 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Lines and Circles: Unveiling the Geometric Reasoning Gap in Large Language Models
Feb 14, 2024



Large Language Models (LLMs) demonstrate ever-increasing abilities in mathematical and algorithmic tasks, yet their geometric reasoning skills are underexplored. We investigate LLMs' abilities in constructive geometric problem-solving one of the most fundamental steps in the development of human mathematical reasoning. Our work reveals notable challenges that the state-of-the-art LLMs face in this domain despite many successes in similar areas. LLMs exhibit biases in target variable selection and struggle with 2D spatial relationships, often misrepresenting and hallucinating objects and their placements. To this end, we introduce a framework that formulates an LLMs-based multi-agents system that enhances their existing reasoning potential by conducting an internal dialogue. This work underscores LLMs' current limitations in geometric reasoning and improves geometric reasoning capabilities through self-correction, collaboration, and diverse role specializations.
SODA: Bottleneck Diffusion Models for Representation Learning
Nov 29, 2023We introduce SODA, a self-supervised diffusion model, designed for representation learning. The model incorporates an image encoder, which distills a source view into a compact representation, that, in turn, guides the generation of related novel views. We show that by imposing a tight bottleneck between the encoder and a denoising decoder, and leveraging novel view synthesis as a self-supervised objective, we can turn diffusion models into strong representation learners, capable of capturing visual semantics in an unsupervised manner. To the best of our knowledge, SODA is the first diffusion model to succeed at ImageNet linear-probe classification, and, at the same time, it accomplishes reconstruction, editing and synthesis tasks across a wide range of datasets. Further investigation reveals the disentangled nature of its emergent latent space, that serves as an effective interface to control and manipulate the model's produced images. All in all, we aim to shed light on the exciting and promising potential of diffusion models, not only for image generation, but also for learning rich and robust representations.
Perception Test: A Diagnostic Benchmark for Multimodal Video Models
May 23, 2023


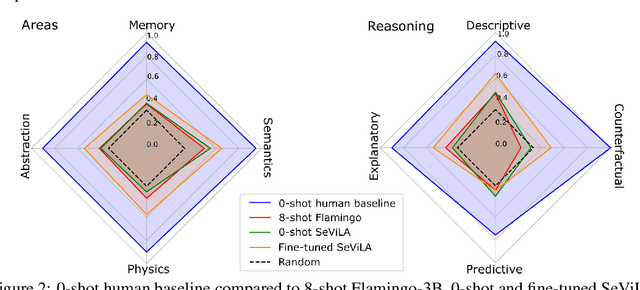
We propose a novel multimodal video benchmark - the Perception Test - to evaluate the perception and reasoning skills of pre-trained multimodal models (e.g. Flamingo, BEiT-3, or GPT-4). Compared to existing benchmarks that focus on computational tasks (e.g. classification, detection or tracking), the Perception Test focuses on skills (Memory, Abstraction, Physics, Semantics) and types of reasoning (descriptive, explanatory, predictive, counterfactual) across video, audio, and text modalities, to provide a comprehensive and efficient evaluation tool. The benchmark probes pre-trained models for their transfer capabilities, in a zero-shot / few-shot or limited finetuning regime. For these purposes, the Perception Test introduces 11.6k real-world videos, 23s average length, designed to show perceptually interesting situations, filmed by around 100 participants worldwide. The videos are densely annotated with six types of labels (multiple-choice and grounded video question-answers, object and point tracks, temporal action and sound segments), enabling both language and non-language evaluations. The fine-tuning and validation splits of the benchmark are publicly available (CC-BY license), in addition to a challenge server with a held-out test split. Human baseline results compared to state-of-the-art video QA models show a significant gap in performance (91.4% vs 43.6%), suggesting that there is significant room for improvement in multimodal video understanding. Dataset, baselines code, and challenge server are available at https://github.com/deepmind/perception_test
A Simple, Yet Effective Approach to Finding Biases in Code Generation
Oct 31, 2022



Recently, scores of high-performing code generation systems have surfaced. As has become a popular choice in many domains, code generation is often approached using large language models as a core, trained under the masked or causal language modeling schema. This work shows that current code generation systems exhibit biases inherited from large language model backbones, which might leak into generated code under specific circumstances. To investigate the effect, we propose a framework that automatically removes hints and exposes various biases that these code generation models use. We apply our framework to three coding challenges and test it across top-performing coding generation models. Our experiments reveal biases towards specific prompt structure and exploitation of keywords during code generation. Finally, we demonstrate how to use our framework as a data transformation technique, which we find a promising direction toward more robust code generation.
