 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrequency and Generalisation of Periodic Activation Functions in Reinforcement Learning
Jul 09, 2024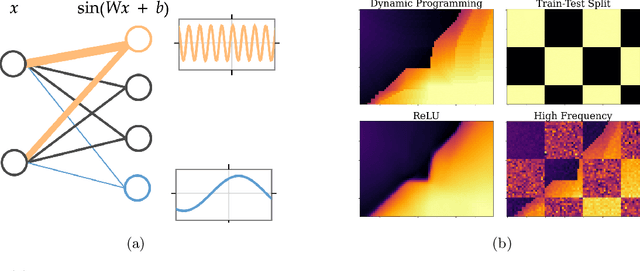

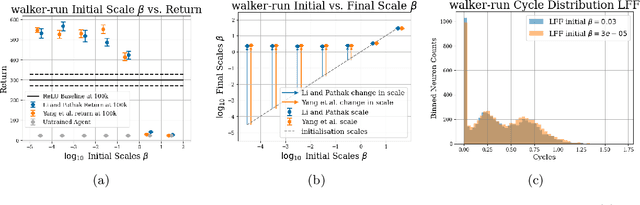

Periodic activation functions, often referred to as learned Fourier features have been widely demonstrated to improve sample efficiency and stability in a variety of deep RL algorithms. Potentially incompatible hypotheses have been made about the source of these improvements. One is that periodic activations learn low frequency representations and as a result avoid overfitting to bootstrapped targets. Another is that periodic activations learn high frequency representations that are more expressive, allowing networks to quickly fit complex value functions. We analyse these claims empirically, finding that periodic representations consistently converge to high frequencies regardless of their initialisation frequency. We also find that while periodic activation functions improve sample efficiency, they exhibit worse generalization on states with added observation noise -- especially when compared to otherwise equivalent networks with ReLU activation functions. Finally, we show that weight decay regularization is able to partially offset the overfitting of periodic activation functions, delivering value functions that learn quickly while also generalizing.
Predictive representations: building blocks of intelligence
Feb 09, 2024Adaptive behavior often requires predicting future events. The theory of reinforcement learning prescribes what kinds of predictive representations are useful and how to compute them. This paper integrates these theoretical ideas with work on cognition and neuroscience. We pay special attention to the successor representation (SR) and its generalizations, which have been widely applied both as engineering tools and models of brain function. This convergence suggests that particular kinds of predictive representations may function as versatile building blocks of intelligence.
Probing neural representations of scene perception in a hippocampally dependent task using artificial neural networks
Mar 11, 2023



Deep artificial neural networks (DNNs) trained through backpropagation provide effective models of the mammalian visual system, accurately capturing the hierarchy of neural responses through primary visual cortex to inferior temporal cortex (IT). However, the ability of these networks to explain representations in higher cortical areas is relatively lacking and considerably less well researched. For example, DNNs have been less successful as a model of the egocentric to allocentric transformation embodied by circuits in retrosplenial and posterior parietal cortex. We describe a novel scene perception benchmark inspired by a hippocampal dependent task, designed to probe the ability of DNNs to transform scenes viewed from different egocentric perspectives. Using a network architecture inspired by the connectivity between temporal lobe structures and the hippocampus, we demonstrate that DNNs trained using a triplet loss can learn this task. Moreover, by enforcing a factorized latent space, we can split information propagation into "what" and "where" pathways, which we use to reconstruct the input. This allows us to beat the state-of-the-art for unsupervised object segmentation on the CATER and MOVi-A,B,C benchmarks.
Functional Connectome: Approximating Brain Networks with Artificial Neural Networks
Nov 23, 2022
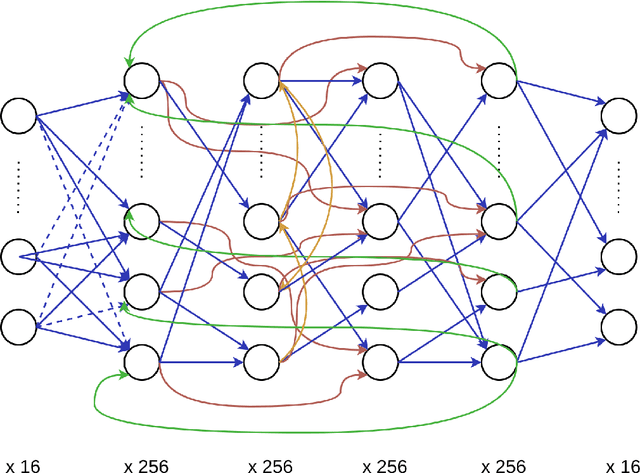


