 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
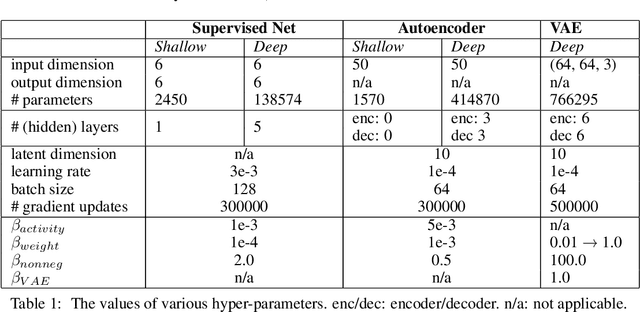
Add to EdgeDisentanglement via Latent Quantization
May 28, 2023



In disentangled representation learning, a model is asked to tease apart a dataset's underlying sources of variation and represent them independently of one another. Since the model is provided with no ground truth information about these sources, inductive biases take a paramount role in enabling disentanglement. In this work, we construct an inductive bias towards compositionally encoding and decoding data by enforcing a harsh communication bottleneck. Concretely, we do this by (i) quantizing the latent space into learnable discrete codes with a separate scalar codebook per dimension and (ii) applying strong model regularization via an unusually high weight decay. Intuitively, the quantization forces the encoder to use a small number of latent values across many datapoints, which in turn enables the decoder to assign a consistent meaning to each value. Regularization then serves to drive the model towards this parsimonious strategy. We demonstrate the broad applicability of this approach by adding it to both basic data-reconstructing (vanilla autoencoder) and latent-reconstructing (InfoGAN) generative models. In order to reliably assess these models, we also propose InfoMEC, new metrics for disentanglement that are cohesively grounded in information theory and fix well-established shortcomings in previous metrics. Together with regularization, latent quantization dramatically improves the modularity and explicitness of learned representations on a representative suite of benchmark datasets. In particular, our quantized-latent autoencoder (QLAE) consistently outperforms strong methods from prior work in these key disentanglement properties without compromising data reconstruction.
Disentangling with Biological Constraints: A Theory of Functional Cell Types
Sep 30, 2022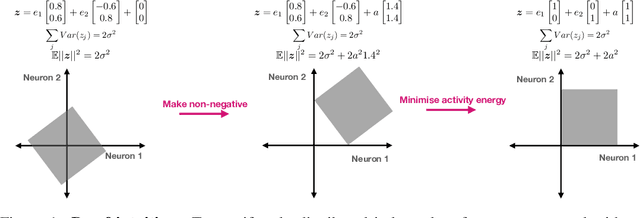
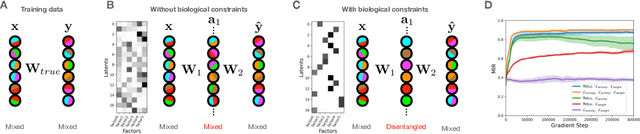

Neurons in the brain are often finely tuned for specific task variables. Moreover, such disentangled representations are highly sought after in machine learning. Here we mathematically prove that simple biological constraints on neurons, namely nonnegativity and energy efficiency in both activity and weights, promote such sought after disentangled representations by enforcing neurons to become selective for single factors of task variation. We demonstrate these constraints lead to disentangling in a variety of tasks and architectures, including variational autoencoders. We also use this theory to explain why the brain partitions its cells into distinct cell types such as grid and object-vector cells, and also explain when the brain instead entangles representations in response to entangled task factors. Overall, this work provides a mathematical understanding of why, when, and how neurons represent factors in both brains and machines, and is a first step towards understanding of how task demands structure neural representations.
