 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Advantage Regret-Matching Actor-Critic
Aug 27, 2020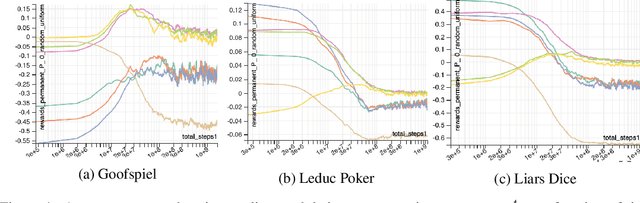
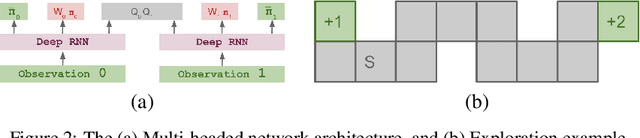

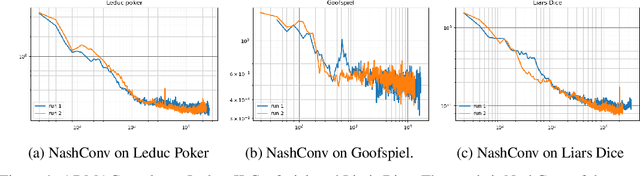
Regret minimization has played a key role in online learning, equilibrium computation in games, and reinforcement learning (RL). In this paper, we describe a general model-free RL method for no-regret learning based on repeated reconsideration of past behavior. We propose a model-free RL algorithm, the AdvantageRegret-Matching Actor-Critic (ARMAC): rather than saving past state-action data, ARMAC saves a buffer of past policies, replaying through them to reconstruct hindsight assessments of past behavior. These retrospective value estimates are used to predict conditional advantages which, combined with regret matching, produces a new policy. In particular, ARMAC learns from sampled trajectories in a centralized training setting, without requiring the application of importance sampling commonly used in Monte Carlo counterfactual regret (CFR) minimization; hence, it does not suffer from excessive variance in large environments. In the single-agent setting, ARMAC shows an interesting form of exploration by keeping past policies intact. In the multiagent setting, ARMAC in self-play approaches Nash equilibria on some partially-observable zero-sum benchmarks. We provide exploitability estimates in the significantly larger game of betting-abstracted no-limit Texas Hold'em.
MEMO: A Deep Network for Flexible Combination of Episodic Memories
Jan 29, 2020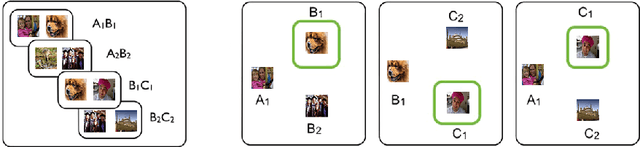
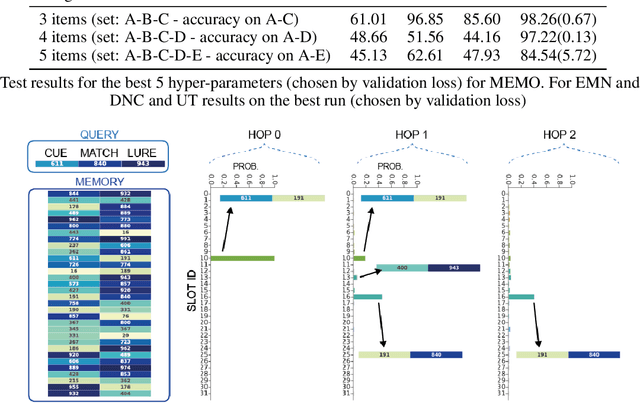
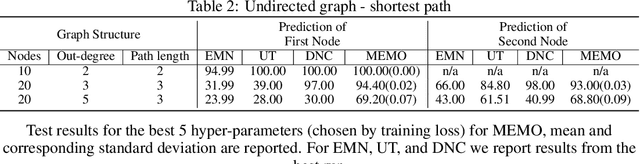

Recent research developing neural network architectures with external memory have often used the benchmark bAbI question and answering dataset which provides a challenging number of tasks requiring reasoning. Here we employed a classic associative inference task from the memory-based reasoning neuroscience literature in order to more carefully probe the reasoning capacity of existing memory-augmented architectures. This task is thought to capture the essence of reasoning -- the appreciation of distant relationships among elements distributed across multiple facts or memories. Surprisingly, we found that current architectures struggle to reason over long distance associations. Similar results were obtained on a more complex task involving finding the shortest path between nodes in a path. We therefore developed MEMO, an architecture endowed with the capacity to reason over longer distances. This was accomplished with the addition of two novel components. First, it introduces a separation between memories (facts) stored in external memory and the items that comprise these facts in external memory. Second, it makes use of an adaptive retrieval mechanism, allowing a variable number of "memory hops" before the answer is produced. MEMO is capable of solving our novel reasoning tasks, as well as match state of the art results in bAbI.
