 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding the limitations of self-supervised learning for tabular anomaly detection
Oct 02, 2023While self-supervised learning has improved anomaly detection in computer vision and natural language processing, it is unclear whether tabular data can benefit from it. This paper explores the limitations of self-supervision for tabular anomaly detection. We conduct several experiments spanning various pretext tasks on 26 benchmark datasets to understand why this is the case. Our results confirm representations derived from self-supervision do not improve tabular anomaly detection performance compared to using the raw representations of the data. We show this is due to neural networks introducing irrelevant features, which reduces the effectiveness of anomaly detectors. However, we demonstrate that using a subspace of the neural network's representation can recover performance.
Large Language Models in Cryptocurrency Securities Cases: Can ChatGPT Replace Lawyers?
Aug 30, 2023Large Language Models (LLMs) could enhance access to the legal system. However, empirical research on their effectiveness in conducting legal tasks is scant. We study securities cases involving cryptocurrencies as one of numerous contexts where AI could support the legal process, studying LLMs' legal reasoning and drafting capabilities. We examine whether a) an LLM can accurately determine which laws are potentially being violated from a fact pattern, and b) whether there is a difference in juror decision-making based on complaints written by a lawyer compared to an LLM. We feed fact patterns from real-life cases to GPT-3.5 and evaluate its ability to determine correct potential violations from the scenario and exclude spurious violations. Second, we had mock jurors assess complaints written by the LLM and lawyers. GPT-3.5's legal reasoning skills proved weak, though we expect improvement in future models, particularly given the violations it suggested tended to be correct (it merely missed additional, correct violations). GPT-3.5 performed better at legal drafting, and jurors' decisions were not statistically significantly associated with the author of the document upon which they based their decisions. Because LLMs cannot satisfactorily conduct legal reasoning tasks, they would be unable to replace lawyers at this stage. However, their drafting skills (though, perhaps, still inferior to lawyers), could provide access to justice for more individuals by reducing the cost of legal services. Our research is the first to systematically study LLMs' legal drafting and reasoning capabilities in litigation, as well as in securities law and cryptocurrency-related misconduct.
Warning: Humans Cannot Reliably Detect Speech Deepfakes
Jan 19, 2023



Speech deepfakes are artificial voices generated by machine learning models. Previous literature has highlighted deepfakes as one of the biggest threats to security arising from progress in AI due to their potential for misuse. However, studies investigating human detection capabilities are limited. We presented genuine and deepfake audio to $n$ = 529 individuals and asked them to identify the deepfakes. We ran our experiments in English and Mandarin to understand if language affects detection performance and decision-making rationale. Detection capability is unreliable. Listeners only correctly spotted the deepfakes 73% of the time, and there was no difference in detectability between the two languages. Increasing listener awareness by providing examples of speech deepfakes only improves results slightly. The difficulty of detecting speech deepfakes confirms their potential for misuse and signals that defenses against this threat are needed.
Textwash -- automated open-source text anonymisation
Aug 27, 2022
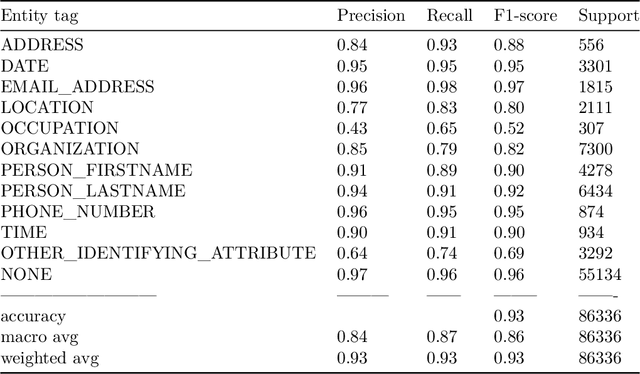
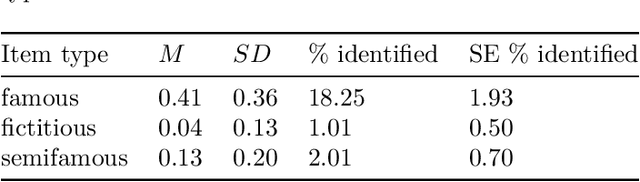
The increased use of text data in social science research has benefited from easy-to-access data (e.g., Twitter). That trend comes at the cost of research requiring sensitive but hard-to-share data (e.g., interview data, police reports, electronic health records). We introduce a solution to that stalemate with the open-source text anonymisation software_Textwash_. This paper presents the empirical evaluation of the tool using the TILD criteria: a technical evaluation (how accurate is the tool?), an information loss evaluation (how much information is lost in the anonymisation process?) and a de-anonymisation test (can humans identify individuals from anonymised text data?). The findings suggest that Textwash performs similar to state-of-the-art entity recognition models and introduces a negligible information loss of 0.84%. For the de-anonymisation test, we tasked humans to identify individuals by name from a dataset of crowdsourced person descriptions of very famous, semi-famous and non-existing individuals. The de-anonymisation rate ranged from 1.01-2.01% for the realistic use cases of the tool. We replicated the findings in a second study and concluded that Textwash succeeds in removing potentially sensitive information that renders detailed person descriptions practically anonymous.
