 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBrittle Features May Help Anomaly Detection
Paper and Code

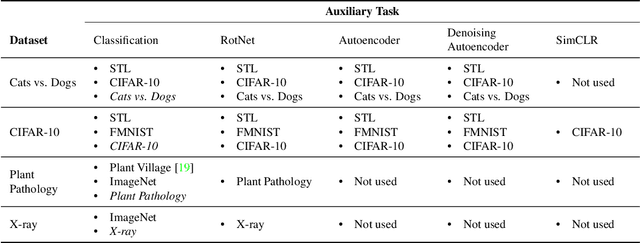
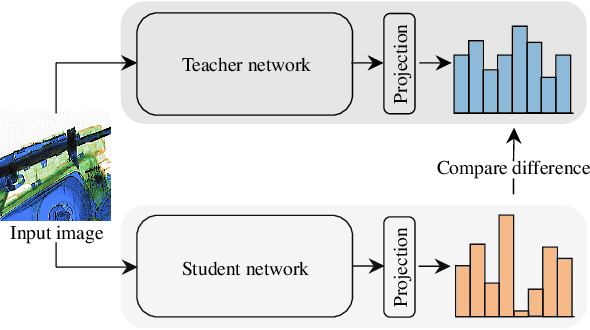
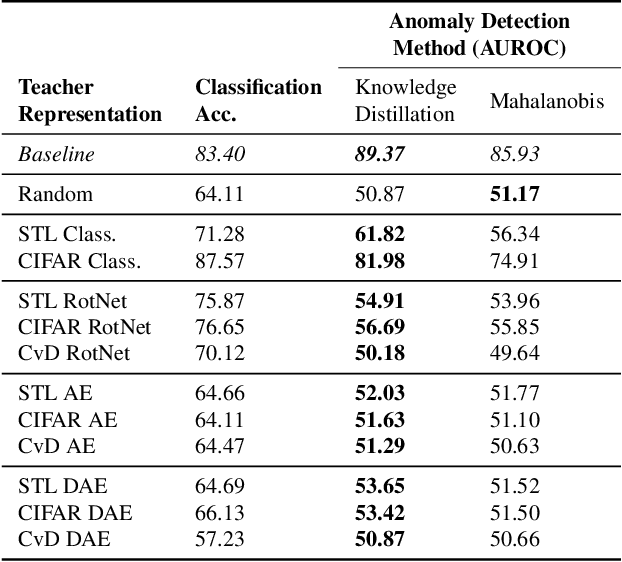
One-class anomaly detection is challenging. A representation that clearly distinguishes anomalies from normal data is ideal, but arriving at this representation is difficult since only normal data is available at training time. We examine the performance of representations, transferred from auxiliary tasks, for anomaly detection. Our results suggest that the choice of representation is more important than the anomaly detector used with these representations, although knowledge distillation can work better than using the representations directly. In addition, separability between anomalies and normal data is important but not the sole factor for a good representation, as anomaly detection performance is also correlated with more adversarially brittle features in the representation space. Finally, we show our configuration can detect 96.4% of anomalies in a genuine X-ray security dataset, outperforming previous results.