OpenSpiel: A Framework for Reinforcement Learning in Games
Oct 10, 2019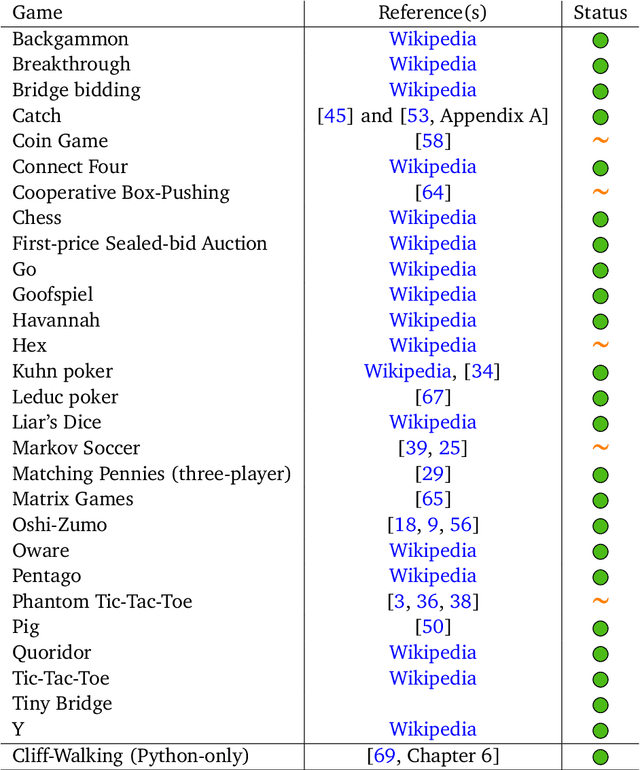
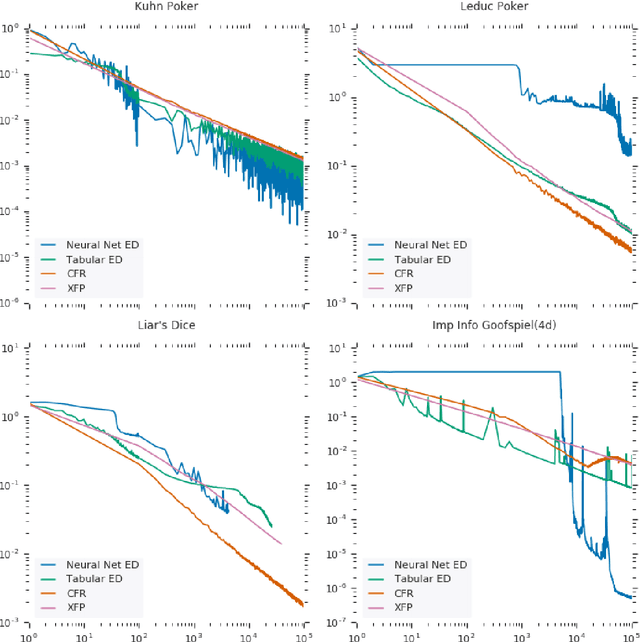
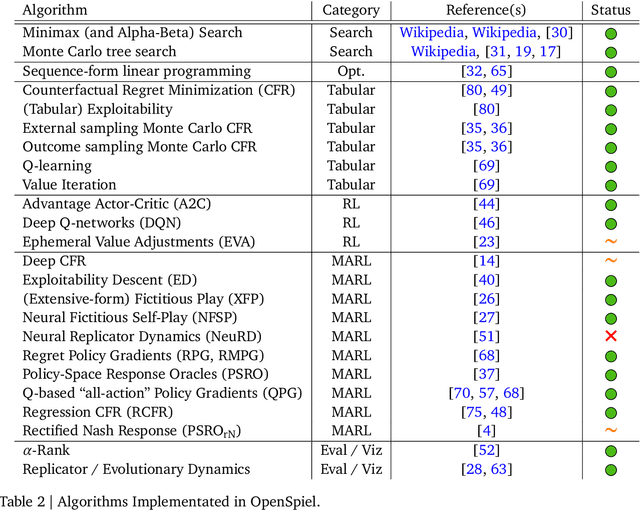
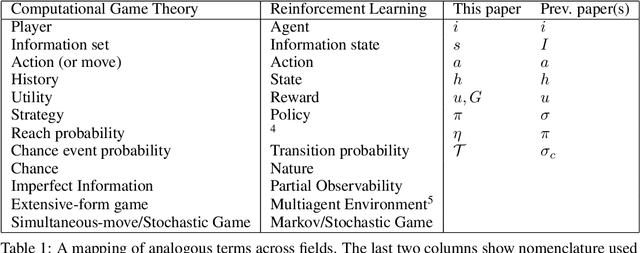
OpenSpiel is a collection of environments and algorithms for research in general reinforcement learning and search/planning in games. OpenSpiel supports n-player (single- and multi- agent) zero-sum, cooperative and general-sum, one-shot and sequential, strictly turn-taking and simultaneous-move, perfect and imperfect information games, as well as traditional multiagent environments such as (partially- and fully- observable) grid worlds and social dilemmas. OpenSpiel also includes tools to analyze learning dynamics and other common evaluation metrics. This document serves both as an overview of the code base and an introduction to the terminology, core concepts, and algorithms across the fields of reinforcement learning, computational game theory, and search.
Compositional Imitation Learning: Explaining and executing one task at a time
Dec 04, 2018

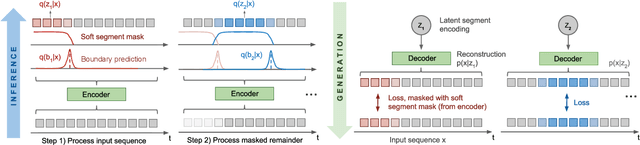

We introduce a framework for Compositional Imitation Learning and Execution (CompILE) of hierarchically-structured behavior. CompILE learns reusable, variable-length segments of behavior from demonstration data using a novel unsupervised, fully-differentiable sequence segmentation module. These learned behaviors can then be re-composed and executed to perform new tasks. At training time, CompILE auto-encodes observed behavior into a sequence of latent codes, each corresponding to a variable-length segment in the input sequence. Once trained, our model generalizes to sequences of longer length and from environment instances not seen during training. We evaluate our model in a challenging 2D multi-task environment and show that CompILE can find correct task boundaries and event encodings in an unsupervised manner without requiring annotated demonstration data. Latent codes and associated behavior policies discovered by CompILE can be used by a hierarchical agent, where the high-level policy selects actions in the latent code space, and the low-level, task-specific policies are simply the learned decoders. We found that our agent could learn given only sparse rewards, where agents without task-specific policies struggle.
