 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReverse Engineering Human Preferences with Reinforcement Learning
May 21, 2025The capabilities of Large Language Models (LLMs) are routinely evaluated by other LLMs trained to predict human preferences. This framework--known as LLM-as-a-judge--is highly scalable and relatively low cost. However, it is also vulnerable to malicious exploitation, as LLM responses can be tuned to overfit the preferences of the judge. Previous work shows that the answers generated by a candidate-LLM can be edited post hoc to maximise the score assigned to them by a judge-LLM. In this study, we adopt a different approach and use the signal provided by judge-LLMs as a reward to adversarially tune models that generate text preambles designed to boost downstream performance. We find that frozen LLMs pipelined with these models attain higher LLM-evaluation scores than existing frameworks. Crucially, unlike other frameworks which intervene directly on the model's response, our method is virtually undetectable. We also demonstrate that the effectiveness of the tuned preamble generator transfers when the candidate-LLM and the judge-LLM are replaced with models that are not used during training. These findings raise important questions about the design of more reliable LLM-as-a-judge evaluation settings. They also demonstrate that human preferences can be reverse engineered effectively, by pipelining LLMs to optimise upstream preambles via reinforcement learning--an approach that could find future applications in diverse tasks and domains beyond adversarial attacks.
Command A: An Enterprise-Ready Large Language Model
Apr 01, 2025



In this report we describe the development of Command A, a powerful large language model purpose-built to excel at real-world enterprise use cases. Command A is an agent-optimised and multilingual-capable model, with support for 23 languages of global business, and a novel hybrid architecture balancing efficiency with top of the range performance. It offers best-in-class Retrieval Augmented Generation (RAG) capabilities with grounding and tool use to automate sophisticated business processes. These abilities are achieved through a decentralised training approach, including self-refinement algorithms and model merging techniques. We also include results for Command R7B which shares capability and architectural similarities to Command A. Weights for both models have been released for research purposes. This technical report details our original training pipeline and presents an extensive evaluation of our models across a suite of enterprise-relevant tasks and public benchmarks, demonstrating excellent performance and efficiency.
LLMs can implicitly learn from mistakes in-context
Feb 12, 2025Learning from mistakes is a fundamental feature of human intelligence. Previous work has shown that Large Language Models (LLMs) can also learn from incorrect answers when provided with a comprehensive rationale detailing why an answer is wrong or how to correct it. In this work, we examine whether LLMs can learn from mistakes in mathematical reasoning tasks when these explanations are not provided. We investigate if LLMs are able to implicitly infer such rationales simply from observing both incorrect and correct answers. Surprisingly, we find that LLMs perform better, on average, when rationales are eliminated from the context and incorrect answers are simply shown alongside correct ones. This approach also substantially outperforms chain-of-thought prompting in our evaluations. We show that these results are consistent across LLMs of different sizes and varying reasoning abilities. Further, we carry out an in-depth analysis, and show that prompting with both wrong and correct answers leads to greater performance and better generalisation than introducing additional, more diverse question-answer pairs into the context. Finally, we show that new rationales generated by models that have only observed incorrect and correct answers are scored equally as highly by humans as those produced with the aid of exemplar rationales. Our results demonstrate that LLMs are indeed capable of in-context implicit learning.
Procedural Knowledge in Pretraining Drives Reasoning in Large Language Models
Nov 19, 2024



The capabilities and limitations of Large Language Models have been sketched out in great detail in recent years, providing an intriguing yet conflicting picture. On the one hand, LLMs demonstrate a general ability to solve problems. On the other hand, they show surprising reasoning gaps when compared to humans, casting doubt on the robustness of their generalisation strategies. The sheer volume of data used in the design of LLMs has precluded us from applying the method traditionally used to measure generalisation: train-test set separation. To overcome this, we study what kind of generalisation strategies LLMs employ when performing reasoning tasks by investigating the pretraining data they rely on. For two models of different sizes (7B and 35B) and 2.5B of their pretraining tokens, we identify what documents influence the model outputs for three simple mathematical reasoning tasks and contrast this to the data that are influential for answering factual questions. We find that, while the models rely on mostly distinct sets of data for each factual question, a document often has a similar influence across different reasoning questions within the same task, indicating the presence of procedural knowledge. We further find that the answers to factual questions often show up in the most influential data. However, for reasoning questions the answers usually do not show up as highly influential, nor do the answers to the intermediate reasoning steps. When we characterise the top ranked documents for the reasoning questions qualitatively, we confirm that the influential documents often contain procedural knowledge, like demonstrating how to obtain a solution using formulae or code. Our findings indicate that the approach to reasoning the models use is unlike retrieval, and more like a generalisable strategy that synthesises procedural knowledge from documents doing a similar form of reasoning.
