 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplaining Humour Style Classifications: An XAI Approach to Understanding Computational Humour Analysis
Jan 06, 2025Humour styles can have either a negative or a positive impact on well-being. Given the importance of these styles to mental health, significant research has been conducted on their automatic identification. However, the automated machine learning models used for this purpose are black boxes, making their prediction decisions opaque. Clarity and transparency are vital in the field of mental health. This paper presents an explainable AI (XAI) framework for understanding humour style classification, building upon previous work in computational humour analysis. Using the best-performing single model (ALI+XGBoost) from prior research, we apply comprehensive XAI techniques to analyse how linguistic, emotional, and semantic features contribute to humour style classification decisions. Our analysis reveals distinct patterns in how different humour styles are characterised and misclassified, with particular emphasis on the challenges in distinguishing affiliative humour from other styles. Through detailed examination of feature importance, error patterns, and misclassification cases, we identify key factors influencing model decisions, including emotional ambiguity, context misinterpretation, and target identification. The framework demonstrates significant utility in understanding model behaviour, achieving interpretable insights into the complex interplay of features that define different humour styles. Our findings contribute to both the theoretical understanding of computational humour analysis and practical applications in mental health, content moderation, and digital humanities research.
A Two-Model Approach for Humour Style Recognition
Oct 09, 2024Humour, a fundamental aspect of human communication, manifests itself in various styles that significantly impact social interactions and mental health. Recognising different humour styles poses challenges due to the lack of established datasets and machine learning (ML) models. To address this gap, we present a new text dataset for humour style recognition, comprising 1463 instances across four styles (self-enhancing, self-deprecating, affiliative, and aggressive) and non-humorous text, with lengths ranging from 4 to 229 words. Our research employs various computational methods, including classic machine learning classifiers, text embedding models, and DistilBERT, to establish baseline performance. Additionally, we propose a two-model approach to enhance humour style recognition, particularly in distinguishing between affiliative and aggressive styles. Our method demonstrates an 11.61% improvement in f1-score for affiliative humour classification, with consistent improvements in the 14 models tested. Our findings contribute to the computational analysis of humour in text, offering new tools for studying humour in literature, social media, and other textual sources.
Exploring Description-Augmented Dataless Intent Classification
Jul 25, 2024In this work, we introduce several schemes to leverage description-augmented embedding similarity for dataless intent classification using current state-of-the-art (SOTA) text embedding models. We report results of our methods on four commonly used intent classification datasets and compare against previous works of a similar nature. Our work shows promising results for dataless classification scaling to a large number of unseen intents. We show competitive results and significant improvements (+6.12\% Avg.) over strong zero-shot baselines, all without training on labelled or task-specific data. Furthermore, we provide qualitative error analysis of the shortfalls of this methodology to help guide future research in this area.
Systematic Literature Review: Computational Approaches for Humour Style Classification
Jan 30, 2024Understanding various humour styles is essential for comprehending the multifaceted nature of humour and its impact on fields such as psychology and artificial intelligence. This understanding has revealed that humour, depending on the style employed, can either have therapeutic or detrimental effects on an individual's health and relationships. Although studies dedicated exclusively to computational-based humour style analysis remain somewhat rare, an expansive body of research thrives within related task, particularly binary humour and sarcasm recognition. In this systematic literature review (SLR), we survey the landscape of computational techniques applied to these related tasks and also uncover their fundamental relevance to humour style analysis. Through this study, we unveil common approaches, illuminate various datasets and evaluation metrics, and effectively navigate the complex terrain of humour research. Our efforts determine potential research gaps and outlined promising directions. Furthermore, the SLR identifies a range of features and computational models that can seamlessly transition from related tasks like binary humour and sarcasm detection to invigorate humour style classification. These features encompass incongruity, sentiment and polarity analysis, ambiguity detection, acoustic nuances, visual cues, contextual insights, and more. The computational models that emerge contain traditional machine learning paradigms, neural network architectures, transformer-based models, and specialised models attuned to the nuances of humour. Finally, the SLR provides access to existing datasets related to humour and sarcasm, facilitating the work of future researchers.