Actor-Critic Policy Optimization in Partially Observable Multiagent Environments
Oct 21, 2018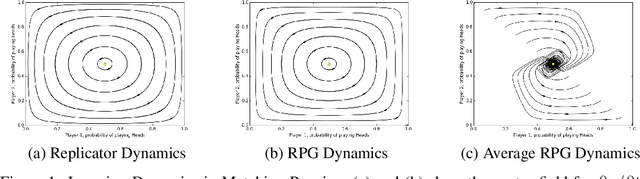
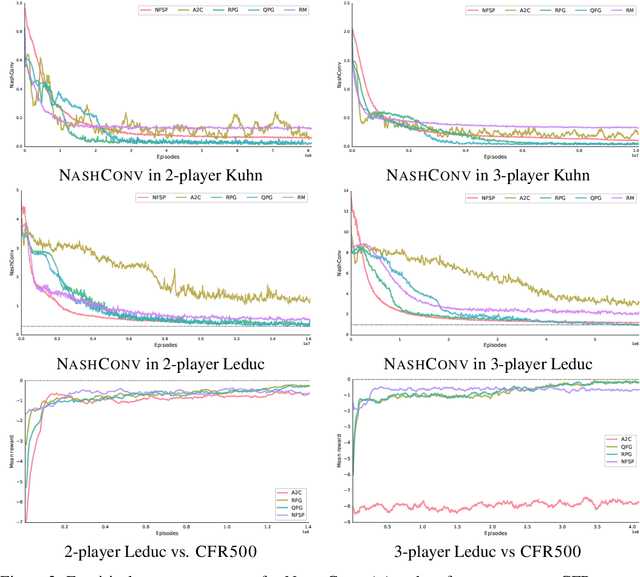
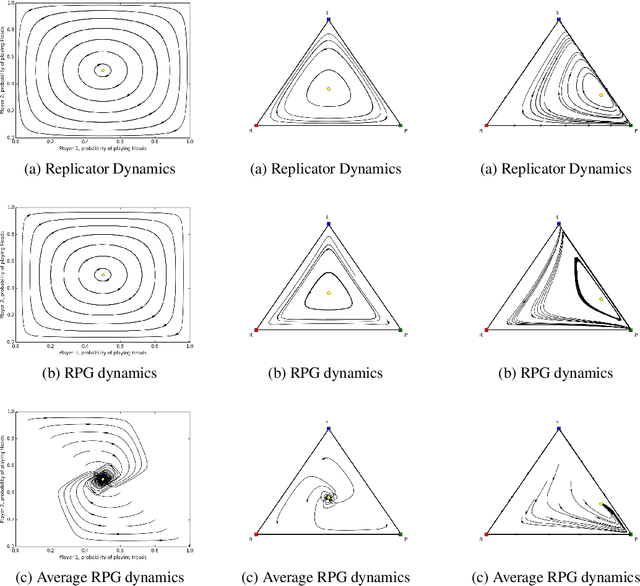
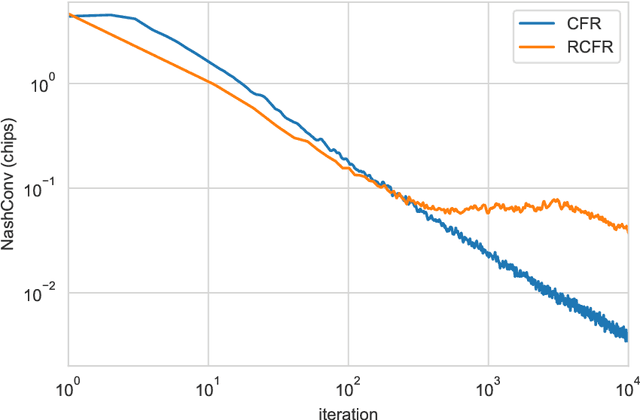
Optimization of parameterized policies for reinforcement learning (RL) is an important and challenging problem in artificial intelligence. Among the most common approaches are algorithms based on gradient ascent of a score function representing discounted return. In this paper, we examine the role of these policy gradient and actor-critic algorithms in partially-observable multiagent environments. We show several candidate policy update rules and relate them to a foundation of regret minimization and multiagent learning techniques for the one-shot and tabular cases, leading to previously unknown convergence guarantees. We apply our method to model-free multiagent reinforcement learning in adversarial sequential decision problems (zero-sum imperfect information games), using RL-style function approximation. We evaluate on commonly used benchmark Poker domains, showing performance against fixed policies and empirical convergence to approximate Nash equilibria in self-play with rates similar to or better than a baseline model-free algorithm for zero sum games, without any domain-specific state space reductions.