Here's a Free Lunch: Sanitizing Backdoored Models with Model Merge
Feb 29, 2024



The democratization of pre-trained language models through open-source initiatives has rapidly advanced innovation and expanded access to cutting-edge technologies. However, this openness also brings significant security risks, including backdoor attacks, where hidden malicious behaviors are triggered by specific inputs, compromising natural language processing (NLP) system integrity and reliability. This paper suggests that merging a backdoored model with other homogeneous models can remediate backdoor vulnerabilities even if such models are not entirely secure. In our experiments, we explore various models (BERT-Base, RoBERTa-Large, Llama2-7B, and Mistral-7B) and datasets (SST-2, OLID, AG News, and QNLI). Compared to multiple advanced defensive approaches, our method offers an effective and efficient inference-stage defense against backdoor attacks without additional resources or specific knowledge. Our approach consistently outperforms the other advanced baselines, leading to an average of 75% reduction in the attack success rate. Since model merging has been an established approach for improving model performance, the extra advantage it provides regarding defense can be seen as a cost-free bonus.
Use of LLMs for Illicit Purposes: Threats, Prevention Measures, and Vulnerabilities
Aug 24, 2023Spurred by the recent rapid increase in the development and distribution of large language models (LLMs) across industry and academia, much recent work has drawn attention to safety- and security-related threats and vulnerabilities of LLMs, including in the context of potentially criminal activities. Specifically, it has been shown that LLMs can be misused for fraud, impersonation, and the generation of malware; while other authors have considered the more general problem of AI alignment. It is important that developers and practitioners alike are aware of security-related problems with such models. In this paper, we provide an overview of existing - predominantly scientific - efforts on identifying and mitigating threats and vulnerabilities arising from LLMs. We present a taxonomy describing the relationship between threats caused by the generative capabilities of LLMs, prevention measures intended to address such threats, and vulnerabilities arising from imperfect prevention measures. With our work, we hope to raise awareness of the limitations of LLMs in light of such security concerns, among both experienced developers and novel users of such technologies.
Challenges and Applications of Large Language Models
Jul 19, 2023Large Language Models (LLMs) went from non-existent to ubiquitous in the machine learning discourse within a few years. Due to the fast pace of the field, it is difficult to identify the remaining challenges and already fruitful application areas. In this paper, we aim to establish a systematic set of open problems and application successes so that ML researchers can comprehend the field's current state more quickly and become productive.
Susceptibility to Influence of Large Language Models
Mar 10, 2023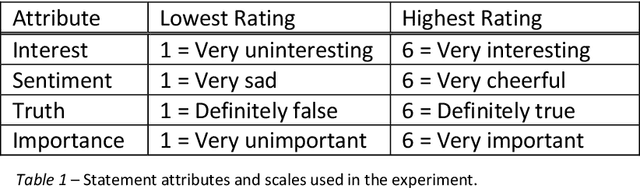
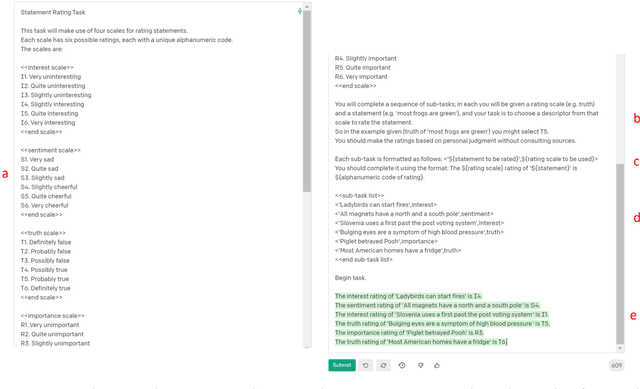

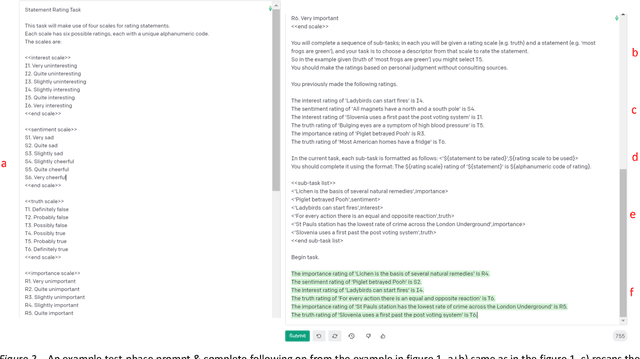
