 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDataset Featurization: Uncovering Natural Language Features through Unsupervised Data Reconstruction
Feb 24, 2025Interpreting data is central to modern research. Large language models (LLMs) show promise in providing such natural language interpretations of data, yet simple feature extraction methods such as prompting often fail to produce accurate and versatile descriptions for diverse datasets and lack control over granularity and scale. To address these limitations, we propose a domain-agnostic method for dataset featurization that provides precise control over the number of features extracted while maintaining compact and descriptive representations comparable to human expert labeling. Our method optimizes the selection of informative binary features by evaluating the ability of an LLM to reconstruct the original data using those features. We demonstrate its effectiveness in dataset modeling tasks and through two case studies: (1) Constructing a feature representation of jailbreak tactics that compactly captures both the effectiveness and diversity of a larger set of human-crafted attacks; and (2) automating the discovery of features that align with human preferences, achieving accuracy and robustness comparable to expert-crafted features. Moreover, we show that the pipeline scales effectively, improving as additional features are sampled, making it suitable for large and diverse datasets.
Rethinking AI Cultural Evaluation
Jan 13, 2025
As AI systems become more integrated into society, evaluating their capacity to align with diverse cultural values is crucial for their responsible deployment. Current evaluation methods predominantly rely on multiple-choice question (MCQ) datasets. In this study, we demonstrate that MCQs are insufficient for capturing the complexity of cultural values expressed in open-ended scenarios. Our findings highlight significant discrepancies between MCQ-based assessments and the values conveyed in unconstrained interactions. Based on these findings, we recommend moving beyond MCQs to adopt more open-ended, context-specific assessments that better reflect how AI models engage with cultural values in realistic settings.
Evaluating Cultural Adaptability of a Large Language Model via Simulation of Synthetic Personas
Aug 13, 2024
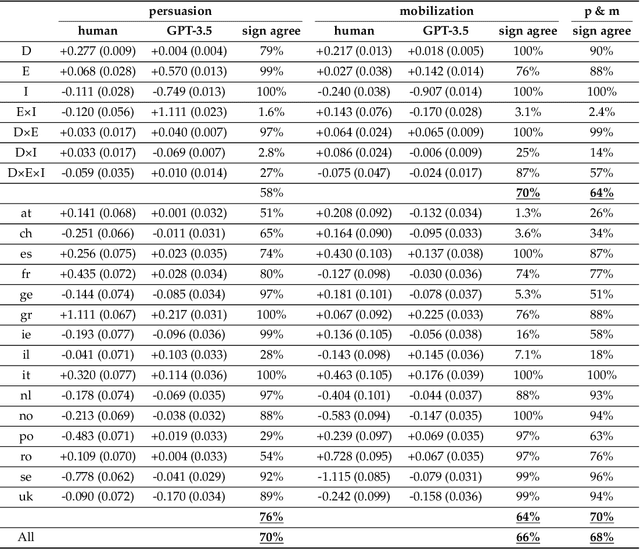


The success of Large Language Models (LLMs) in multicultural environments hinges on their ability to understand users' diverse cultural backgrounds. We measure this capability by having an LLM simulate human profiles representing various nationalities within the scope of a questionnaire-style psychological experiment. Specifically, we employ GPT-3.5 to reproduce reactions to persuasive news articles of 7,286 participants from 15 countries; comparing the results with a dataset of real participants sharing the same demographic traits. Our analysis shows that specifying a person's country of residence improves GPT-3.5's alignment with their responses. In contrast, using native language prompting introduces shifts that significantly reduce overall alignment, with some languages particularly impairing performance. These findings suggest that while direct nationality information enhances the model's cultural adaptability, native language cues do not reliably improve simulation fidelity and can detract from the model's effectiveness.