Compressed Vision for Efficient Video Understanding
Oct 06, 2022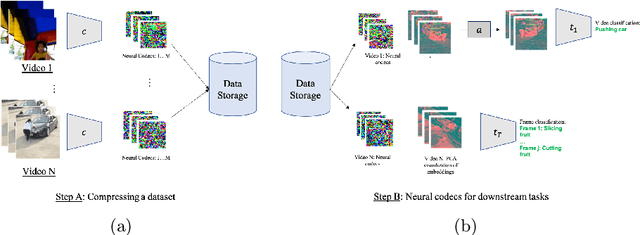
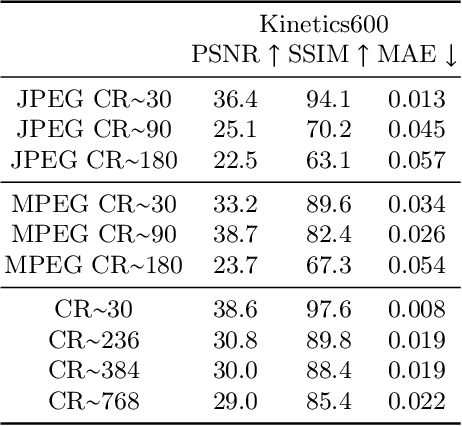
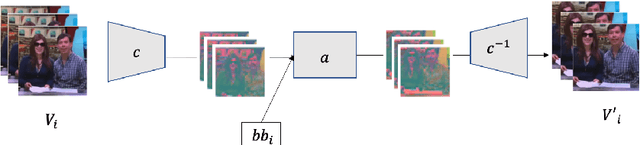

Experience and reasoning occur across multiple temporal scales: milliseconds, seconds, hours or days. The vast majority of computer vision research, however, still focuses on individual images or short videos lasting only a few seconds. This is because handling longer videos require more scalable approaches even to process them. In this work, we propose a framework enabling research on hour-long videos with the same hardware that can now process second-long videos. We replace standard video compression, e.g. JPEG, with neural compression and show that we can directly feed compressed videos as inputs to regular video networks. Operating on compressed videos improves efficiency at all pipeline levels -- data transfer, speed and memory -- making it possible to train models faster and on much longer videos. Processing compressed signals has, however, the downside of precluding standard augmentation techniques if done naively. We address that by introducing a small network that can apply transformations to latent codes corresponding to commonly used augmentations in the original video space. We demonstrate that with our compressed vision pipeline, we can train video models more efficiently on popular benchmarks such as Kinetics600 and COIN. We also perform proof-of-concept experiments with new tasks defined over hour-long videos at standard frame rates. Processing such long videos is impossible without using compressed representation.