Relational inductive biases, deep learning, and graph networks
Oct 17, 2018
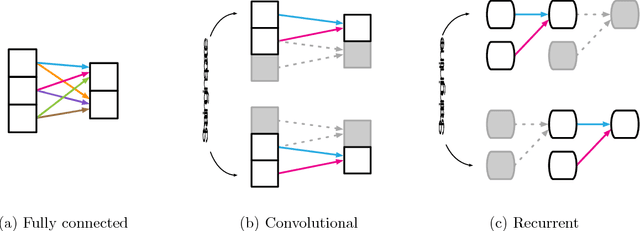
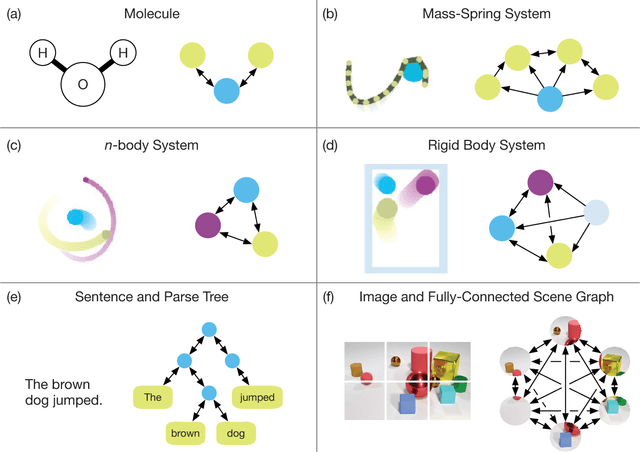
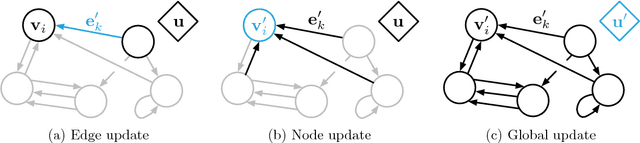
Artificial intelligence (AI) has undergone a renaissance recently, making major progress in key domains such as vision, language, control, and decision-making. This has been due, in part, to cheap data and cheap compute resources, which have fit the natural strengths of deep learning. However, many defining characteristics of human intelligence, which developed under much different pressures, remain out of reach for current approaches. In particular, generalizing beyond one's experiences--a hallmark of human intelligence from infancy--remains a formidable challenge for modern AI. The following is part position paper, part review, and part unification. We argue that combinatorial generalization must be a top priority for AI to achieve human-like abilities, and that structured representations and computations are key to realizing this objective. Just as biology uses nature and nurture cooperatively, we reject the false choice between "hand-engineering" and "end-to-end" learning, and instead advocate for an approach which benefits from their complementary strengths. We explore how using relational inductive biases within deep learning architectures can facilitate learning about entities, relations, and rules for composing them. We present a new building block for the AI toolkit with a strong relational inductive bias--the graph network--which generalizes and extends various approaches for neural networks that operate on graphs, and provides a straightforward interface for manipulating structured knowledge and producing structured behaviors. We discuss how graph networks can support relational reasoning and combinatorial generalization, laying the foundation for more sophisticated, interpretable, and flexible patterns of reasoning. As a companion to this paper, we have released an open-source software library for building graph networks, with demonstrations of how to use them in practice.
Relational Forward Models for Multi-Agent Learning
Sep 28, 2018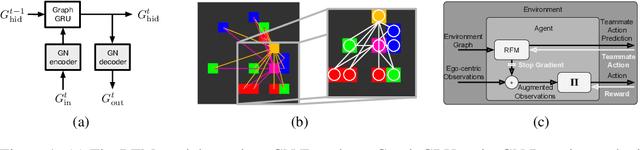
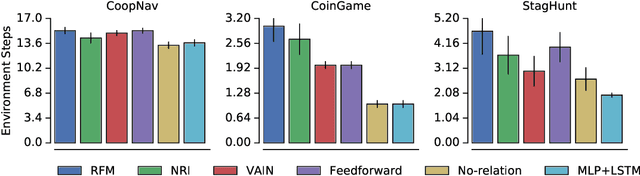
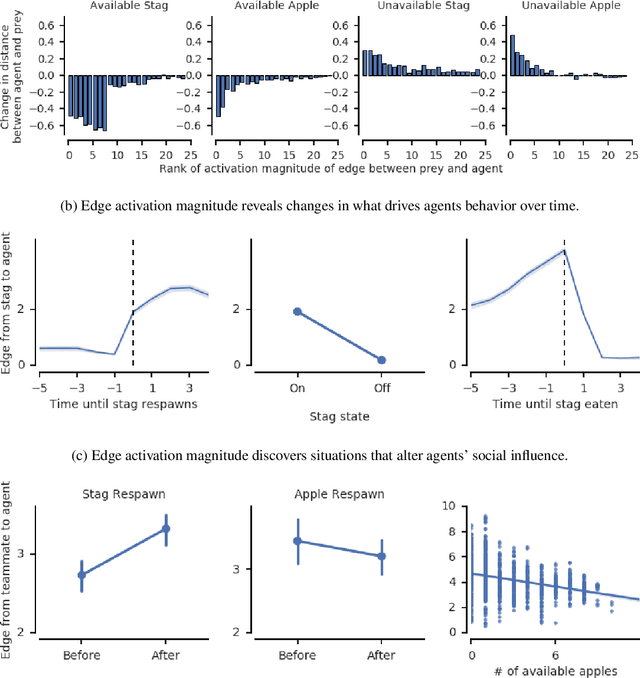
