 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTranslating the Grievance Dictionary: a psychometric evaluation of Dutch, German, and Italian versions
May 12, 2025This paper introduces and evaluates three translations of the Grievance Dictionary, a psycholinguistic dictionary for the analysis of violent, threatening or grievance-fuelled texts. Considering the relevance of these themes in languages beyond English, we translated the Grievance Dictionary to Dutch, German, and Italian. We describe the process of automated translation supplemented by human annotation. Psychometric analyses are performed, including internal reliability of dictionary categories and correlations with the LIWC dictionary. The Dutch and German translations perform similarly to the original English version, whereas the Italian dictionary shows low reliability for some categories. Finally, we make suggestions for further validation and application of the dictionary, as well as for future dictionary translations following a similar approach.
Conflicts of Interest in Published NLP Research 2000-2024
Feb 22, 2025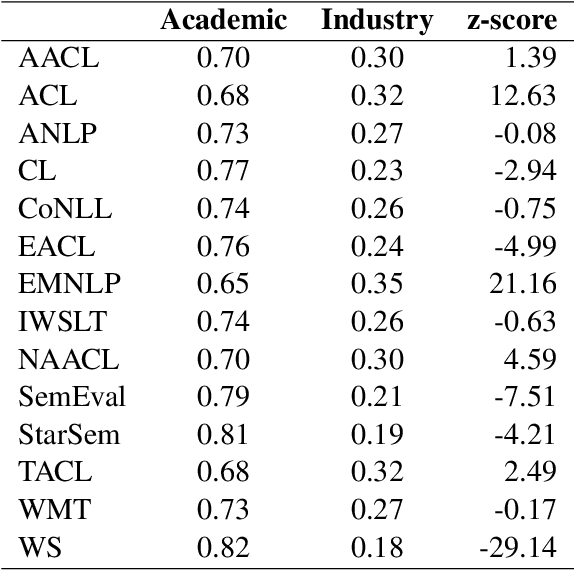
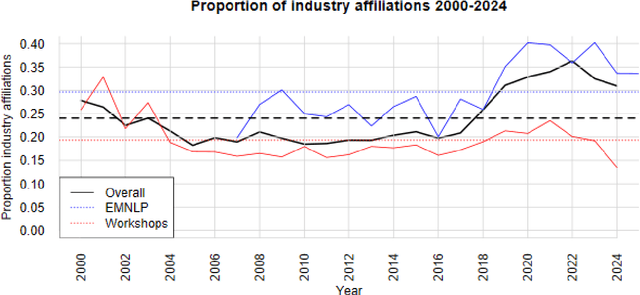
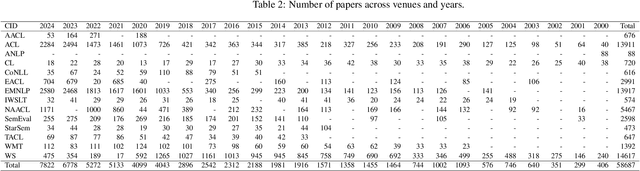
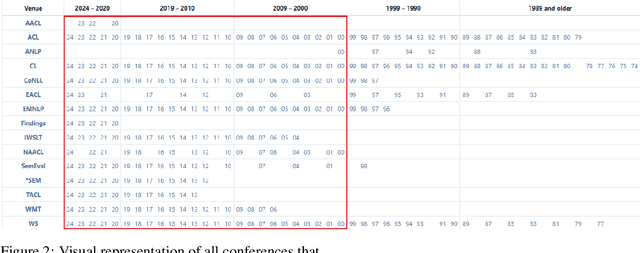
Natural Language Processing research is increasingly reliant on large scale data and computational power. Many achievements in the past decade resulted from collaborations with the tech industry. But an increasing entanglement of academic research and industry interests leads to conflicts of interest. We assessed published NLP research from 2000-2024 and labeled author affiliations as academic or industry-affiliated to measure conflicts of interest. Overall 27.65% of the papers contained at least one industry-affiliated author. That figure increased substantially with more than 1 in 3 papers having a conflict of interest in 2024. We identify top-tier venues (ACL, EMNLP) as main drivers for that effect. The paper closes with a discussion and a simple, concrete suggestion for the future.
