 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudio Decoding by Inverse Problem Solving
Sep 12, 2024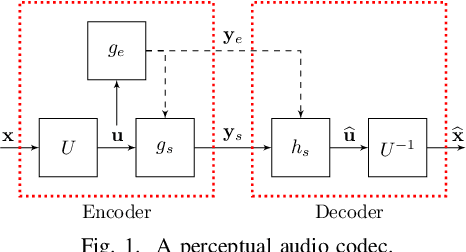

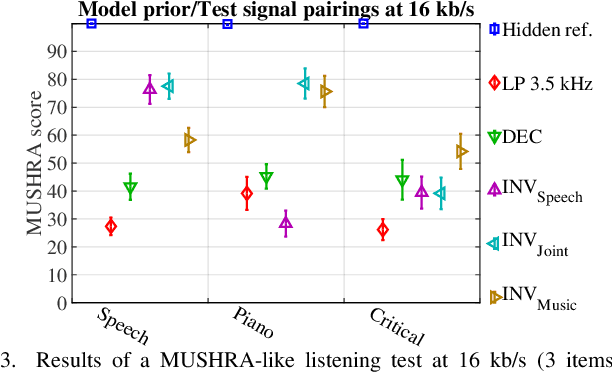
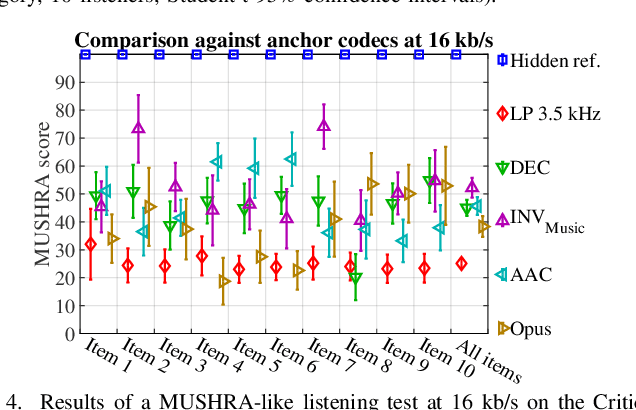
We consider audio decoding as an inverse problem and solve it through diffusion posterior sampling. Explicit conditioning functions are developed for input signal measurements provided by an example of a transform domain perceptual audio codec. Viability is demonstrated by evaluating arbitrary pairings of a set of bitrates and task-agnostic prior models. For instance, we observe significant improvements on piano while maintaining speech performance when a speech model is replaced by a joint model trained on both speech and piano. With a more general music model, improved decoding compared to legacy methods is obtained for a broad range of content types and bitrates. The noisy mean model, underlying the proposed derivation of conditioning, enables a significant reduction of gradient evaluations for diffusion posterior sampling, compared to methods based on Tweedie's mean. Combining Tweedie's mean with our conditioning functions improves the objective performance. An audio demo is available at https://dpscodec-demo.github.io/.
Generative Machine Listener
Aug 18, 2023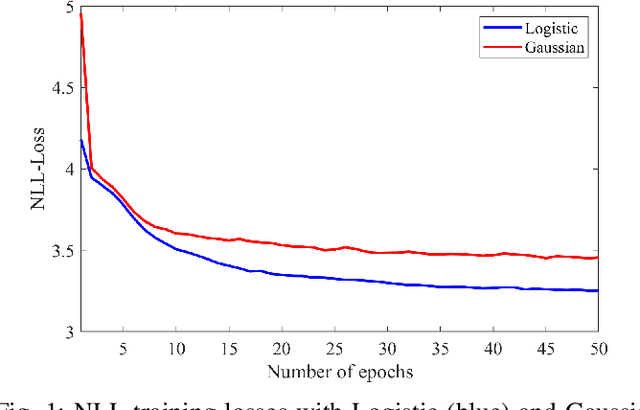
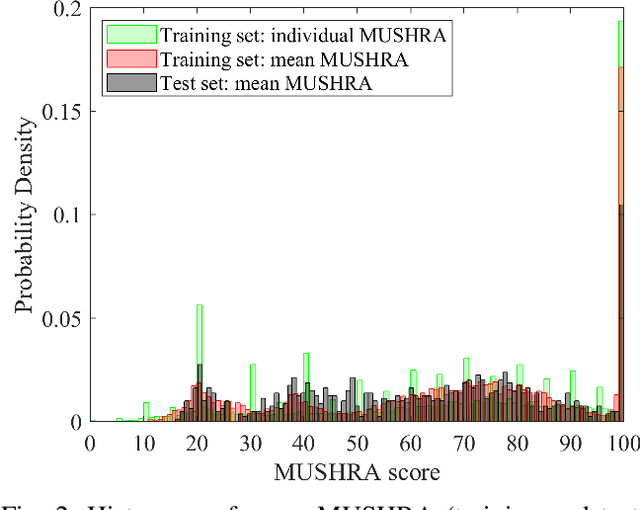
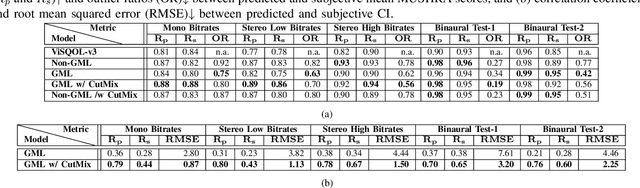
We show how a neural network can be trained on individual intrusive listening test scores to predict a distribution of scores for each pair of reference and coded input stereo or binaural signals. We nickname this method the Generative Machine Listener (GML), as it is capable of generating an arbitrary amount of simulated listening test data. Compared to a baseline system using regression over mean scores, we