrimination-aware regularization as bias mitigation strategies, and we explored their implications for model performance. This is the first application of bias exploration and mitigation in a machine learning model trained on real clinical psychiatry data.
Federated learning for violence incident prediction in a simulated cross-institutional psychiatric setting
May 17, 2022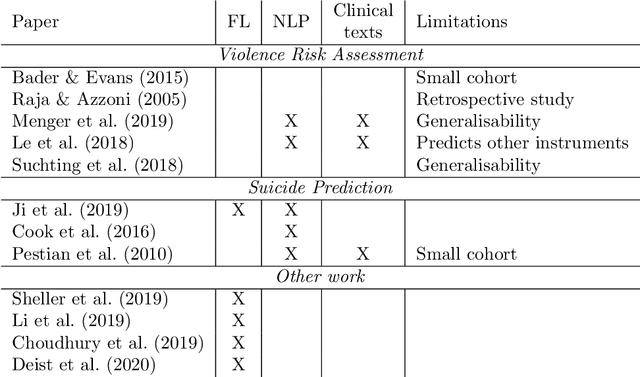
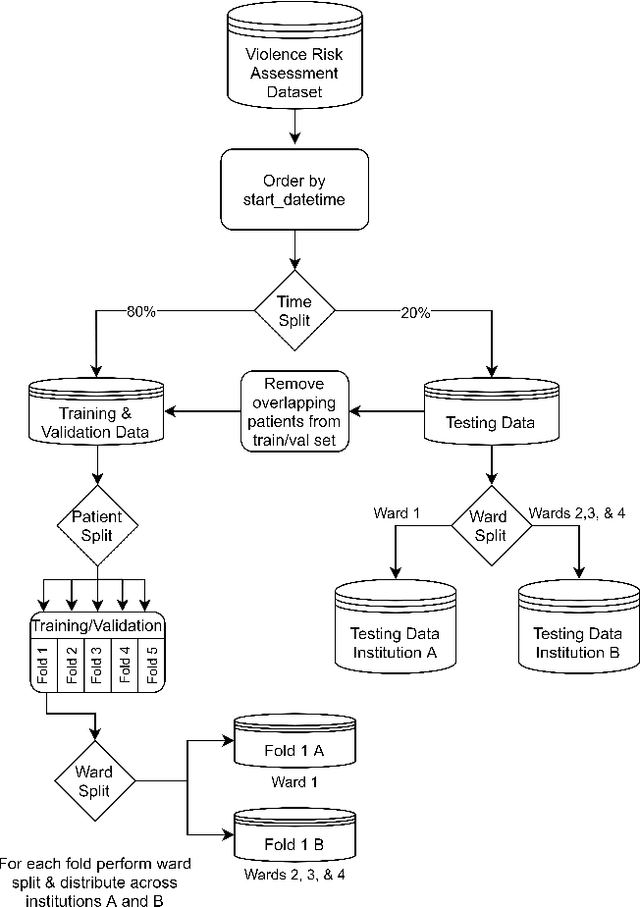

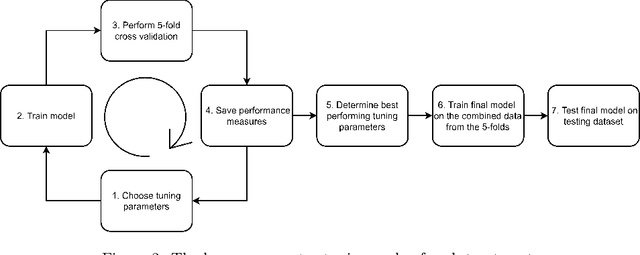
Inpatient violence is a common and severe problem within psychiatry. Knowing who might become violent can influence staffing levels and mitigate severity. Predictive machine learning models can assess each patient's likelihood of becoming violent based on clinical notes. Yet, while machine learning models benefit from having more data, data availability is limited as hospitals typically do not share their data for privacy preservation. Federated Learning (FL) can overcome the problem of data limitation by training models in a decentralised manner, without disclosing data between collaborators. However, although several FL approaches exist, none of these train Natural Language Processing models on clinical notes. In this work, we investigate the application of Federated Learning to clinical Natural Language Processing, applied to the task of Violence Risk Assessment by simulating a cross-institutional psychiatric setting. We train and compare four models: two local models, a federated model and a data-centralised model. Our results indicate that the federated model outperforms the local models and has similar performance as the data-centralised model. These findings suggest that Federated Learning can be used successfully in a cross-institutional setting and is a step towards new applications of Federated Learning based on clinical notes
Making sense of violence risk predictions using clinical notes
Apr 29, 2022
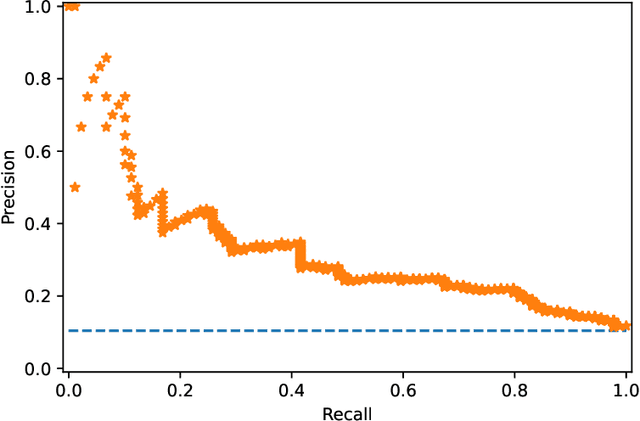
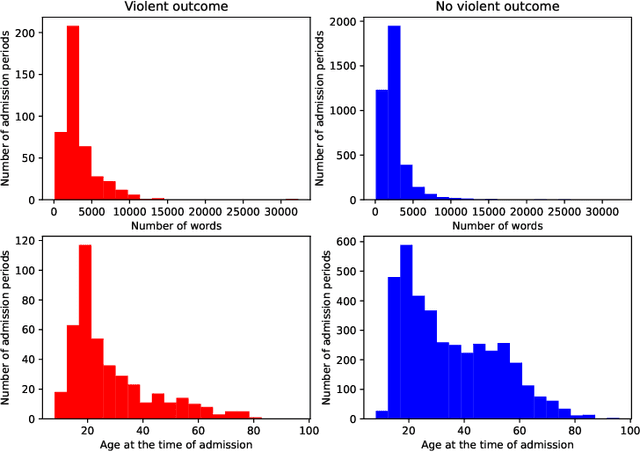
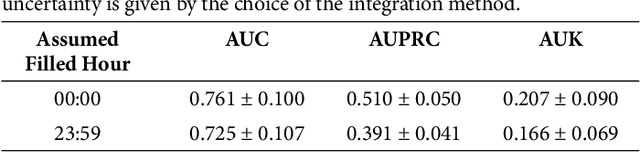