The behavioral dynamics of multi-agent systems have a rich and orderly structure, which can be leveraged to understand these systems, and to improve how artificial agents learn to operate in them. Here we introduce Relational Forward Models (RFM) for multi-agent learning, networks that can learn to make accurate predictions of agents' future behavior in multi-agent environments. Because these models operate on the discrete entities and relations present in the environment, they produce interpretable intermediate representations which offer insights into what drives agents' behavior, and what events mediate the intensity and valence of social interactions. Furthermore, we show that embedding RFM modules inside agents results in faster learning systems compared to non-augmented baselines. As more and more of the autonomous systems we develop and interact with become multi-agent in nature, developing richer analysis tools for characterizing how and why agents make decisions is increasingly necessary. Moreover, developing artificial agents that quickly and safely learn to coordinate with one another, and with humans in shared environments, is crucial.
Relational Deep Reinforcement Learning
Jun 28, 2018
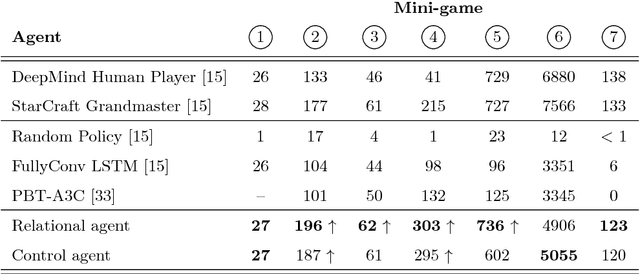
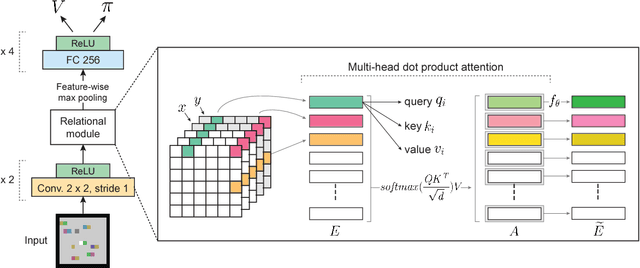
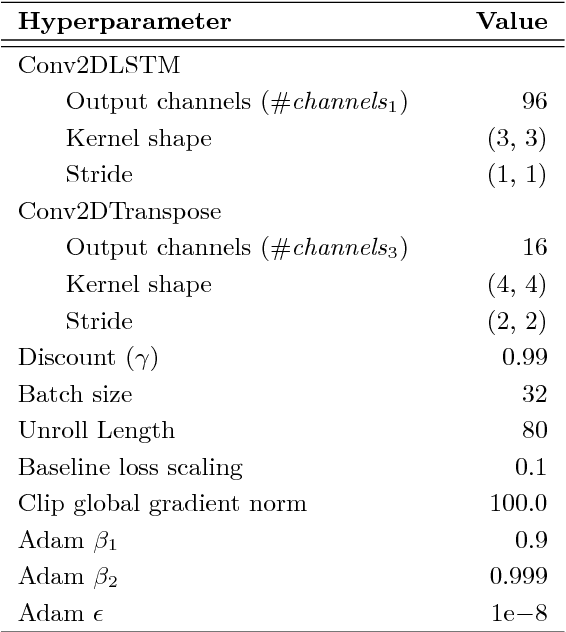
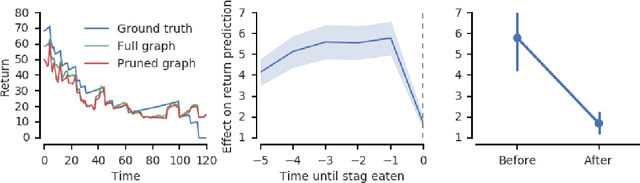
We introduce an approach for deep reinforcement learning (RL) that improves upon the efficiency, generalization capacity, and interpretability of conventional approaches through structured perception and relational reasoning. It uses self-attention to iteratively reason about the relations between entities in a scene and to guide a model-free policy. Our results show that in a novel navigation and planning task called Box-World, our agent finds interpretable solutions that improve upon baselines in terms of sample complexity, ability to generalize to more complex scenes than experienced during training, and overall performance. In the StarCraft II Learning Environment, our agent achieves state-of-the-art performance on six mini-games -- surpassing human grandmaster performance on four. By considering architectural inductive biases, our work opens new directions for overcoming important, but stubborn, challenges in deep RL.