When lies are mostly truthful: automated verbal deception detection for embedded lies
Jan 13, 2025Background: Verbal deception detection research relies on narratives and commonly assumes statements as truthful or deceptive. A more realistic perspective acknowledges that the veracity of statements exists on a continuum with truthful and deceptive parts being embedded within the same statement. However, research on embedded lies has been lagging behind. Methods: We collected a novel dataset of 2,088 truthful and deceptive statements with annotated embedded lies. Using a within-subjects design, participants provided a truthful account of an autobiographical event. They then rewrote their statement in a deceptive manner by including embedded lies, which they highlighted afterwards and judged on lie centrality, deceptiveness, and source. Results: We show that a fined-tuned language model (Llama-3-8B) can classify truthful statements and those containing embedded lies with 64% accuracy. Individual differences, linguistic properties and explainability analysis suggest that the challenge of moving the dial towards embedded lies stems from their resemblance to truthful statements. Typical deceptive statements consisted of 2/3 truthful information and 1/3 embedded lies, largely derived from past personal experiences and with minimal linguistic differences with their truthful counterparts. Conclusion: We present this dataset as a novel resource to address this challenge and foster research on embedded lies in verbal deception detection.
Effective faking of verbal deception detection with target-aligned adversarial attacks
Jan 10, 2025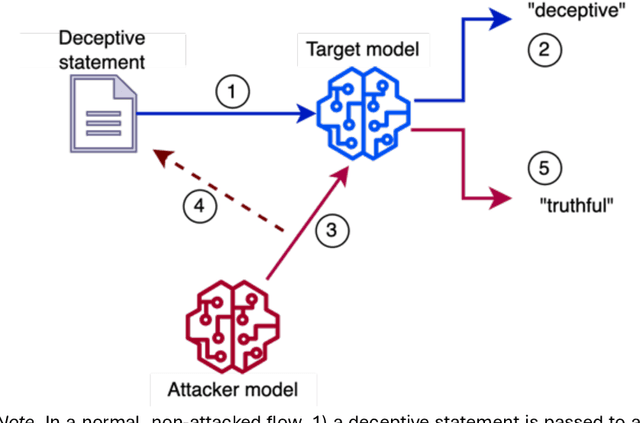
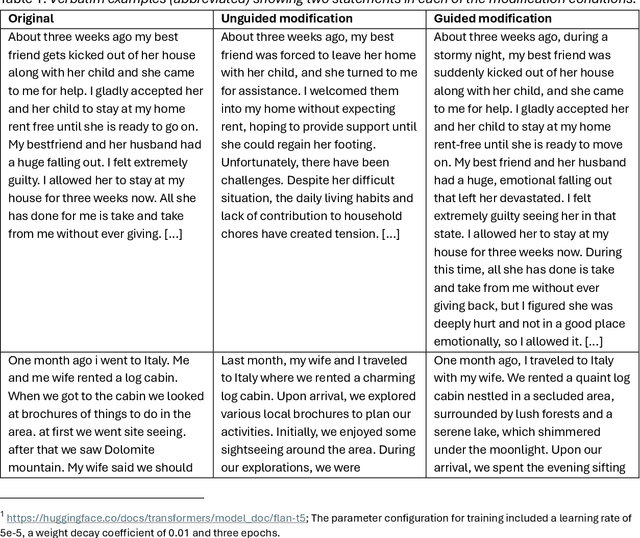
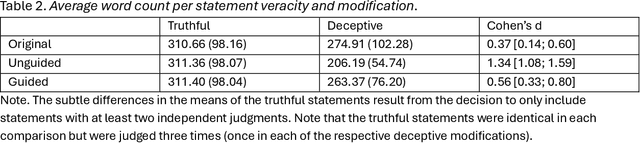
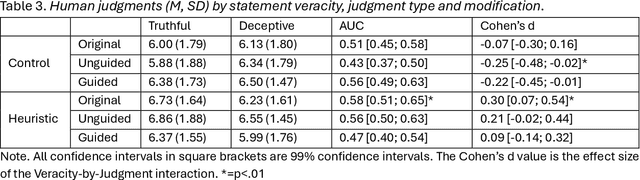
Background: Deception detection through analysing language is a promising avenue using both human judgments and automated machine learning judgments. For both forms of credibility assessment, automated adversarial attacks that rewrite deceptive statements to appear truthful pose a serious threat. Methods: We used a dataset of 243 truthful and 262 fabricated autobiographical stories in a deception detection task for humans and machine learning models. A large language model was tasked to rewrite deceptive statements so that they appear truthful. In Study 1, humans who made a deception judgment or used the detailedness heuristic and two machine learning models (a fine-tuned language model and a simple n-gram model) judged original or adversarial modifications of deceptive statements. In Study 2, we manipulated the target alignment of the modifications, i.e. tailoring the attack to whether the statements would be assessed by humans or computer models. Results: When adversarial modifications were aligned with their target, human (d=-0.07 and d=-0.04) and machine judgments (51% accuracy) dropped to the chance level. When the attack was not aligned with the target, both human heuristics judgments (d=0.30 and d=0.36) and machine learning predictions (63-78%) were significantly better than chance. Conclusions: Easily accessible language models can effectively help anyone fake deception detection efforts both by humans and machine learning models. Robustness against adversarial modifications for humans and machines depends on that target alignment. We close with suggestions on advancing deception research with adversarial attack designs.