We aimed to explore the capability of deep learning to approximate the function instantiated by biological neural circuits-the functional connectome. Using deep neural networks, we performed supervised learning with firing rate observations drawn from synthetically constructed neural circuits, as well as from an empirically supported Boundary Vector Cell-Place Cell network. The performance of trained networks was quantified using a range of criteria and tasks. Our results show that deep neural networks were able to capture the computations performed by synthetic biological networks with high accuracy, and were highly data efficient and robust to biological plasticity. We show that trained deep neural networks are able to perform zero-shot generalisation in novel environments, and allows for a wealth of tasks such as decoding the animal's location in space with high accuracy. Our study reveals a novel and promising direction in systems neuroscience, and can be expanded upon with a multitude of downstream applications, for example, goal-directed reinforcement learning.
Temporally Extended Successor Representations
Sep 25, 2022
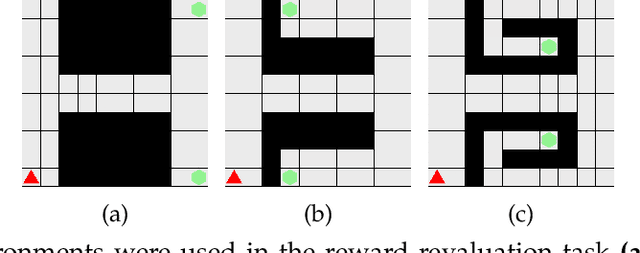
We present a temporally extended variation of the successor representation, which we term t-SR. t-SR captures the expected state transition dynamics of temporally extended actions by constructing successor representations over primitive action repeats. This form of temporal abstraction does not learn a top-down hierarchy of pertinent task structures, but rather a bottom-up composition of coupled actions and action repetitions. This lessens the amount of decisions required in control without learning a hierarchical policy. As such, t-SR directly considers the time horizon of temporally extended action sequences without the need for predefined or domain-specific options. We show that in environments with dynamic reward structure, t-SR is able to leverage both the flexibility of the successor representation and the abstraction afforded by temporally extended actions. Thus, in a series of sparsely rewarded gridworld environments, t-SR optimally adapts learnt policies far faster than comparable value-based, model-free reinforcement learning methods. We also show that the manner in which t-SR learns to solve these tasks requires the learnt policy to be sampled consistently less often than non-temporally extended policies.
A Simple Approach for State-Action Abstraction using a Learned MDP Homomorphism
Sep 14, 2022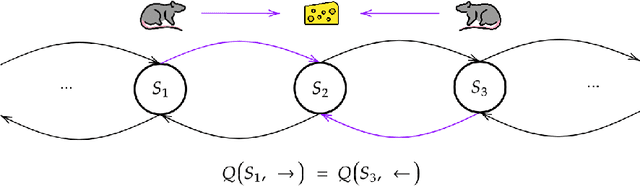
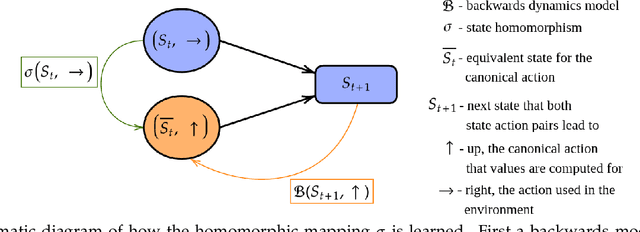
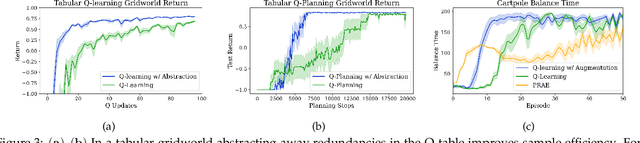
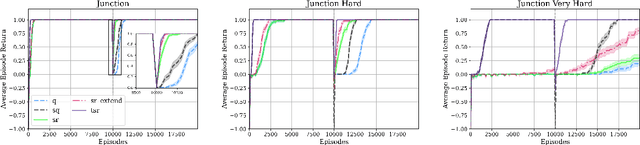
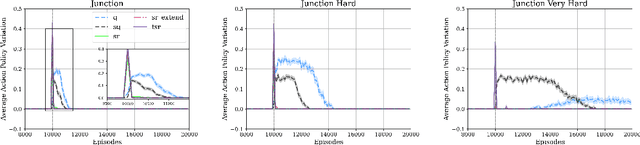
Animals are able to rapidly infer from limited experience when sets of state action pairs have equivalent reward and transition dynamics. On the other hand, modern reinforcement learning systems must painstakingly learn through trial and error that sets of state action pairs are value equivalent -- requiring an often prohibitively large amount of samples from their environment. MDP homomorphisms have been proposed that reduce the observed MDP of an environment to an abstract MDP, which can enable more sample efficient policy learning. Consequently, impressive improvements in sample efficiency have been achieved when a suitable MDP homomorphism can be constructed a priori -- usually by exploiting a practioner's knowledge of environment symmetries. We propose a novel approach to constructing a homomorphism in discrete action spaces, which uses a partial model of environment dynamics to infer which state action pairs lead to the same state -- reducing the size of the state-action space by a factor equal to the cardinality of the action space. We call this method equivalent effect abstraction. In a gridworld setting, we demonstrate empirically that equivalent effect abstraction can improve sample efficiency in a model-free setting and planning efficiency for modelbased approaches. Furthermore, we show on cartpole that our approach outperforms an existing method for learning homomorphisms, while using 33x less training data.
Escaping Stochastic Traps with Aleatoric Mapping Agents
Feb 08, 2021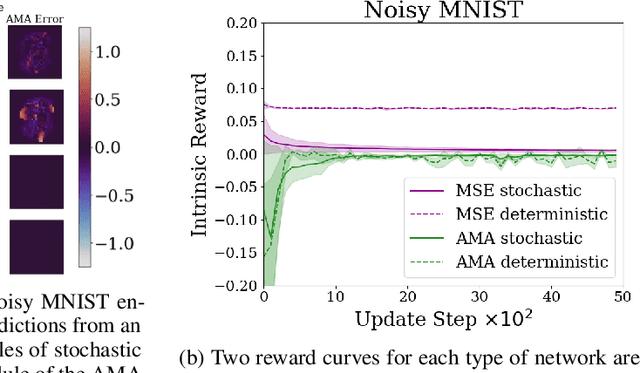