A Unified Game-Theoretic Approach to Multiagent Reinforcement Learning
Nov 07, 2017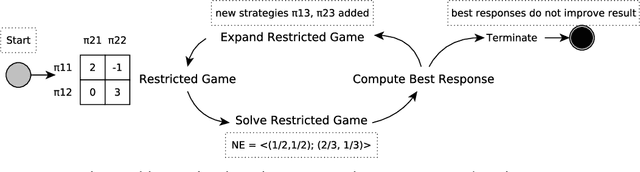
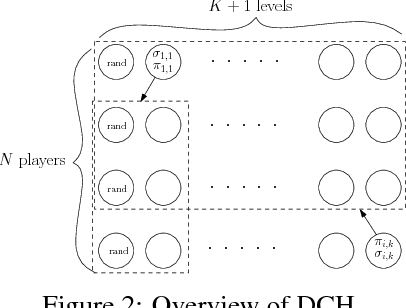
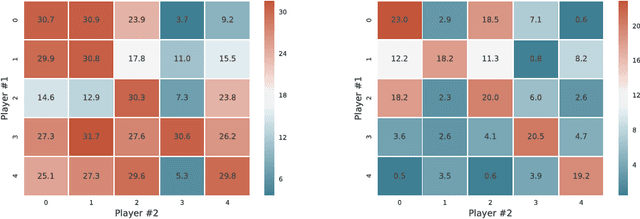
To achieve general intelligence, agents must learn how to interact with others in a shared environment: this is the challenge of multiagent reinforcement learning (MARL). The simplest form is independent reinforcement learning (InRL), where each agent treats its experience as part of its (non-stationary) environment. In this paper, we first observe that policies learned using InRL can overfit to the other agents' policies during training, failing to sufficiently generalize during execution. We introduce a new metric, joint-policy correlation, to quantify this effect. We describe an algorithm for general MARL, based on approximate best responses to mixtures of policies generated using deep reinforcement learning, and empirical game-theoretic analysis to compute meta-strategies for policy selection. The algorithm generalizes previous ones such as InRL, iterated best response, double oracle, and fictitious play. Then, we present a scalable implementation which reduces the memory requirement using decoupled meta-solvers. Finally, we demonstrate the generality of the resulting policies in two partially observable settings: gridworld coordination games and poker.