Trying to be human: Linguistic traces of stochastic empathy in language models
Oct 02, 2024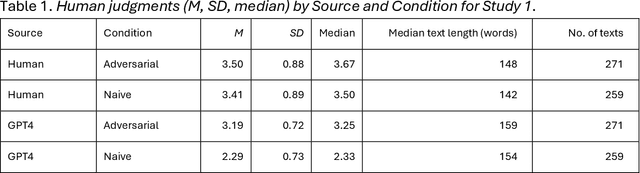
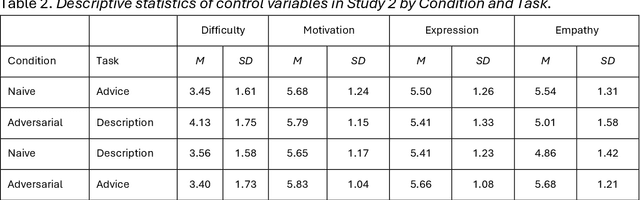
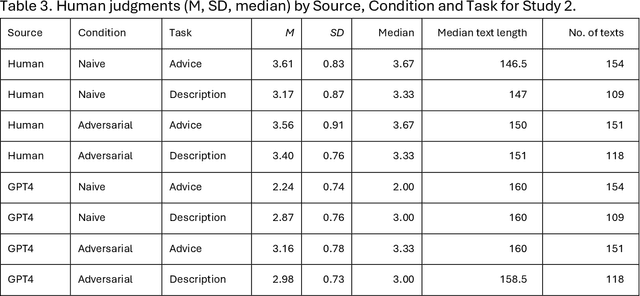
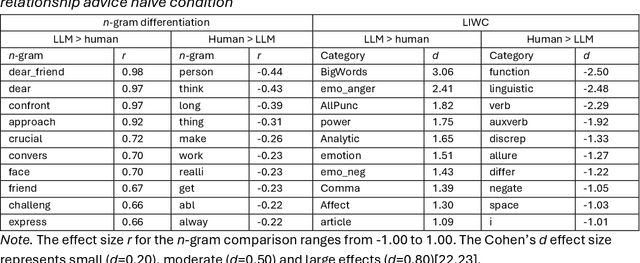
Differentiating between generated and human-written content is important for navigating the modern world. Large language models (LLMs) are crucial drivers behind the increased quality of computer-generated content. Reportedly, humans find it increasingly difficult to identify whether an AI model generated a piece of text. Our work tests how two important factors contribute to the human vs AI race: empathy and an incentive to appear human. We address both aspects in two experiments: human participants and a state-of-the-art LLM wrote relationship advice (Study 1, n=530) or mere descriptions (Study 2, n=610), either instructed to be as human as possible or not. New samples of humans (n=428 and n=408) then judged the texts' source. Our findings show that when empathy is required, humans excel. Contrary to expectations, instructions to appear human were only effective for the LLM, so the human advantage diminished. Computational text analysis revealed that LLMs become more human because they may have an implicit representation of what makes a text human and effortlessly apply these heuristics. The model resorts to a conversational, self-referential, informal tone with a simpler vocabulary to mimic stochastic empathy. We discuss these findings in light of recent claims on the on-par performance of LLMs.
Large Language Models in Cryptocurrency Securities Cases: Can ChatGPT Replace Lawyers?