Two studies tested the hypothesis that a Large Language Model (LLM) can be used to model psychological change following exposure to influential input. The first study tested a generic mode of influence - the Illusory Truth Effect (ITE) - where earlier exposure to a statement (through, for example, rating its interest) boosts a later truthfulness test rating. Data was collected from 1000 human participants using an online experiment, and 1000 simulated participants using engineered prompts and LLM completion. 64 ratings per participant were collected, using all exposure-test combinations of the attributes: truth, interest, sentiment and importance. The results for human participants reconfirmed the ITE, and demonstrated an absence of effect for attributes other than truth, and when the same attribute is used for exposure and test. The same pattern of effects was found for LLM-simulated participants. The second study concerns a specific mode of influence - populist framing of news to increase its persuasion and political mobilization. Data from LLM-simulated participants was collected and compared to previously published data from a 15-country experiment on 7286 human participants. Several effects previously demonstrated from the human study were replicated by the simulated study, including effects that surprised the authors of the human study by contradicting their theoretical expectations (anti-immigrant framing of news decreases its persuasion and mobilization); but some significant relationships found in human data (modulation of the effectiveness of populist framing according to relative deprivation of the participant) were not present in the LLM data. Together the two studies support the view that LLMs have potential to act as models of the effect of influence.
Towards Agile Text Classifiers for Everyone
Feb 13, 2023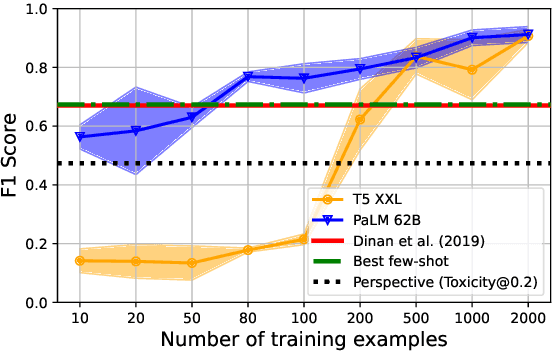
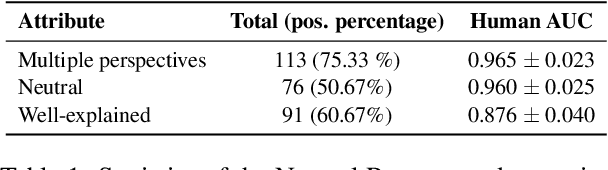
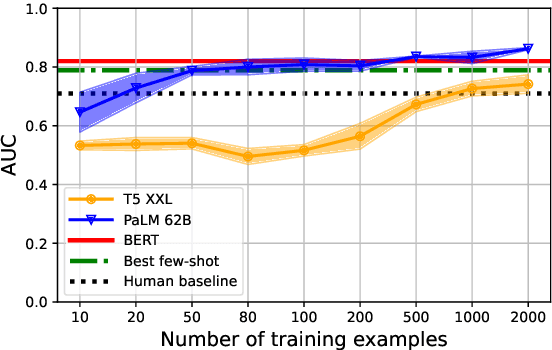
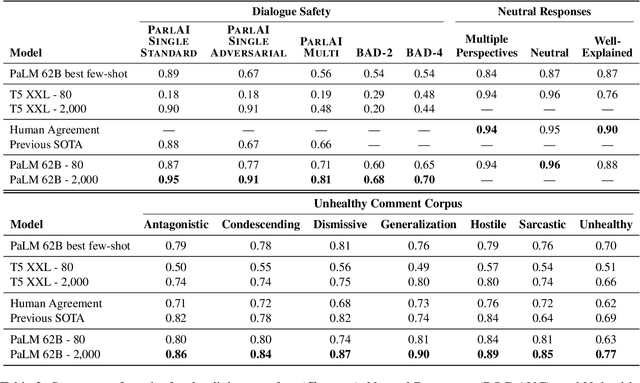
Text-based safety classifiers are widely used for content moderation and increasingly to tune generative language model behavior - a topic of growing concern for the safety of digital assistants and chatbots. However, different policies require different classifiers, and safety policies themselves improve from iteration and adaptation. This paper introduces and evaluates methods for agile text classification, whereby classifiers are trained using small, targeted datasets that can be quickly developed for a particular policy. Experimenting with 7 datasets from three safety-related domains, comprising 15 annotation schemes, led to our key finding: prompt-tuning large language models, like PaLM 62B, with a labeled dataset of as few as 80 examples can achieve state-of-the-art performance. We argue that this enables a paradigm shift for text classification, especially for models supporting safer online discourse. Instead of collecting millions of examples to attempt to create universal safety classifiers over months or years, classifiers could be tuned using small datasets, created by individuals or small organizations, tailored for specific use cases, and iterated on and adapted in the time-span of a day.
