 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Cultural Adaptability of a Large Language Model via Simulation of Synthetic Personas
Aug 13, 2024
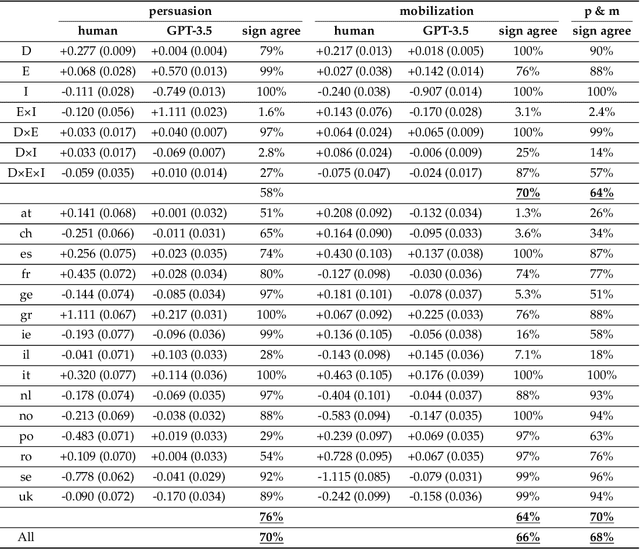


The success of Large Language Models (LLMs) in multicultural environments hinges on their ability to understand users' diverse cultural backgrounds. We measure this capability by having an LLM simulate human profiles representing various nationalities within the scope of a questionnaire-style psychological experiment. Specifically, we employ GPT-3.5 to reproduce reactions to persuasive news articles of 7,286 participants from 15 countries; comparing the results with a dataset of real participants sharing the same demographic traits. Our analysis shows that specifying a person's country of residence improves GPT-3.5's alignment with their responses. In contrast, using native language prompting introduces shifts that significantly reduce overall alignment, with some languages particularly impairing performance. These findings suggest that while direct nationality information enhances the model's cultural adaptability, native language cues do not reliably improve simulation fidelity and can detract from the model's effectiveness.
Understanding the limitations of self-supervised learning for tabular anomaly detection
Oct 02, 2023While self-supervised learning has improved anomaly detection in computer vision and natural language processing, it is unclear whether tabular data can benefit from it. This paper explores the limitations of self-supervision for tabular anomaly detection. We conduct several experiments spanning various pretext tasks on 26 benchmark datasets to understand why this is the case. Our results confirm representations derived from self-supervision do not improve tabular anomaly detection performance compared to using the raw representations of the data. We show this is due to neural networks introducing irrelevant features, which reduces the effectiveness of anomaly detectors. However, we demonstrate that using a subspace of the neural network's representation can recover performance.
Use of LLMs for Illicit Purposes: Threats, Prevention Measures, and Vulnerabilities
Aug 24, 2023Spurred by the recent rapid increase in the development and distribution of large language models (LLMs) across industry and academia, much recent work has drawn attention to safety- and security-related threats and vulnerabilities of LLMs, including in the context of potentially criminal activities. Specifically, it has been shown that LLMs can be misused for fraud, impersonation, and the generation of malware; while other authors have considered the more general problem of AI alignment. It is important that developers and practitioners alike are aware of security-related problems with such models. In this paper, we provide an overview of existing - predominantly scientific - efforts on identifying and mitigating threats and vulnerabilities arising from LLMs. We present a taxonomy describing the relationship between threats caused by the generative capabilities of LLMs, prevention measures intended to address such threats, and vulnerabilities arising from imperfect prevention measures. With our work, we hope to raise awareness of the limitations of LLMs in light of such security concerns, among both experienced developers and novel users of such technologies.
Warning: Humans Cannot Reliably Detect Speech Deepfakes
Jan 19, 2023



Speech deepfakes are artificial voices generated by machine learning models. Previous literature has highlighted deepfakes as one of the biggest threats to security arising from progress in AI due to their potential for misuse. However, studies investigating human detection capabilities are limited. We presented genuine and deepfake audio to $n$ = 529 individuals and asked them to identify the deepfakes. We ran our experiments in English and Mandarin to understand if language affects detection performance and decision-making rationale. Detection capability is unreliable. Listeners only correctly spotted the deepfakes 73% of the time, and there was no difference in detectability between the two languages. Increasing listener awareness by providing examples of speech deepfakes only improves results slightly. The difficulty of detecting speech deepfakes confirms their potential for misuse and signals that defenses against this threat are needed.