How to build a cognitive map: insights from models of the hippocampal formation
Feb 03, 2022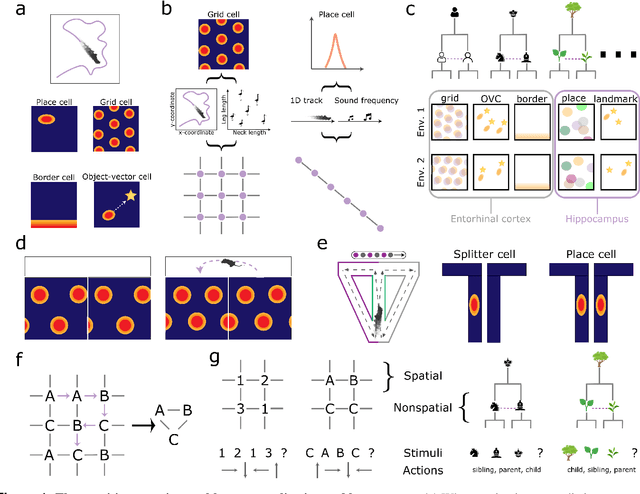
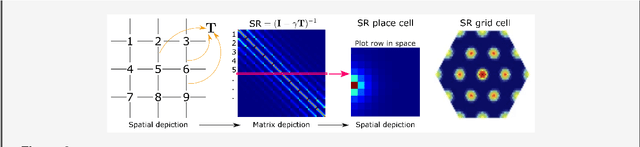
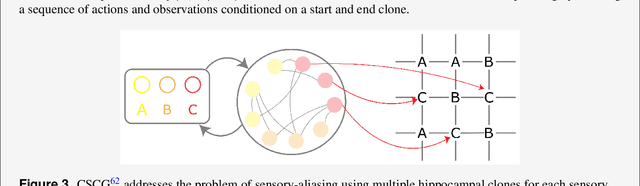
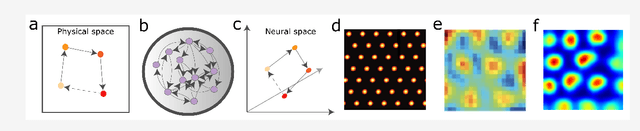
Learning and interpreting the structure of the environment is an innate feature of biological systems, and is integral to guiding flexible behaviours for evolutionary viability. The concept of a cognitive map has emerged as one of the leading metaphors for these capacities, and unravelling the learning and neural representation of such a map has become a central focus of neuroscience. While experimentalists are providing a detailed picture of the neural substrate of cognitive maps in hippocampus and beyond, theorists have been busy building models to bridge the divide between neurons, computation, and behaviour. These models can account for a variety of known representations and neural phenomena, but often provide a differing understanding of not only the underlying principles of cognitive maps, but also the respective roles of hippocampus and cortex. In this Perspective, we bring many of these models into a common language, distil their underlying principles of constructing cognitive maps, provide novel (re)interpretations for neural phenomena, suggest how the principles can be extended to account for prefrontal cortex representations and, finally, speculate on the role of cognitive maps in higher cognitive capacities.
Relating transformers to models and neural representations of the hippocampal formation
Dec 07, 2021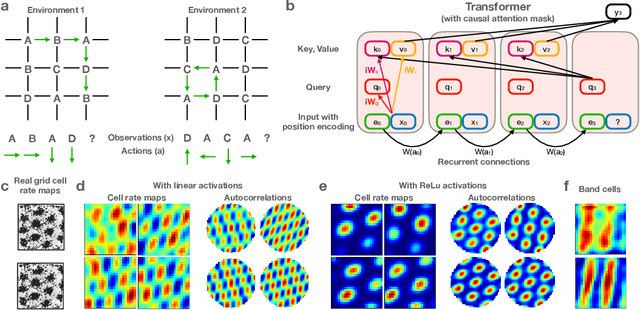
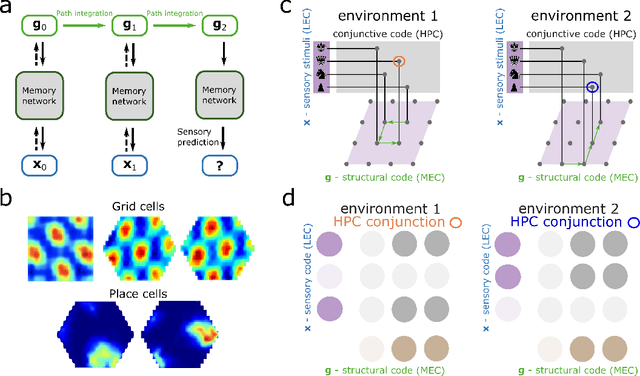
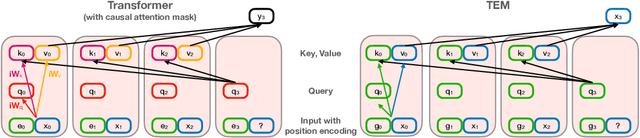
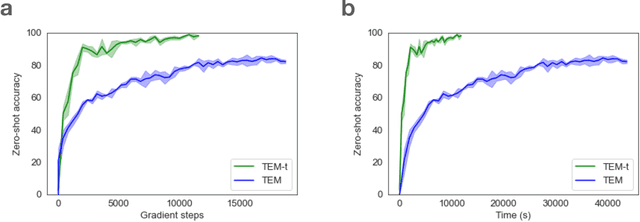
Many deep neural network architectures loosely based on brain networks have recently been shown to replicate neural firing patterns observed in the brain. One of the most exciting and promising novel architectures, the Transformer neural network, was developed without the brain in mind. In this work, we show that transformers, when equipped with recurrent position encodings, replicate the precisely tuned spatial representations of the hippocampal formation; most notably place and grid cells. Furthermore, we show that this result is no surprise since it is closely related to current hippocampal models from neuroscience. We additionally show the transformer version offers dramatic performance gains over the neuroscience version. This work continues to bind computations of artificial and brain networks, offers a novel understanding of the hippocampal-cortical interaction, and suggests how wider cortical areas may perform complex tasks beyond current neuroscience models such as language comprehension.