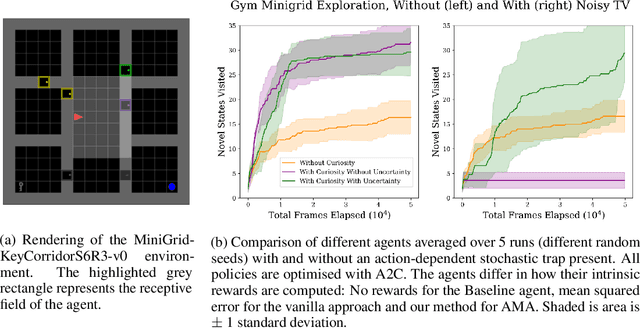
Exploration in environments with sparse rewards is difficult for artificial agents. Curiosity driven learning -- using feed-forward prediction errors as intrinsic rewards -- has achieved some success in these scenarios, but fails when faced with action-dependent noise sources. We present aleatoric mapping agents (AMAs), a neuroscience inspired solution modeled on the cholinergic system of the mammalian brain. AMAs aim to explicitly ascertain which dynamics of the environment are unpredictable, regardless of whether those dynamics are induced by the actions of the agent. This is achieved by generating separate forward predictions for the mean and variance of future states and reducing intrinsic rewards for those transitions with high aleatoric variance. We show AMAs are able to effectively circumvent action-dependent stochastic traps that immobilise conventional curiosity driven agents. The code for all experiments presented in this paper is open sourced: http://github.com/self-supervisor/Escaping-Stochastic-Traps-With-Aleatoric-Mapping-Agents.
MEMO: A Deep Network for Flexible Combination of Episodic Memories
Jan 29, 2020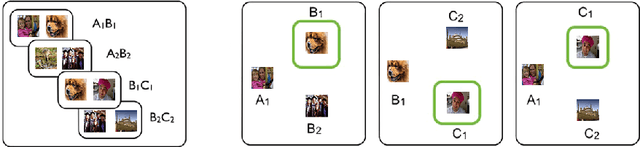
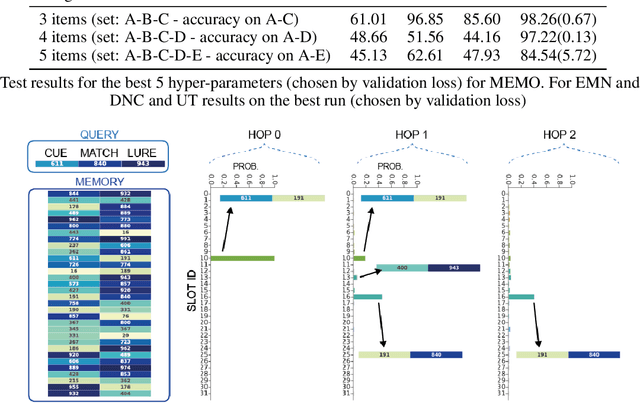
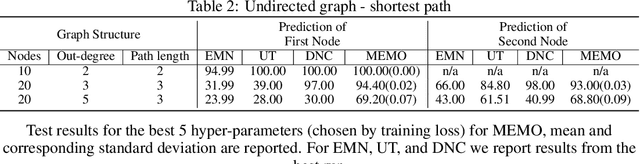