A Simple Approach for State-Action Abstraction using a Learned MDP Homomorphism
Sep 14, 2022
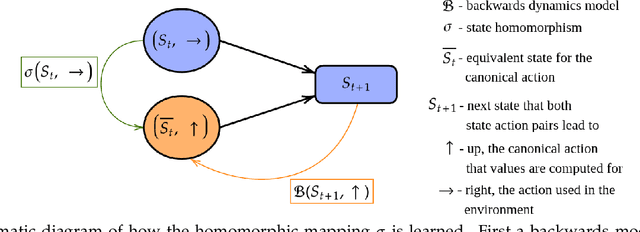
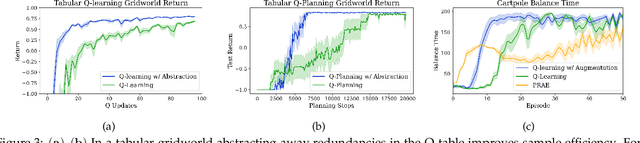
Animals are able to rapidly infer from limited experience when sets of state action pairs have equivalent reward and transition dynamics. On the other hand, modern reinforcement learning systems must painstakingly learn through trial and error that sets of state action pairs are value equivalent -- requiring an often prohibitively large amount of samples from their environment. MDP homomorphisms have been proposed that reduce the observed MDP of an environment to an abstract MDP, which can enable more sample efficient policy learning. Consequently, impressive improvements in sample efficiency have been achieved when a suitable MDP homomorphism can be constructed a priori -- usually by exploiting a practioner's knowledge of environment symmetries. We propose a novel approach to constructing a homomorphism in discrete action spaces, which uses a partial model of environment dynamics to infer which state action pairs lead to the same state -- reducing the size of the state-action space by a factor equal to the cardinality of the action space. We call this method equivalent effect abstraction. In a gridworld setting, we demonstrate empirically that equivalent effect abstraction can improve sample efficiency in a model-free setting and planning efficiency for modelbased approaches. Furthermore, we show on cartpole that our approach outperforms an existing method for learning homomorphisms, while using 33x less training data.
Self-Supervised Losses for One-Class Textual Anomaly Detection
Apr 12, 2022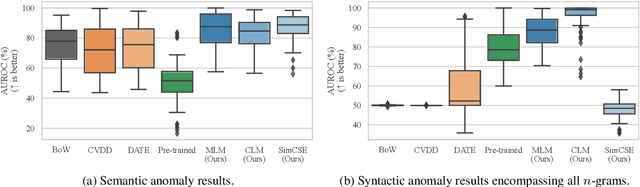
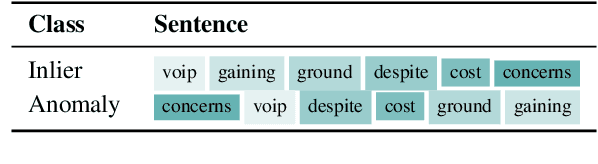
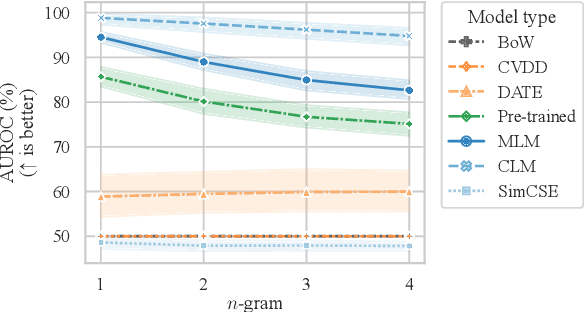
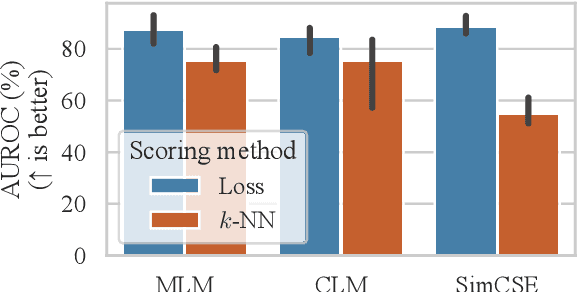
Current deep learning methods for anomaly detection in text rely on supervisory signals in inliers that may be unobtainable or bespoke architectures that are difficult to tune. We study a simpler alternative: fine-tuning Transformers on the inlier data with self-supervised objectives and using the losses as an anomaly score. Overall, the self-supervision approach outperforms other methods under various anomaly detection scenarios, improving the AUROC score on semantic anomalies by 11.6% and on syntactic anomalies by 22.8% on average. Additionally, the optimal objective and resultant learnt representation depend on the type of downstream anomaly. The separability of anomalies and inliers signals that a representation is more effective for detecting semantic anomalies, whilst the presence of narrow feature directions signals a representation that is effective for detecting syntactic anomalies.