Constellation: Learning relational abstractions over objects for compositional imagination
Jul 23, 2021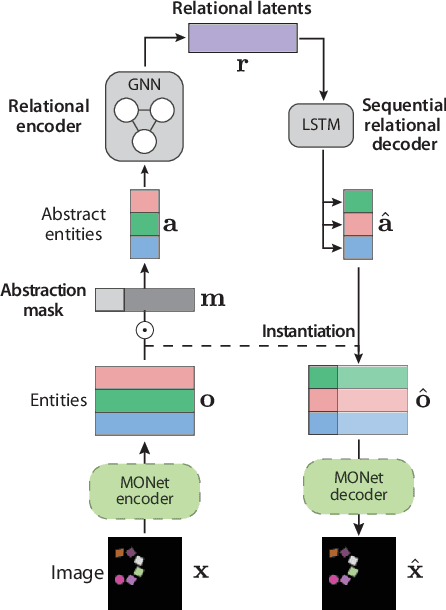
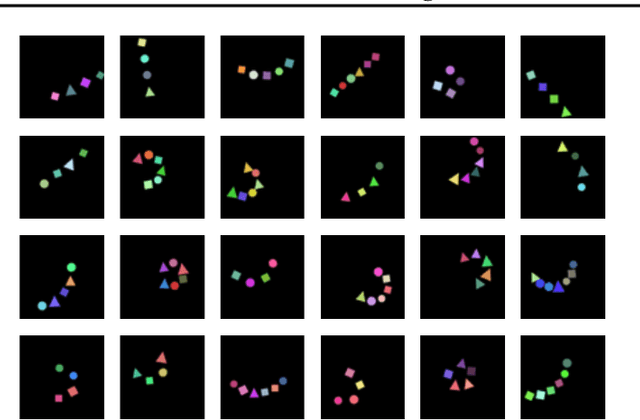


Learning structured representations of visual scenes is currently a major bottleneck to bridging perception with reasoning. While there has been exciting progress with slot-based models, which learn to segment scenes into sets of objects, learning configurational properties of entire groups of objects is still under-explored. To address this problem, we introduce Constellation, a network that learns relational abstractions of static visual scenes, and generalises these abstractions over sensory particularities, thus offering a potential basis for abstract relational reasoning. We further show that this basis, along with language association, provides a means to imagine sensory content in new ways. This work is a first step in the explicit representation of visual relationships and using them for complex cognitive procedures.
Generalisation of structural knowledge in the hippocampal-entorhinal system
Oct 29, 2018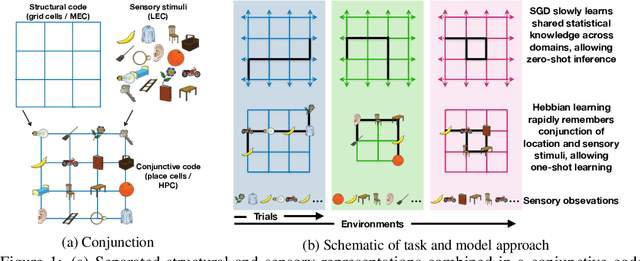
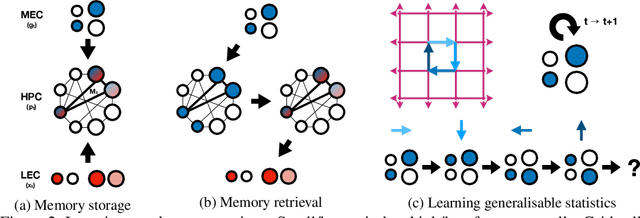
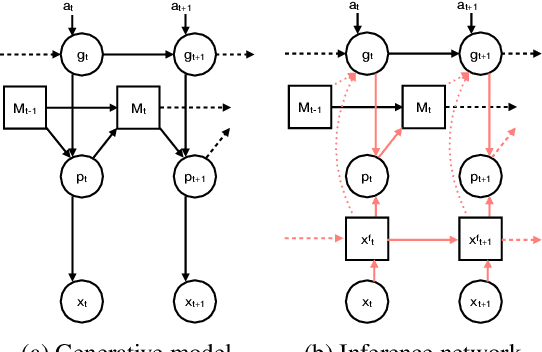

A central problem to understanding intelligence is the concept of generalisation. This allows previously learnt structure to be exploited to solve tasks in novel situations differing in their particularities. We take inspiration from neuroscience, specifically the hippocampal-entorhinal system known to be important for generalisation. We propose that to generalise structural knowledge, the representations of the structure of the world, i.e. how entities in the world relate to each other, need to be separated from representations of the entities themselves. We show, under these principles, artificial neural networks embedded with hierarchy and fast Hebbian memory, can learn the statistics of memories and generalise structural knowledge. Spatial neuronal representations mirroring those found in the brain emerge, suggesting spatial cognition is an instance of more general organising principles. We further unify many entorhinal cell types as basis functions for constructing transition graphs, and show these representations effectively utilise memories. We experimentally support model assumptions, showing a preserved relationship between entorhinal grid and hippocampal place cells across environments.