 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeePAQ: A Perceptual Audio Quality Metric Based On Foundational Models and Weakly Supervised Learning
Oct 14, 2025This paper presents the Deep learning-based Perceptual Audio Quality metric (DeePAQ) for evaluating general audio quality. Our approach leverages metric learning together with the music foundation model MERT, guided by surrogate labels, to construct an embedding space that captures distortion intensity in general audio. To the best of our knowledge, DeePAQ is the first in the general audio quality domain to leverage weakly supervised labels and metric learning for fine-tuning a music foundation model with Low-Rank Adaptation (LoRA), a direction not yet explored by other state-of-the-art methods. We benchmark the proposed model against state-of-the-art objective audio quality metrics across listening tests spanning audio coding and source separation. Results show that our method surpasses existing metrics in detecting coding artifacts and generalizes well to unseen distortions such as source separation, highlighting its robustness and versatility.
RF-GML: Reference-Free Generative Machine Listener
Sep 16, 2024



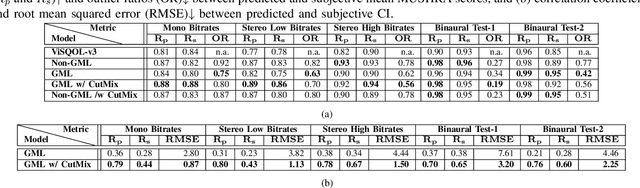
This paper introduces a novel reference-free (RF) audio quality metric called the RF-Generative Machine Listener (RF-GML), designed to evaluate coded mono, stereo, and binaural audio at a 48 kHz sample rate. RF-GML leverages transfer learning from a state-of-the-art full-reference (FR) Generative Machine Listener (GML) with minimal architectural modifications. The term "generative" refers to the model's ability to generate an arbitrary number of simulated listening scores. Unlike existing RF models, RF-GML accurately predicts subjective quality scores across diverse content types and codecs. Extensive evaluations demonstrate its superiority in rating unencoded audio and distinguishing different levels of coding artifacts. RF-GML's performance and versatility make it a valuable tool for coded audio quality assessment and monitoring in various applications, all without the need for a reference signal.
Generative Machine Listener
Aug 18, 2023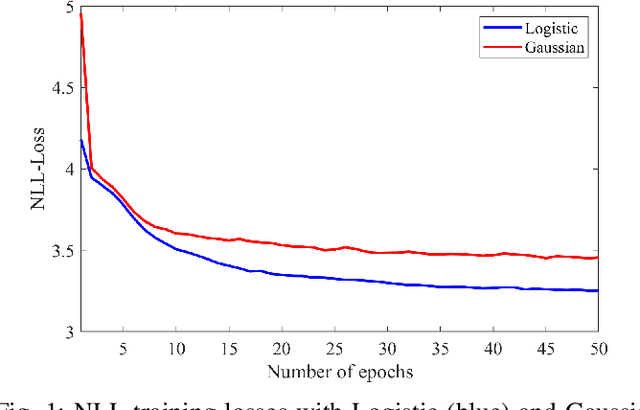
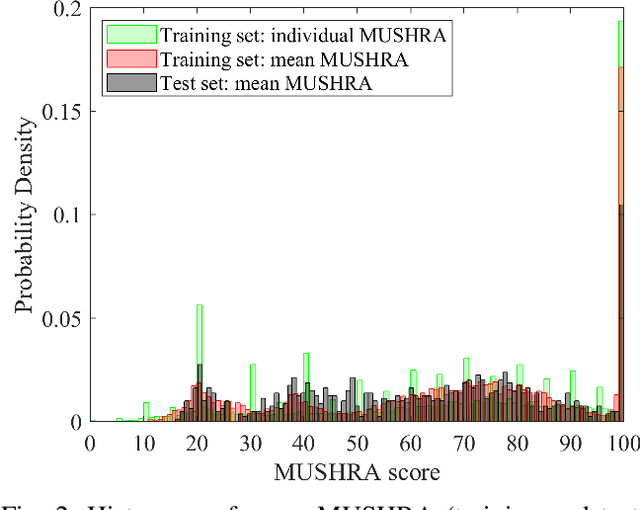
We show how a neural network can be trained on individual intrusive listening test scores to predict a distribution of scores for each pair of reference and coded input stereo or binaural signals. We nickname this method the Generative Machine Listener (GML), as it is capable of generating an arbitrary amount of simulated listening test data. Compared to a baseline system using regression over mean scores, we observe lower outlier ratios (OR) for the mean score predictions, and obtain easy access to the prediction of confidence intervals (CI). The introduction of data augmentation techniques from the image domain results in a significant increase in CI prediction accuracy as well as Pearson and Spearman rank correlation of mean scores.