Contrasting Human- and Machine-Generated Word-Level Adversarial Examples for Text Classification
Sep 09, 2021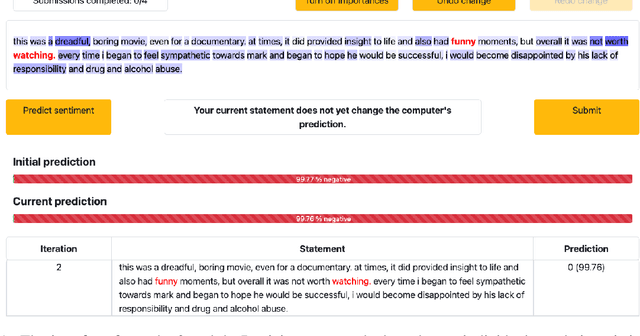
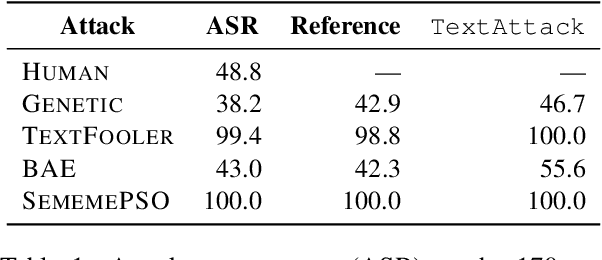
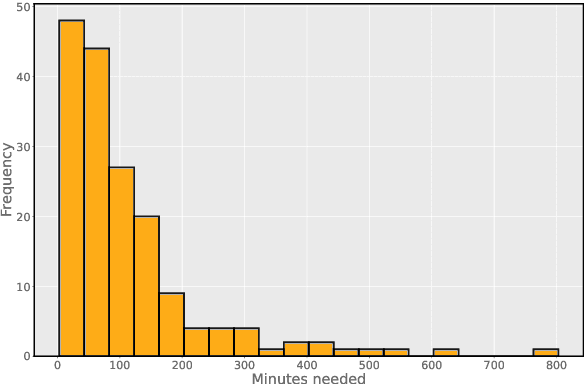
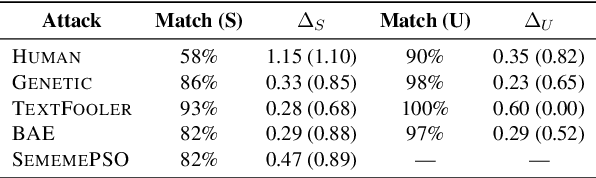
Research shows that natural language processing models are generally considered to be vulnerable to adversarial attacks; but recent work has drawn attention to the issue of validating these adversarial inputs against certain criteria (e.g., the preservation of semantics and grammaticality). Enforcing constraints to uphold such criteria may render attacks unsuccessful, raising the question of whether valid attacks are actually feasible. In this work, we investigate this through the lens of human language ability. We report on crowdsourcing studies in which we task humans with iteratively modifying words in an input text, while receiving immediate model feedback, with the aim of causing a sentiment classification model to misclassify the example. Our findings suggest that humans are capable of generating a substantial amount of adversarial examples using semantics-preserving word substitutions. We analyze how human-generated adversarial examples compare to the recently proposed TextFooler, Genetic, BAE and SememePSO attack algorithms on the dimensions naturalness, preservation of sentiment, grammaticality and substitution rate. Our findings suggest that human-generated adversarial examples are not more able than the best algorithms to generate natural-reading, sentiment-preserving examples, though they do so by being much more computationally efficient.