Self-Supervised Losses for One-Class Textual Anomaly Detection
Apr 12, 2022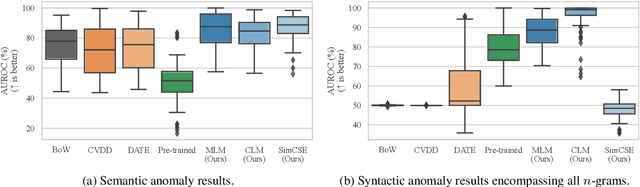
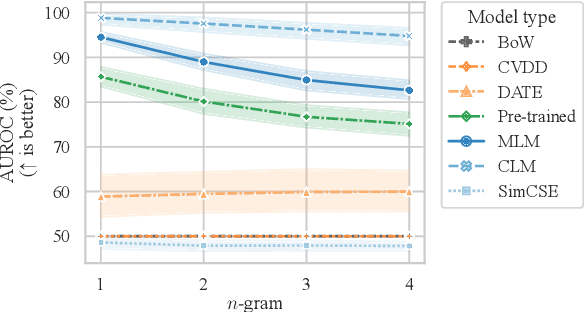
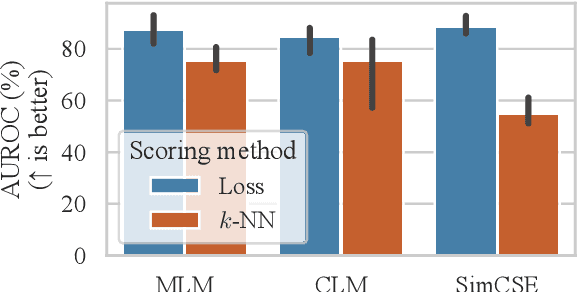
Current deep learning methods for anomaly detection in text rely on supervisory signals in inliers that may be unobtainable or bespoke architectures that are difficult to tune. We study a simpler alternative: fine-tuning Transformers on the inlier data with self-supervised objectives and using the losses as an anomaly score. Overall, the self-supervision approach outperforms other methods under various anomaly detection scenarios, improving the AUROC score on semantic anomalies by 11.6% and on syntactic anomalies by 22.8% on average. Additionally, the optimal objective and resultant learnt representation depend on the type of downstream anomaly. The separability of anomalies and inliers signals that a representation is more effective for detecting semantic anomalies, whilst the presence of narrow feature directions signals a representation that is effective for detecting syntactic anomalies.
Detecting DeFi Securities Violations from Token Smart Contract Code with Random Forest Classification
Dec 06, 2021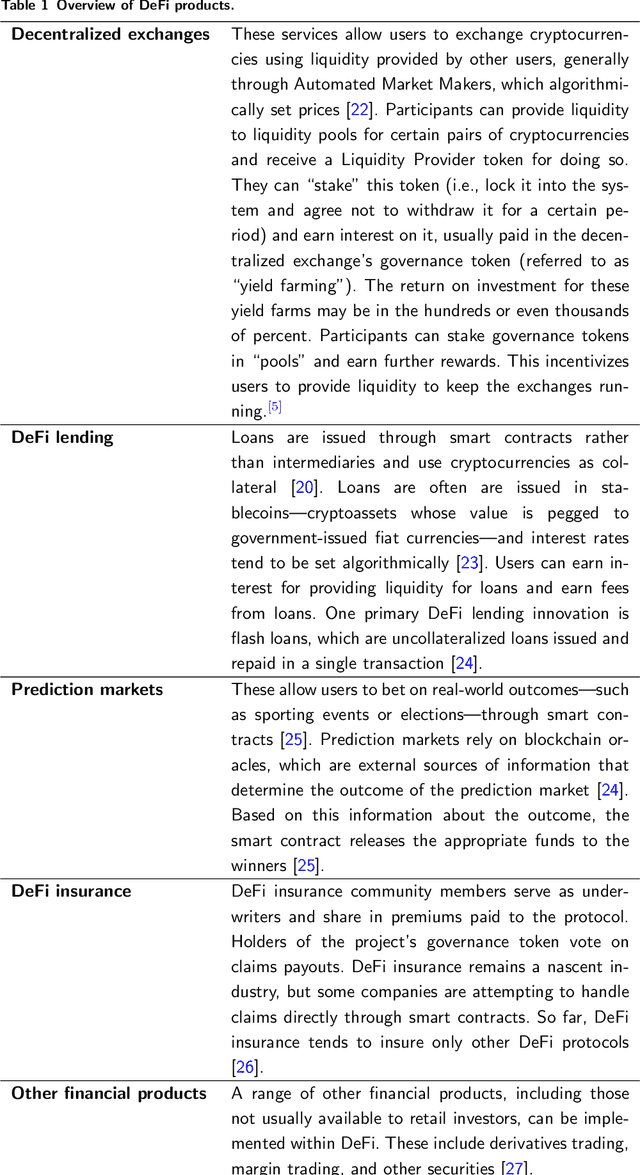


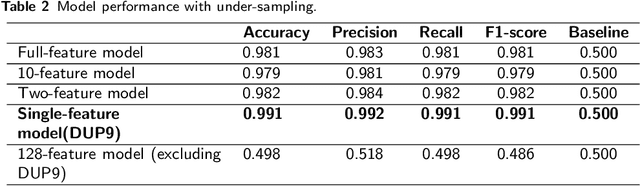
Decentralized Finance (DeFi) is a system of financial products and services built and delivered through smart contracts on various blockchains. In the past year, DeFi has gained popularity and market capitalization. However, it has also become an epicenter of cryptocurrency-related crime, in particular, various types of securities violations. The lack of Know Your Customer requirements in DeFi has left governments unsure of how to handle the magnitude of offending in this space. This study aims to address this problem with a machine learning approach to identify DeFi projects potentially engaging in securities violations based on their tokens' smart contract code. We adapt prior work on detecting specific types of securities violations across Ethereum more broadly, building a random forest classifier based on features extracted from DeFi projects' tokens' smart contract code. The final classifier achieves a 99.1% F1-score. Such high performance is surprising for any classification problem, however, from further feature-level, we find a single feature makes this a highly detectable problem. Another contribution of our study is a new dataset, comprised of (a) a verified ground truth dataset for tokens involved in securities violations and (b) a set of valid tokens from a DeFi aggregator which conducts due diligence on the projects it lists. This paper further discusses the use of our model by prosecutors in enforcement efforts and connects its potential use to the wider legal context.