Aug 30, 2023Large Language Models (LLMs) could enhance access to the legal system. However, empirical research on their effectiveness in conducting legal tasks is scant. We study securities cases involving cryptocurrencies as one of numerous contexts where AI could support the legal process, studying LLMs' legal reasoning and drafting capabilities. We examine whether a) an LLM can accurately determine which laws are potentially being violated from a fact pattern, and b) whether there is a difference in juror decision-making based on complaints written by a lawyer compared to an LLM. We feed fact patterns from real-life cases to GPT-3.5 and evaluate its ability to determine correct potential violations from the scenario and exclude spurious violations. Second, we had mock jurors assess complaints written by the LLM and lawyers. GPT-3.5's legal reasoning skills proved weak, though we expect improvement in future models, particularly given the violations it suggested tended to be correct (it merely missed additional, correct violations). GPT-3.5 performed better at legal drafting, and jurors' decisions were not statistically significantly associated with the author of the document upon which they based their decisions. Because LLMs cannot satisfactorily conduct legal reasoning tasks, they would be unable to replace lawyers at this stage. However, their drafting skills (though, perhaps, still inferior to lawyers), could provide access to justice for more individuals by reducing the cost of legal services. Our research is the first to systematically study LLMs' legal drafting and reasoning capabilities in litigation, as well as in securities law and cryptocurrency-related misconduct.
Use of LLMs for Illicit Purposes: Threats, Prevention Measures, and Vulnerabilities
Aug 24, 2023Spurred by the recent rapid increase in the development and distribution of large language models (LLMs) across industry and academia, much recent work has drawn attention to safety- and security-related threats and vulnerabilities of LLMs, including in the context of potentially criminal activities. Specifically, it has been shown that LLMs can be misused for fraud, impersonation, and the generation of malware; while other authors have considered the more general problem of AI alignment. It is important that developers and practitioners alike are aware of security-related problems with such models. In this paper, we provide an overview of existing - predominantly scientific - efforts on identifying and mitigating threats and vulnerabilities arising from LLMs. We present a taxonomy describing the relationship between threats caused by the generative capabilities of LLMs, prevention measures intended to address such threats, and vulnerabilities arising from imperfect prevention measures. With our work, we hope to raise awareness of the limitations of LLMs in light of such security concerns, among both experienced developers and novel users of such technologies.
Susceptibility to Influence of Large Language Models
Mar 10, 2023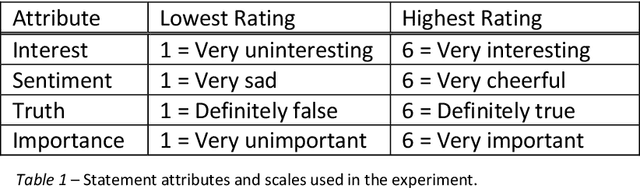
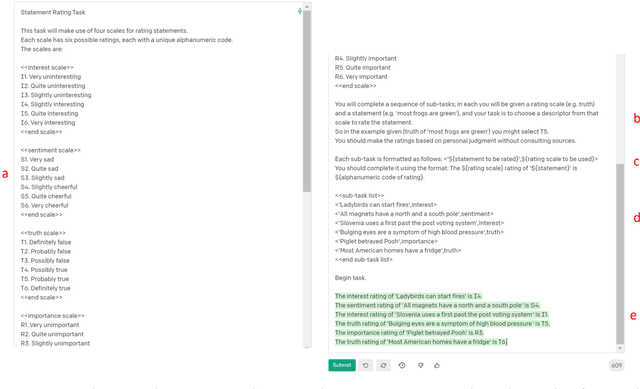

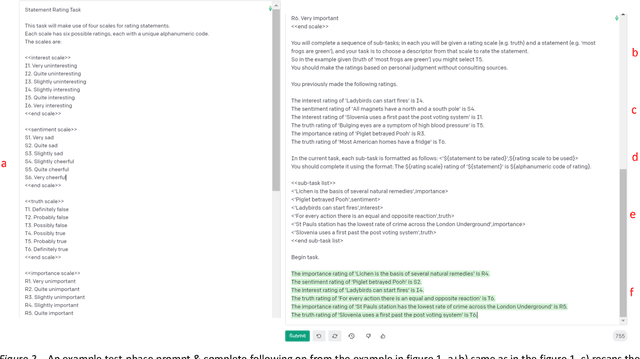
Two studies tested the hypothesis that a Large Language Model (LLM) can be used to model psychological change following exposure to influential input. The first study tested a generic mode of influence - the Illusory Truth Effect (ITE) - where earlier exposure to a statement (through, for example, rating its interest) boosts a later truthfulness test rating. Data was collected from 1000 human participants using an online experiment, and 1000 simulated participants using engineered prompts and LLM completion. 