Brittle Features May Help Anomaly Detection
Apr 21, 2021
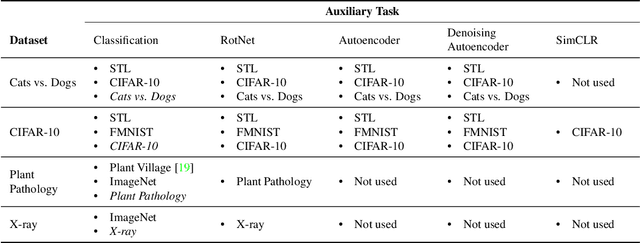
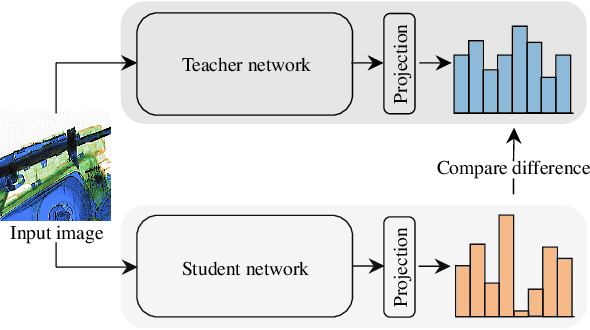
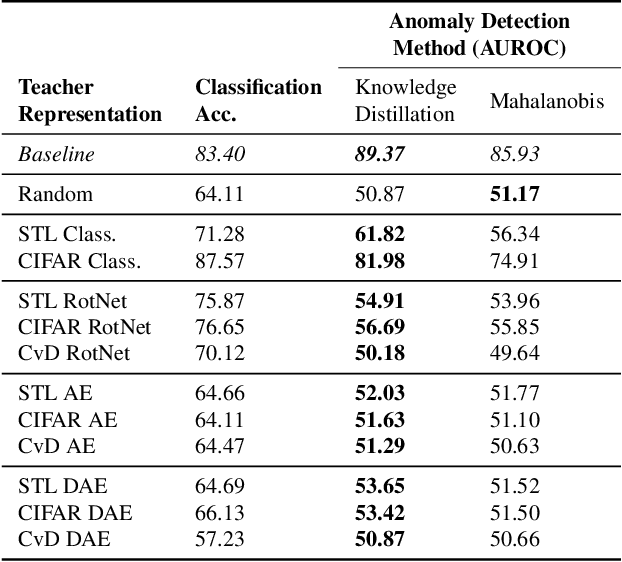
One-class anomaly detection is challenging. A representation that clearly distinguishes anomalies from normal data is ideal, but arriving at this representation is difficult since only normal data is available at training time. We examine the performance of representations, transferred from auxiliary tasks, for anomaly detection. Our results suggest that the choice of representation is more important than the anomaly detector used with these representations, although knowledge distillation can work better than using the representations directly. In addition, separability between anomalies and normal data is important but not the sole factor for a good representation, as anomaly detection performance is also correlated with more adversarially brittle features in the representation space. Finally, we show our configuration can detect 96.4% of anomalies in a genuine X-ray security dataset, outperforming previous results.
Escaping Stochastic Traps with Aleatoric Mapping Agents
Feb 08, 2021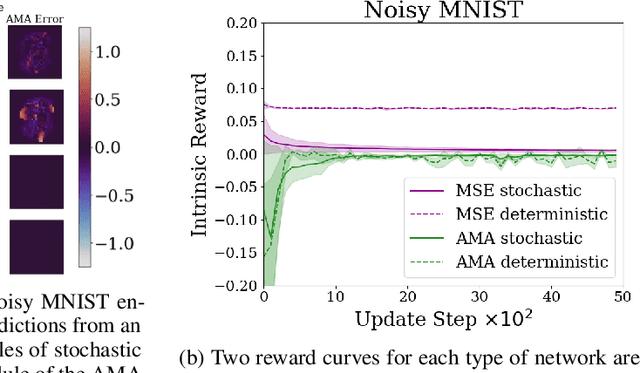

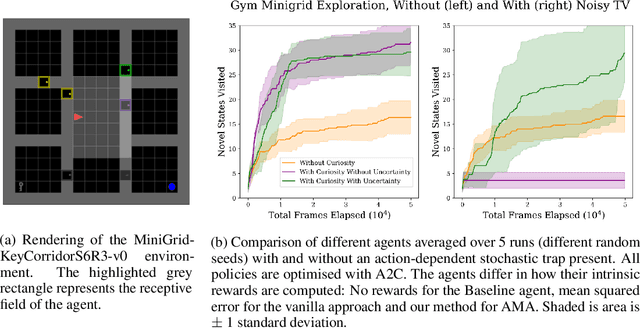
Exploration in environments with sparse rewards is difficult for artificial agents. Curiosity driven learning -- using feed-forward prediction errors as intrinsic rewards -- has achieved some success in these scenarios, but fails when faced with action-dependent noise sources. We present aleatoric mapping agents (AMAs), a neuroscience inspired solution modeled on the cholinergic system of the mammalian brain. AMAs aim to explicitly ascertain which dynamics of the environment are unpredictable, regardless of whether those dynamics are induced by the actions of the agent. This is achieved by generating separate forward predictions for the mean and variance of future states and reducing intrinsic rewards for those transitions with high aleatoric variance. We show AMAs are able to effectively circumvent action-dependent stochastic traps that immobilise conventional curiosity driven agents. The code for all experiments presented in this paper is open sourced: http://github.com/self-supervisor/Escaping-Stochastic-Traps-With-Aleatoric-Mapping-Agents.