Recent research developing neural network architectures with external memory have often used the benchmark bAbI question and answering dataset which provides a challenging number of tasks requiring reasoning. Here we employed a classic associative inference task from the memory-based reasoning neuroscience literature in order to more carefully probe the reasoning capacity of existing memory-augmented architectures. This task is thought to capture the essence of reasoning -- the appreciation of distant relationships among elements distributed across multiple facts or memories. Surprisingly, we found that current architectures struggle to reason over long distance associations. Similar results were obtained on a more complex task involving finding the shortest path between nodes in a path. We therefore developed MEMO, an architecture endowed with the capacity to reason over longer distances. This was accomplished with the addition of two novel components. First, it introduces a separation between memories (facts) stored in external memory and the items that comprise these facts in external memory. Second, it makes use of an adaptive retrieval mechanism, allowing a variable number of "memory hops" before the answer is produced. MEMO is capable of solving our novel reasoning tasks, as well as match state of the art results in bAbI.
Generalisation of structural knowledge in the hippocampal-entorhinal system
Oct 29, 2018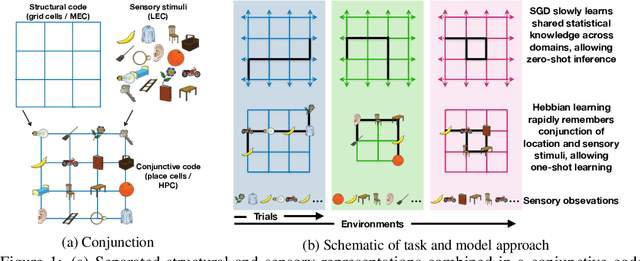
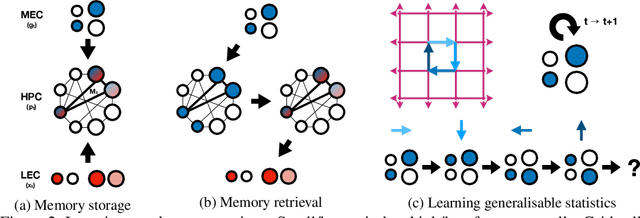
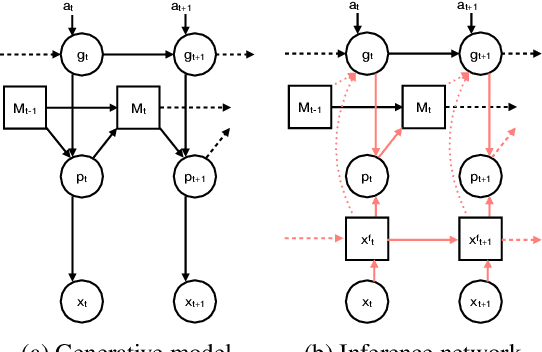

A central problem to understanding intelligence is the concept of generalisation. This allows previously learnt structure to be exploited to solve tasks in novel situations differing in their particularities. We take inspiration from neuroscience, specifically the hippocampal-entorhinal system known to be important for generalisation. We propose that to generalise structural knowledge, the representations of the structure of the world, i.e. how entities in the world relate to each other, need to be separated from representations of the entities themselves. We show, under these principles, artificial neural networks embedded with hierarchy and fast Hebbian memory, can learn the statistics of memories and generalise structural knowledge. Spatial neuronal representations mirroring those found in the brain emerge, suggesting spatial cognition is an instance of more general organising principles. We further unify many entorhinal cell types as basis functions for constructing transition graphs, and show these representations effectively utilise memories. We experimentally support model assumptions, showing a preserved relationship between entorhinal grid and hippocampal place cells across environments.