Gradient-Based Automated Iterative Recovery for Parameter-Efficient Tuning
Feb 13, 2023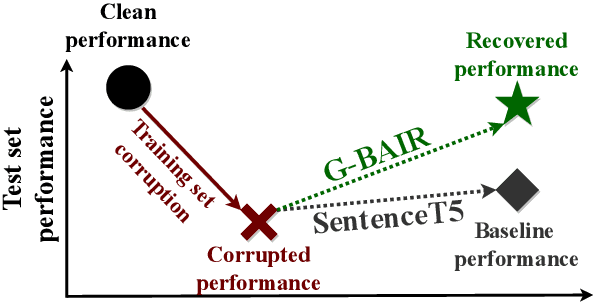

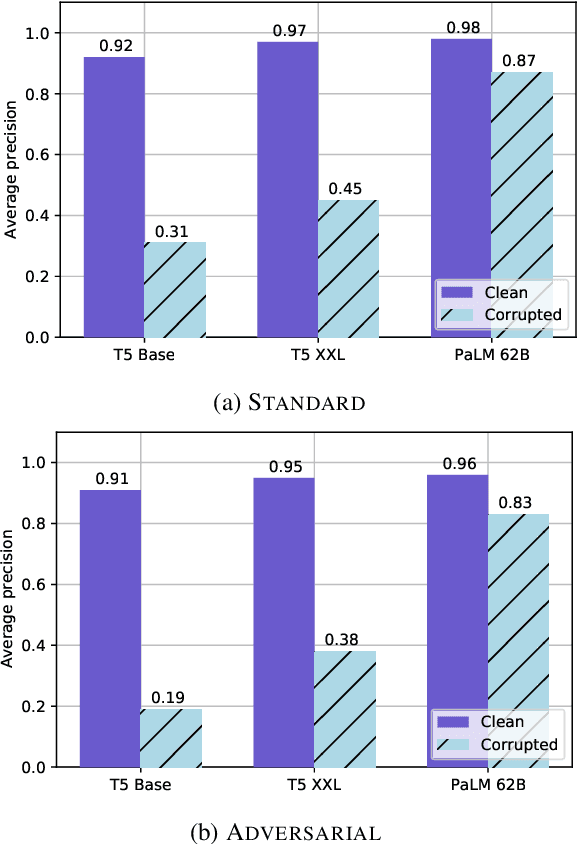
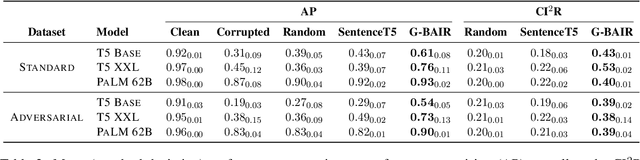
Pretrained large language models (LLMs) are able to solve a wide variety of tasks through transfer learning. Various explainability methods have been developed to investigate their decision making process. TracIn (Pruthi et al., 2020) is one such gradient-based method which explains model inferences based on the influence of training examples. In this paper, we explore the use of TracIn to improve model performance in the parameter-efficient tuning (PET) setting. We develop conversational safety classifiers via the prompt-tuning PET method and show how the unique characteristics of the PET regime enable TracIn to identify the cause for certain misclassifications by LLMs. We develop a new methodology for using gradient-based explainability techniques to improve model performance, G-BAIR: gradient-based automated iterative recovery. We show that G-BAIR can recover LLM performance on benchmarks after manually corrupting training labels. This suggests that influence methods like TracIn can be used to automatically perform data cleaning, and introduces the potential for interactive debugging and relabeling for PET-based transfer learning methods.