A Multilingual Virtual Guide for Self-Attachment Technique
Oct 25, 2023In this work, we propose a computational framework that leverages existing out-of-language data to create a conversational agent for the delivery of Self-Attachment Technique (SAT) in Mandarin. Our framework does not require large-scale human translations, yet it achieves a comparable performance whilst also maintaining safety and reliability. We propose two different methods of augmenting available response data through empathetic rewriting. We evaluate our chatbot against a previous, English-only SAT chatbot through non-clinical human trials (N=42), each lasting five days, and quantitatively show that we are able to attain a comparable level of performance to the English SAT chatbot. We provide qualitative analysis on the limitations of our study and suggestions with the aim of guiding future improvements.
From Words and Exercises to Wellness: Farsi Chatbot for Self-Attachment Technique
Oct 13, 2023In the wake of the post-pandemic era, marked by social isolation and surging rates of depression and anxiety, conversational agents based on digital psychotherapy can play an influential role compared to traditional therapy sessions. In this work, we develop a voice-capable chatbot in Farsi to guide users through Self-Attachment (SAT), a novel, self-administered, holistic psychological technique based on attachment theory. Our chatbot uses a dynamic array of rule-based and classification-based modules to comprehend user input throughout the conversation and navigates a dialogue flowchart accordingly, recommending appropriate SAT exercises that depend on the user's emotional and mental state. In particular, we collect a dataset of over 6,000 utterances and develop a novel sentiment-analysis module that classifies user sentiment into 12 classes, with accuracy above 92%. To keep the conversation novel and engaging, the chatbot's responses are retrieved from a large dataset of utterances created with the aid of Farsi GPT-2 and a reinforcement learning approach, thus requiring minimal human annotation. Our chatbot also offers a question-answering module, called SAT Teacher, to answer users' questions about the principles of Self-Attachment. Finally, we design a cross-platform application as the bot's user interface. We evaluate our platform in a ten-day human study with N=52 volunteers from the non-clinical population, who have had over 2,000 dialogues in total with the chatbot. The results indicate that the platform was engaging to most users (75%), 72% felt better after the interactions, and 74% were satisfied with the SAT Teacher's performance.
An Empathetic AI Coach for Self-Attachment Therapy
Sep 17, 2022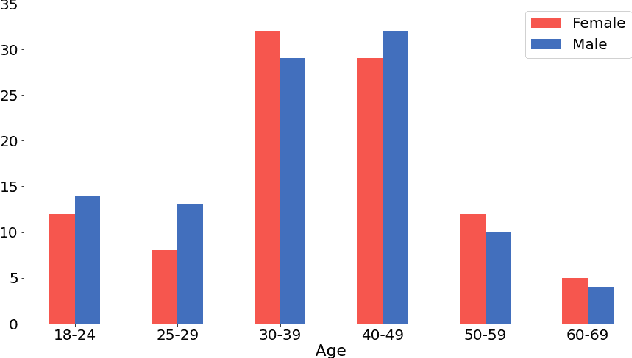

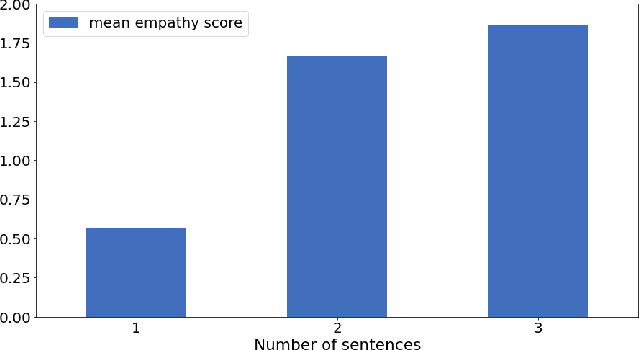

In this work, we present a new dataset and a computational strategy for a digital coach that aims to guide users in practicing the protocols of self-attachment therapy. Our framework augments a rule-based conversational agent with a deep-learning classifier for identifying the underlying emotion in a user's text response, as well as a deep-learning assisted retrieval method for producing novel, fluent and empathetic utterances. We also craft a set of human-like personas that users can choose to interact with. Our goal is to achieve a high level of engagement during virtual therapy sessions. We evaluate the effectiveness of our framework in a non-clinical trial with N=16 participants, all of whom have had at least four interactions with the agent over the course of five days. We find that our platform is consistently rated higher for empathy, user engagement and usefulness than the simple rule-based framework. Finally, we provide guidelines to further improve the design and performance of the application, in accordance with the feedback received.