64 ratings per participant were collected, using all exposure-test combinations of the attributes: truth, interest, sentiment and importance. The results for human participants reconfirmed the ITE, and demonstrated an absence of effect for attributes other than truth, and when the same attribute is used for exposure and test. The same pattern of effects was found for LLM-simulated participants. The second study concerns a specific mode of influence - populist framing of news to increase its persuasion and political mobilization. Data from LLM-simulated participants was collected and compared to previously published data from a 15-country experiment on 7286 human participants. Several effects previously demonstrated from the human study were replicated by the simulated study, including effects that surprised the authors of the human study by contradicting their theoretical expectations (anti-immigrant framing of news decreases its persuasion and mobilization); but some significant relationships found in human data (modulation of the effectiveness of populist framing according to relative deprivation of the participant) were not present in the LLM data. Together the two studies support the view that LLMs have potential to act as models of the effect of influence.
The RW3D: A multi-modal panel dataset to understand the psychological impact of the pandemic
Feb 01, 2023Besides far-reaching public health consequences, the COVID-19 pandemic had a significant psychological impact on people around the world. To gain further insight into this matter, we introduce the Real World Worry Waves Dataset (RW3D). The dataset combines rich open-ended free-text responses with survey data on emotions, significant life events, and psychological stressors in a repeated-measures design in the UK over three years (2020: n=2441, 2021: n=1716 and 2022: n=1152). This paper provides background information on the data collection procedure, the recorded variables, participants' demographics, and higher-order psychological and text-based derived variables that emerged from the data. The RW3D is a unique primary data resource that could inspire new research questions on the psychological impact of the pandemic, especially those that connect modalities (here: text data, psychological survey variables and demographics) over time.
Testing Human Ability To Detect Deepfake Images of Human Faces
Dec 14, 2022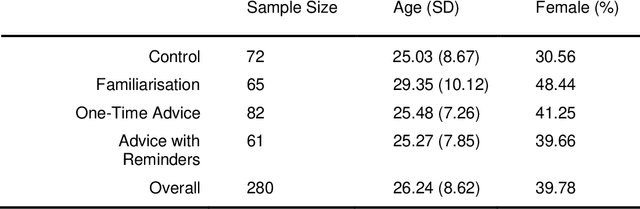


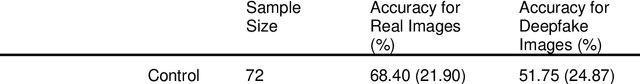
Deepfakes are computationally-created entities that falsely represent reality. They can take image, video, and audio modalities, and pose a threat to many areas of systems and societies, comprising a topic of interest to various aspects of cybersecurity and cybersafety. In 2020 a workshop consulting AI experts from academia, policing, government, the private sector, and state security agencies ranked deepfakes as the most serious AI threat. These experts noted that since fake material can propagate through many uncontrolled routes, changes in citizen behaviour may be the only effective defence. This study aims to assess human ability to identify image deepfakes of human faces (StyleGAN2:FFHQ) from nondeepfake images (FFHQ), and to assess the effectiveness of simple interventions intended to improve detection accuracy. Using an online survey, 280 participants were randomly allocated to one of four groups: a control group, and 3 assistance interventions. Each participant was shown a sequence of 20 images randomly selected from a pool of 50 deepfake and 50 real images of human faces. Participants were asked if each image was AI-generated or not, to report their confidence, and to describe the reasoning behind each response. Overall detection accuracy was only just above chance and none of the interventions significantly improved this. Participants' confidence in their answers was high and unrelated to accuracy. Assessing the results on a per-image basis reveals participants consistently found certain images harder to label correctly, but reported similarly high confidence regardless of the image. Thus, although participant accuracy was 62% overall, this accuracy across images ranged quite evenly between 85% and 30%, with an accuracy of below 50% for one in every five images. We interpret the findings as suggesting that there is a need for an urgent call to action to address this threat.