 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWarning: Humans Cannot Reliably Detect Speech Deepfakes
Jan 19, 2023



Speech deepfakes are artificial voices generated by machine learning models. Previous literature has highlighted deepfakes as one of the biggest threats to security arising from progress in AI due to their potential for misuse. However, studies investigating human detection capabilities are limited. We presented genuine and deepfake audio to $n$ = 529 individuals and asked them to identify the deepfakes. We ran our experiments in English and Mandarin to understand if language affects detection performance and decision-making rationale. Detection capability is unreliable. Listeners only correctly spotted the deepfakes 73% of the time, and there was no difference in detectability between the two languages. Increasing listener awareness by providing examples of speech deepfakes only improves results slightly. The difficulty of detecting speech deepfakes confirms their potential for misuse and signals that defenses against this threat are needed.
Testing Human Ability To Detect Deepfake Images of Human Faces
Dec 14, 2022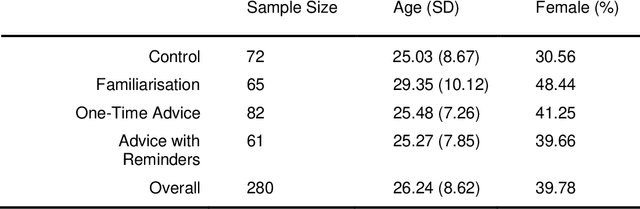


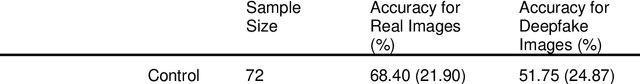
Deepfakes are computationally-created entities that falsely represent reality. They can take image, video, and audio modalities, and pose a threat to many areas of systems and societies, comprising a topic of interest to various aspects of cybersecurity and cybersafety. In 2020 a workshop consulting AI experts from academia, policing, government, the private sector, and state security agencies ranked deepfakes as the most serious AI threat. These experts noted that since fake material can propagate through many uncontrolled routes, changes in citizen behaviour may be the only effective defence. This study aims to assess human ability to identify image deepfakes of human faces (StyleGAN2:FFHQ) from nondeepfake images (FFHQ), and to assess the effectiveness of simple interventions intended to improve detection accuracy. Using an online survey, 280 participants were randomly allocated to one of four groups: a control group, and 3 assistance interventions. Each participant was shown a sequence of 20 images randomly selected from a pool of 50 deepfake and 50 real images of human faces. Participants were asked if each image was AI-generated or not, to report their confidence, and to describe the reasoning behind each response. Overall detection accuracy was only just above chance and none of the interventions significantly improved this. Participants' confidence in their answers was high and unrelated to accuracy. Assessing the results on a per-image basis reveals participants consistently found certain images harder to label correctly, but reported similarly high confidence regardless of the image. Thus, although participant accuracy was 62% overall, this accuracy across images ranged quite evenly between 85% and 30%, with an accuracy of below 50% for one in every five images. We interpret the findings as suggesting that there is a need for an urgent call to action to address this threat.