Frequency-Guided Word Substitutions for Detecting Textual Adversarial Examples
Apr 13, 2020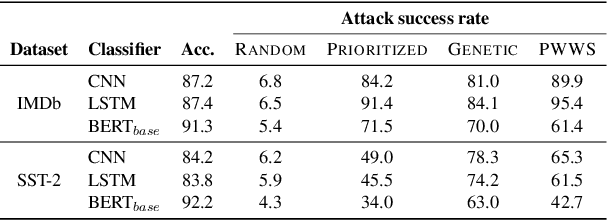

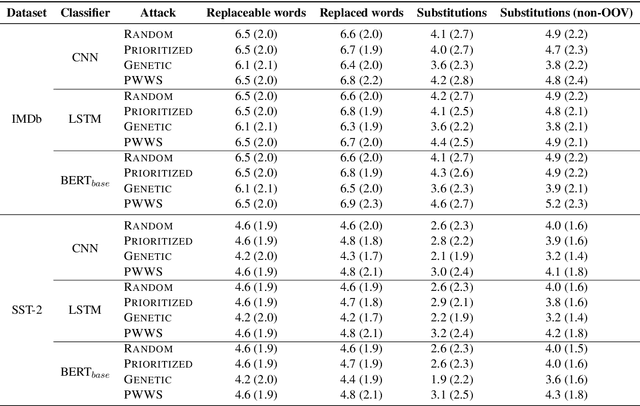
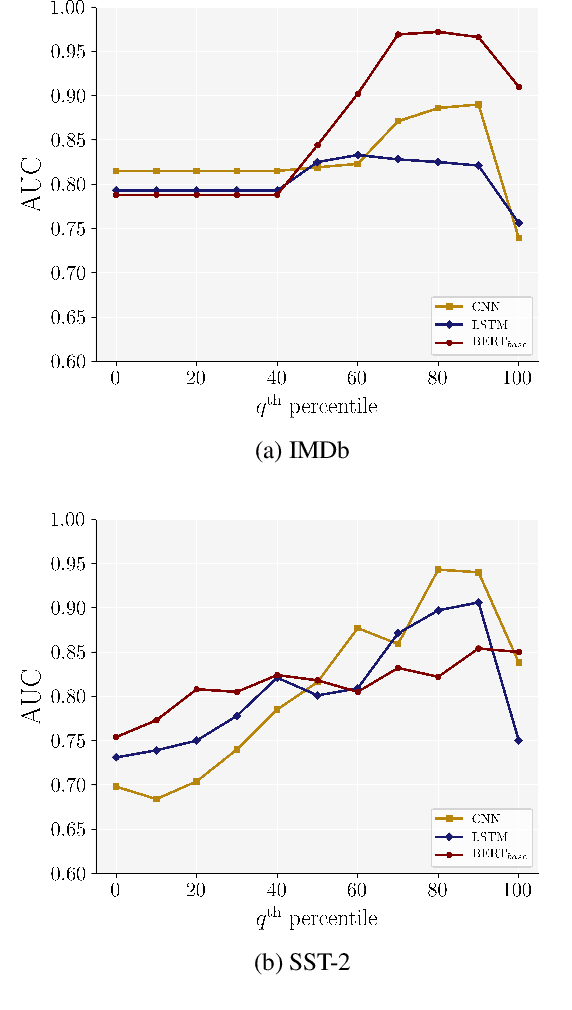
While recent efforts have shown that neural text processing models are vulnerable to adversarial examples, comparatively little attention has been paid to explicitly characterize their effectiveness. To overcome this, we present analytical insights into the word frequency characteristics of word-level adversarial examples for neural text classification models. We show that adversarial attacks against CNN-, LSTM- and Transformer-based classification models perform token substitutions that are identifiable through word frequency differences between replaced words and their substitutions. Based on these findings, we propose frequency-guided word substitutions (FGWS) as a simple algorithm for the automatic detection of adversarially perturbed textual sequences. FGWS exploits the word frequency properties of adversarial word substitutions, and we assess its suitability for the automatic detection of adversarial examples generated from the SST-2 and IMDb sentiment datasets. Our method provides promising results by accurately detecting adversarial examples, with $F_1$ detection scores of up to 93.7% on adversarial examples against BERT-based classification models. We compare our approach against baseline detection approaches as well as a recently proposed perturbation discrimination framework, and show that we outperform existing approaches by up to 15.1% $F_1$ in our experiments.