A multi-agent reinforcement learning model of common-pool resource appropriation
Sep 06, 2017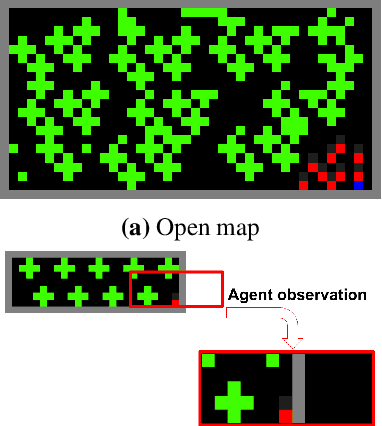
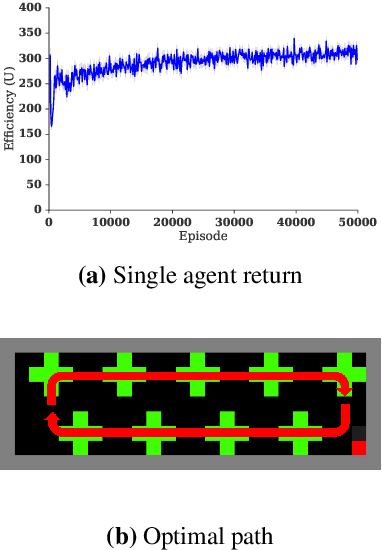
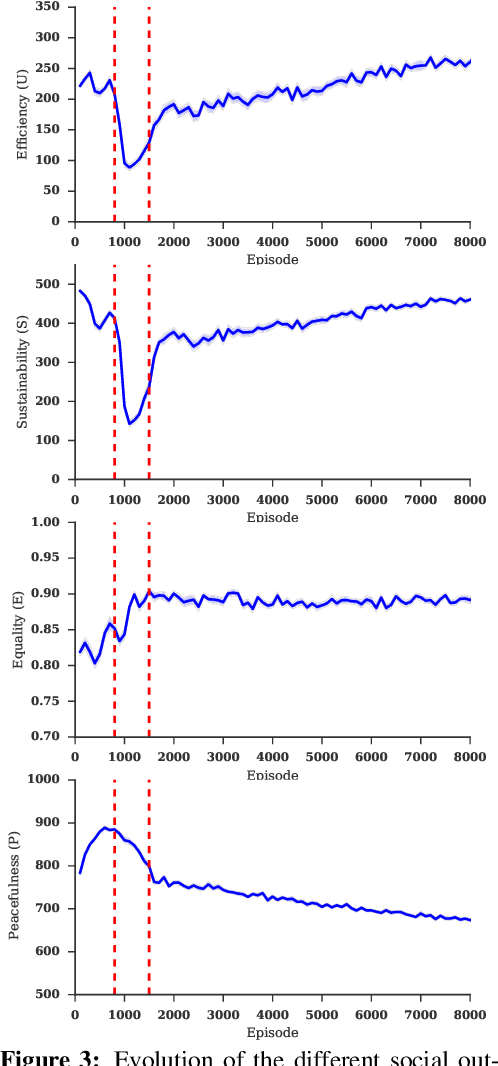
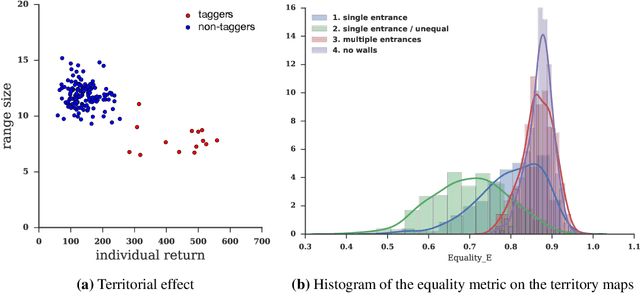
Humanity faces numerous problems of common-pool resource appropriation. This class of multi-agent social dilemma includes the problems of ensuring sustainable use of fresh water, common fisheries, grazing pastures, and irrigation systems. Abstract models of common-pool resource appropriation based on non-cooperative game theory predict that self-interested agents will generally fail to find socially positive equilibria---a phenomenon called the tragedy of the commons. However, in reality, human societies are sometimes able to discover and implement stable cooperative solutions. Decades of behavioral game theory research have sought to uncover aspects of human behavior that make this possible. Most of that work was based on laboratory experiments where participants only make a single choice: how much to appropriate. Recognizing the importance of spatial and temporal resource dynamics, a recent trend has been toward experiments in more complex real-time video game-like environments. However, standard methods of non-cooperative game theory can no longer be used to generate predictions for this case. Here we show that deep reinforcement learning can be used instead. To that end, we study the emergent behavior of groups of independently learning agents in a partially observed Markov game modeling common-pool resource appropriation. Our experiments highlight the importance of trial-and-error learning in common-pool resource appropriation and shed light on the relationship between exclusion, sustainability, and inequality.