Brittle Features May Help Anomaly Detection
Apr 21, 2021
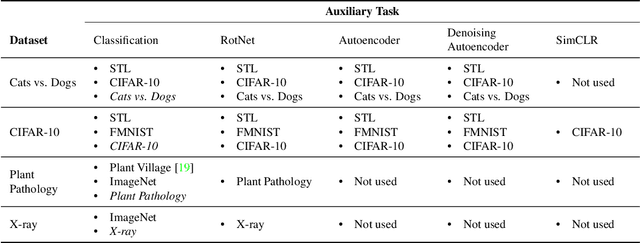
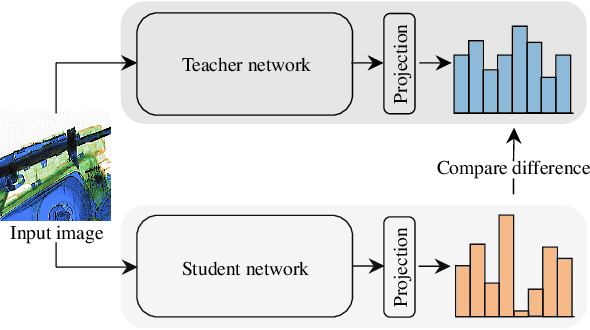
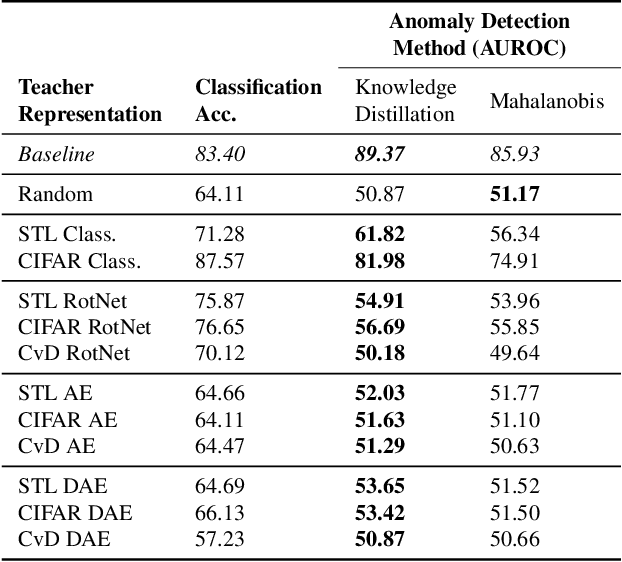
One-class anomaly detection is challenging. A representation that clearly distinguishes anomalies from normal data is ideal, but arriving at this representation is difficult since only normal data is available at training time. We examine the performance of representations, transferred from auxiliary tasks, for anomaly detection. Our results suggest that the choice of representation is more important than the anomaly detector used with these representations, although knowledge distillation can work better than using the representations directly. In addition, separability between anomalies and normal data is important but not the sole factor for a good representation, as anomaly detection performance is also correlated with more adversarially brittle features in the representation space. Finally, we show our configuration can detect 96.4% of anomalies in a genuine X-ray security dataset, outperforming previous results.
Probabilistic map-matching using particle filters
Nov 29, 2016



Increasing availability of vehicle GPS data has created potentially transformative opportunities for traffic management, route planning and other location-based services. Critical to the utility of the data is their accuracy. Map-matching is the process of improving the accuracy by aligning GPS data with the road network. In this paper, we propose a purely probabilistic approach to map-matching based on a sequential Monte Carlo algorithm known as particle filters. The approach performs map-matching by producing a range of candidate solutions, each with an associated probability score. We outline implementation details and thoroughly validate the technique on GPS data of varied quality.