observe lower outlier ratios (OR) for the mean score predictions, and obtain easy access to the prediction of confidence intervals (CI). The introduction of data augmentation techniques from the image domain results in a significant increase in CI prediction accuracy as well as Pearson and Spearman rank correlation of mean scores.
Distribution Preserving Source Separation With Time Frequency Predictive Models
Mar 10, 2023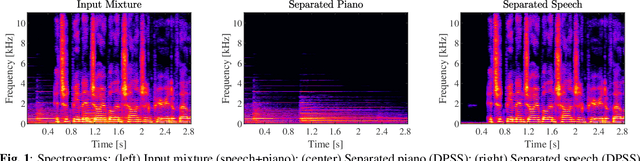
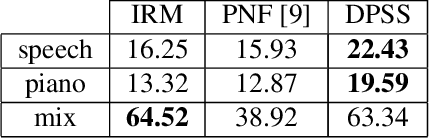
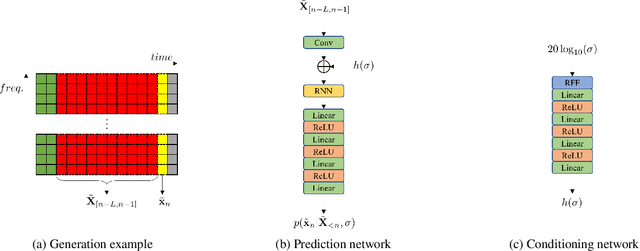
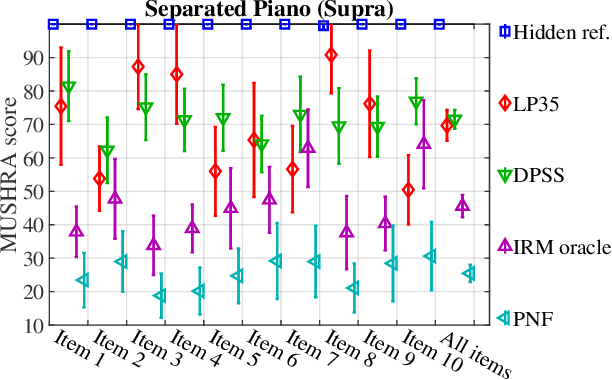
We provide an example of a distribution preserving source separation method, which aims at addressing perceptual shortcomings of state-of-the-art methods. Our approach uses unconditioned generative models of signal sources. Reconstruction is achieved by means of mix-consistent sampling from a distribution conditioned on a realization of a mix. The separated signals follow their respective source distributions, which provides an advantage when separation results are evaluated in a listening test.
High Quality Audio Coding with MDCTNet
Dec 08, 2022



We propose a neural audio generative model, MDCTNet, operating in the perceptually weighted domain of an adaptive modified discrete cosine transform (MDCT). The architecture of the model captures correlations in both time and frequency directions with recurrent layers (RNNs). An audio coding system is obtained by training MDCTNet on a diverse set of fullband monophonic audio signals at 48 kHz sampling, conditioned by a perceptual audio encoder. In a subjective listening test with ten excerpts chosen to be balanced across content types, yet stressful for both codecs, the mean performance of the proposed system for 24 kb/s variable bitrate (VBR) is similar to that of Opus at twice the bitrate.