Violence risk assessment in psychiatric institutions enables interventions to avoid violence incidents. Clinical notes written by practitioners and available in electronic health records (EHR) are valuable resources that are seldom used to their full potential. Previous studies have attempted to assess violence risk in psychiatric patients using such notes, with acceptable performance. However, they do not explain why classification works and how it can be improved. We explore two methods to better understand the quality of a classifier in the context of clinical note analysis: random forests using topic models, and choice of evaluation metric. These methods allow us to understand both our data and our methodology more profoundly, setting up the groundwork to work on improved models that build upon this understanding. This is particularly important when it comes to the generalizability of evaluated classifiers to new data, a trustworthiness problem that is of great interest due to the increased availability of new data in electronic format.
* arXiv admin note: substantial text overlap with arXiv:2204.13535
Machine Learning for Violence Risk Assessment Using Dutch Clinical Notes
Apr 28, 2022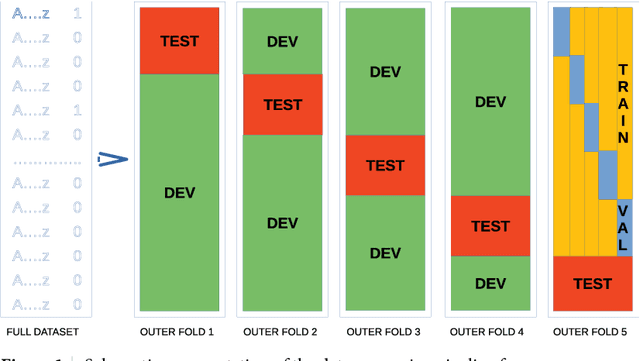

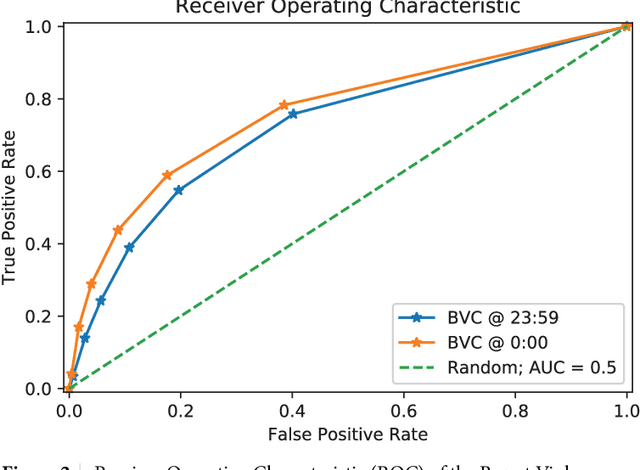
Violence risk assessment in psychiatric institutions enables interventions to avoid violence incidents. Clinical notes written by practitioners and available in electronic health records are valuable resources capturing unique information, but are seldom used to their full potential. We explore conventional and deep machine learning methods to assess violence risk in psychiatric patients using practitioner notes. The performance of our best models is comparable to the currently used questionnaire-based method, with an area under the Receiver Operating Characteristic curve of approximately 0.8. We find that the deep-learning model BERTje performs worse than conventional machine learning methods. We also evaluate our data and our classifiers to understand the performance of our models better. This is particularly important for the applicability of evaluated classifiers to new data, and is also of great interest to practitioners, due to the increased availability of new data in electronic format.