 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Simple Approach for State-Action Abstraction using a Learned MDP Homomorphism
Paper and Code
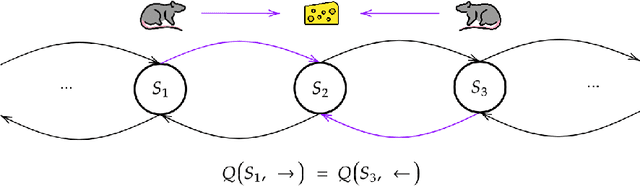
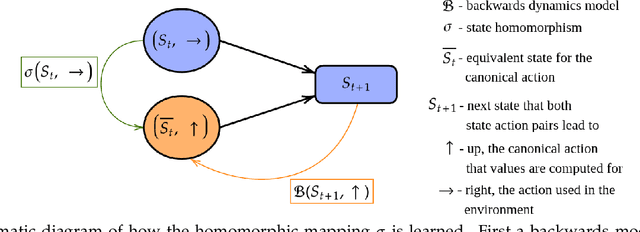
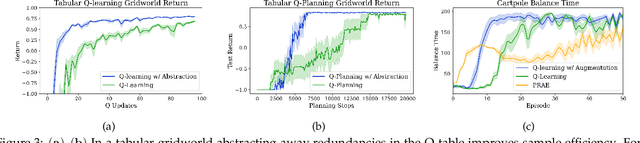
Animals are able to rapidly infer from limited experience when sets of state action pairs have equivalent reward and transition dynamics. On the other hand, modern reinforcement learning systems must painstakingly learn through trial and error that sets of state action pairs are value equivalent -- requiring an often prohibitively large amount of samples from their environment. MDP homomorphisms have been proposed that reduce the observed MDP of an environment to an abstract MDP, which can enable more sample efficient policy learning. Consequently, impressive improvements in sample efficiency have been achieved when a suitable MDP homomorphism can be constructed a priori -- usually by exploiting a practioner's knowledge of environment symmetries. We propose a novel approach to constructing a homomorphism in discrete action spaces, which uses a partial model of environment dynamics to infer which state action pairs lead to the same state -- reducing the size of the state-action space by a factor equal to the cardinality of the action space. We call this method equivalent effect abstraction. In a gridworld setting, we demonstrate empirically that equivalent effect abstraction can improve sample efficiency in a model-free setting and planning efficiency for modelbased approaches. Furthermore, we show on cartpole that our approach outperforms an existing method for learning homomorphisms, while using 33x less training data.