 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaking sense of violence risk predictions using clinical notes
Apr 29, 2022
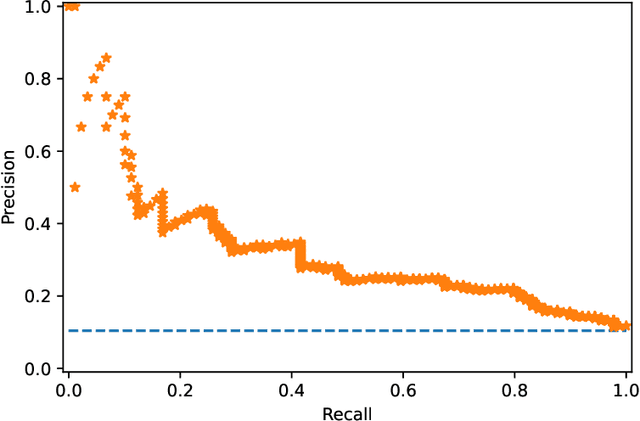
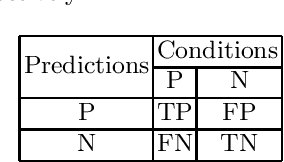
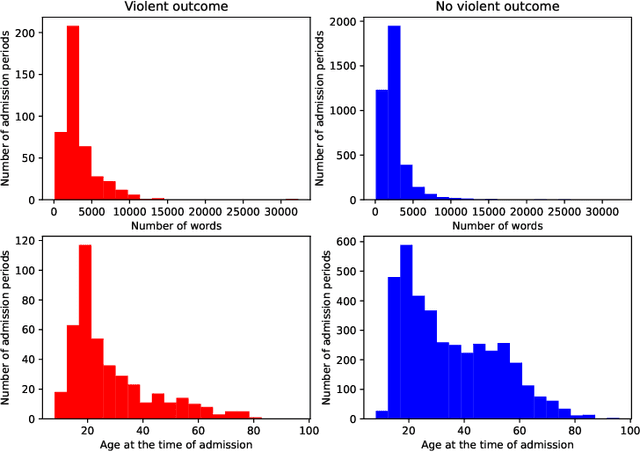
Violence risk assessment in psychiatric institutions enables interventions to avoid violence incidents. Clinical notes written by practitioners and available in electronic health records (EHR) are valuable resources that are seldom used to their full potential. Previous studies have attempted to assess violence risk in psychiatric patients using such notes, with acceptable performance. However, they do not explain why classification works and how it can be improved. We explore two methods to better understand the quality of a classifier in the context of clinical note analysis: random forests using topic models, and choice of evaluation metric. These methods allow us to understand both our data and our methodology more profoundly, setting up the groundwork to work on improved models that build upon this understanding. This is particularly important when it comes to the generalizability of evaluated classifiers to new data, a trustworthiness problem that is of great interest due to the increased availability of new data in electronic format.
* arXiv admin note: substantial text overlap with arXiv:2204.13535
Machine Learning for Violence Risk Assessment Using Dutch Clinical Notes
Apr 28, 2022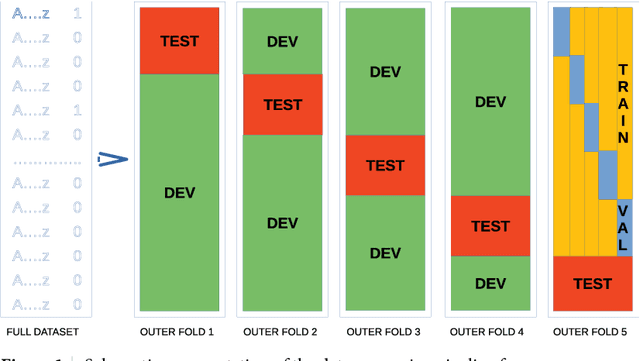

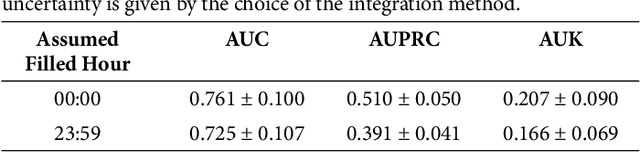
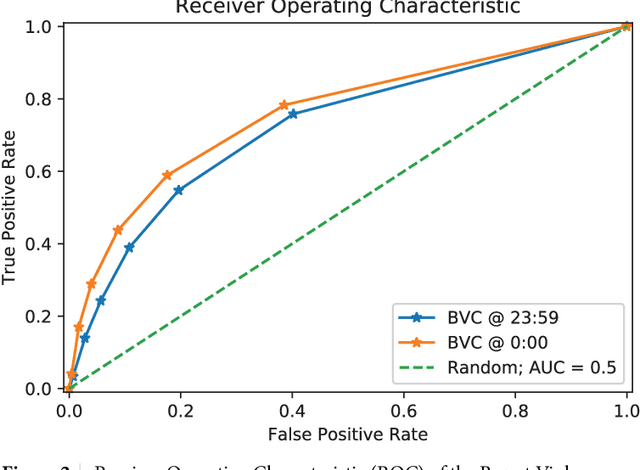
Violence risk assessment in psychiatric institutions enables interventions to avoid violence incidents. Clinical notes written by practitioners and available in electronic health records are valuable resources capturing unique information, but are seldom used to their full potential. We explore conventional and deep machine learning methods to assess violence risk in psychiatric patients using practitioner notes. The performance of our best models is comparable to the currently used questionnaire-based method, with an area under the Receiver Operating Characteristic curve of approximately 0.8. We find that the deep-learning model BERTje performs worse than conventional machine learning methods. We also evaluate our data and our classifiers to understand the performance of our models better. This is particularly important for the applicability of evaluated classifiers to new data, and is also of great interest to practitioners, due to the increased availability of new data in electronic format.