 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Cultural Adaptability of a Large Language Model via Simulation of Synthetic Personas
Paper and Code

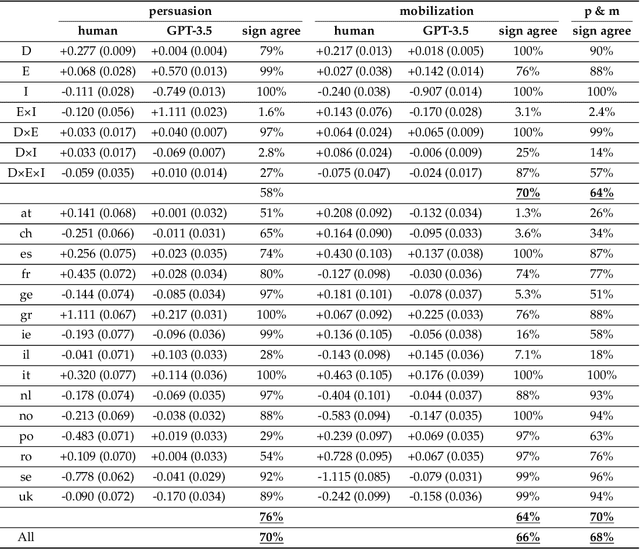


The success of Large Language Models (LLMs) in multicultural environments hinges on their ability to understand users' diverse cultural backgrounds. We measure this capability by having an LLM simulate human profiles representing various nationalities within the scope of a questionnaire-style psychological experiment. Specifically, we employ GPT-3.5 to reproduce reactions to persuasive news articles of 7,286 participants from 15 countries; comparing the results with a dataset of real participants sharing the same demographic traits. Our analysis shows that specifying a person's country of residence improves GPT-3.5's alignment with their responses. In contrast, using native language prompting introduces shifts that significantly reduce overall alignment, with some languages particularly impairing performance. These findings suggest that while direct nationality information enhances the model's cultural adaptability, native language cues do not reliably improve simulation fidelity and can detract from the model's effectiveness.