Stereo InSE-NET: Stereo Audio Quality Predictor Transfer Learned from Mono InSE-NET
Sep 23, 2022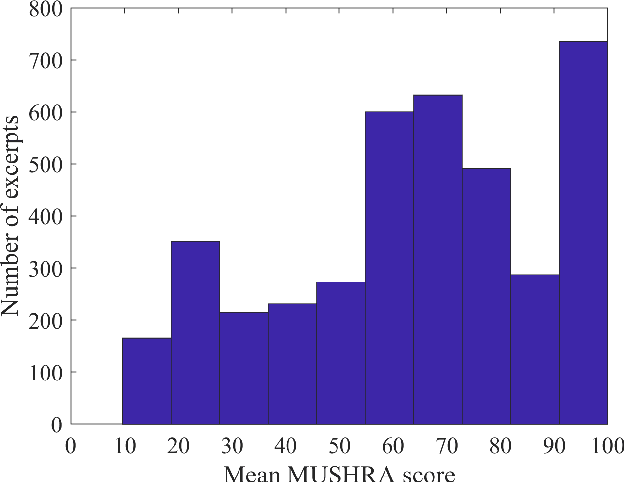
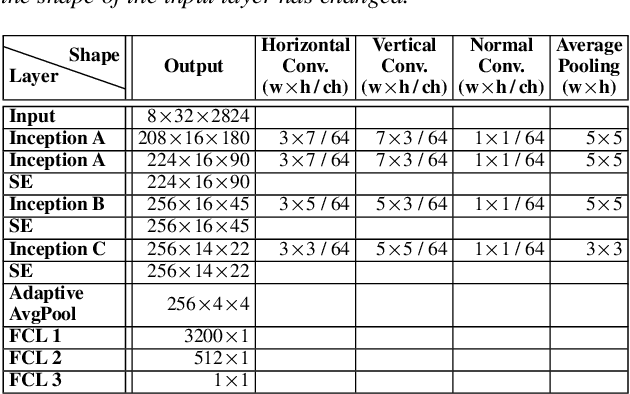
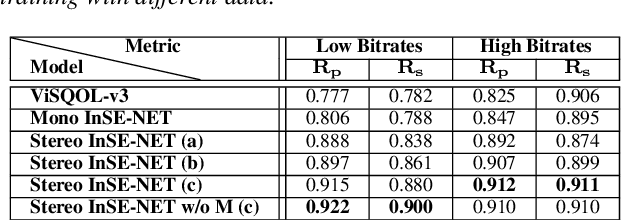
Automatic coded audio quality predictors are typically designed for evaluating single channels without considering any spatial aspects. With InSE-NET [1], we demonstrated mimicking a state-of-the-art coded audio quality metric (ViSQOL-v3 [2]) with deep neural networks (DNN) and subsequently improving it - completely with programmatically generated data. In this study, we take steps towards building a DNN-based coded stereo audio quality predictor and we propose an extension of the InSE-NET for handling stereo signals. The design considers stereo/spatial aspects by conditioning the model with left, right, mid, and side channels; and we name our model Stereo InSE-NET. By transferring selected weights from the pre-trained mono InSE-NET and retraining with both real and synthetically augmented listening tests, we demonstrate a significant improvement of 12% and 6% of Pearson and Spearman Rank correlation coefficient, respectively, over the latest ViSQOL-v3 [3].
InSE-NET: A Perceptually Coded Audio Quality Model based on CNN
Aug 30, 2021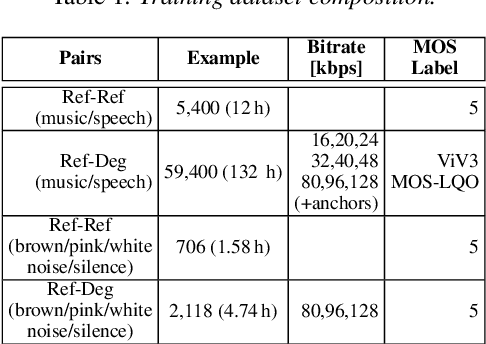
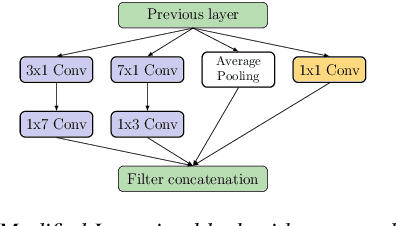
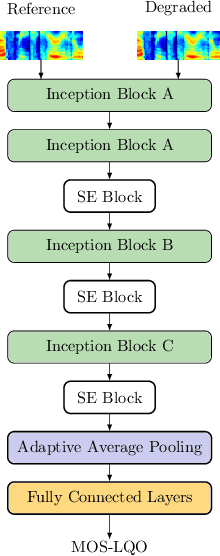
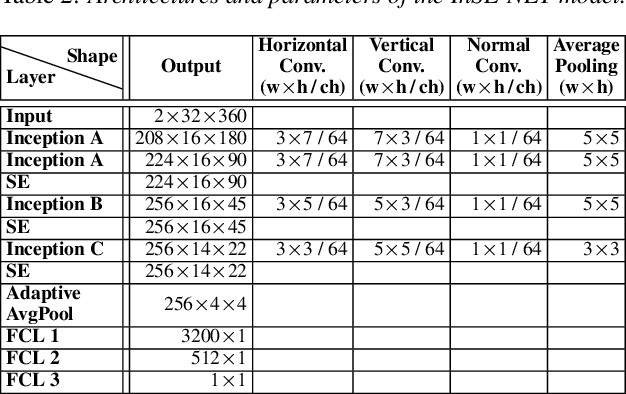
Automatic coded audio quality assessment is an important task whose progress is hampered by the scarcity of human annotations, poor generalization to unseen codecs, bitrates, content-types, and a lack of flexibility of existing approaches. One of the typical human-perception-related metrics, ViSQOL v3 (ViV3), has been proven to provide a high correlation to the quality scores rated by humans. In this study, we take steps to tackle problems of predicting coded audio quality by completely utilizing programmatically generated data that is informed with expert domain knowledge. We propose a learnable neural network, entitled InSE-NET, with a backbone of Inception and Squeeze-and-Excitation modules to assess the perceived quality of coded audio at a 48kHz sample rate. We demonstrate that synthetic data augmentation is capable of enhancing the prediction. Our proposed method is intrusive, i.e. it requires Gammatone spectrograms of unencoded reference signals. Besides a comparable performance to ViV3, our approach provides a more robust prediction towards higher bitrates.