Neural Payoff Machines: Predicting Fair and Stable Payoff Allocations Among Team Members
Aug 18, 2022
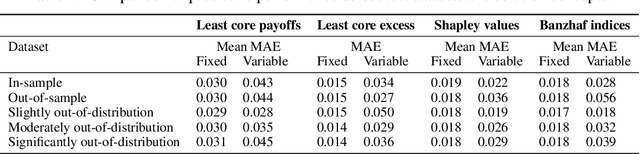
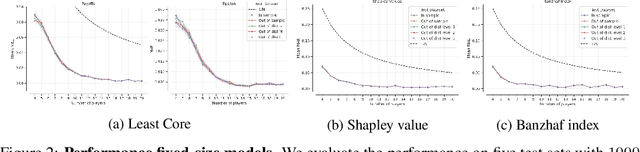
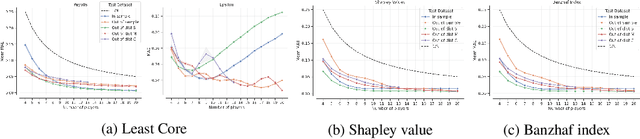
In many multi-agent settings, participants can form teams to achieve collective outcomes that may far surpass their individual capabilities. Measuring the relative contributions of agents and allocating them shares of the reward that promote long-lasting cooperation are difficult tasks. Cooperative game theory offers solution concepts identifying distribution schemes, such as the Shapley value, that fairly reflect the contribution of individuals to the performance of the team or the Core, which reduces the incentive of agents to abandon their team. Applications of such methods include identifying influential features and sharing the costs of joint ventures or team formation. Unfortunately, using these solutions requires tackling a computational barrier as they are hard to compute, even in restricted settings. In this work, we show how cooperative game-theoretic solutions can be distilled into a learned model by training neural networks to propose fair and stable payoff allocations. We show that our approach creates models that can generalize to games far from the training distribution and can predict solutions for more players than observed during training. An important application of our framework is Explainable AI: our approach can be used to speed-up Shapley value computations on many instances.
CLIP-CLOP: CLIP-Guided Collage and Photomontage
May 19, 2022
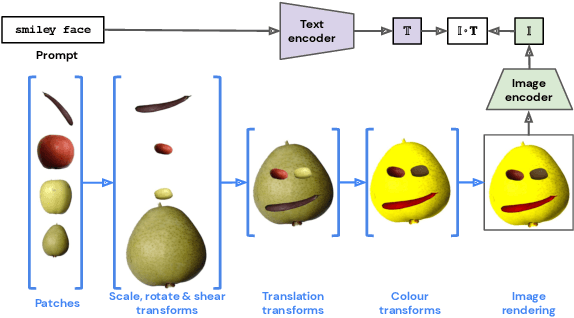
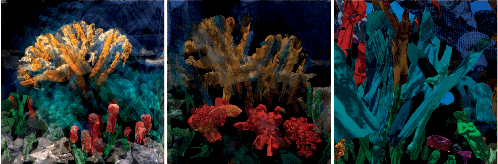
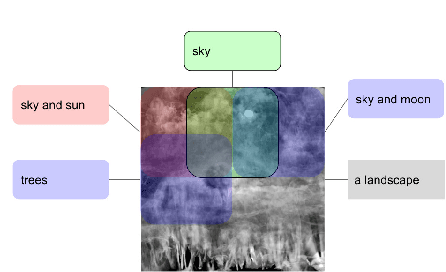
The unabated mystique of large-scale neural networks, such as the CLIP dual image-and-text encoder, popularized automatically generated art. Increasingly more sophisticated generators enhanced the artworks' realism and visual appearance, and creative prompt engineering enabled stylistic expression. Guided by an artist-in-the-loop ideal, we design a gradient-based generator to produce collages. It requires the human artist to curate libraries of image patches and to describe (with prompts) the whole image composition, with the option to manually adjust the patches' positions during generation, thereby allowing humans to reclaim some control of the process and achieve greater creative freedom. We explore the aesthetic potentials of high-resolution collages, and provide an open-source Google Colab as an artistic tool.
Transframer: Arbitrary Frame Prediction with Generative Models
Mar 18, 2022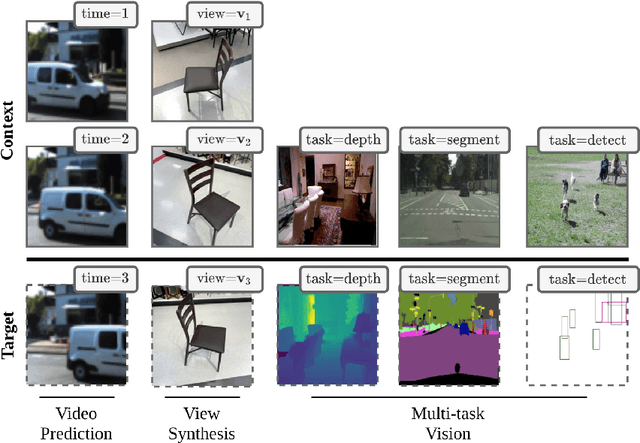

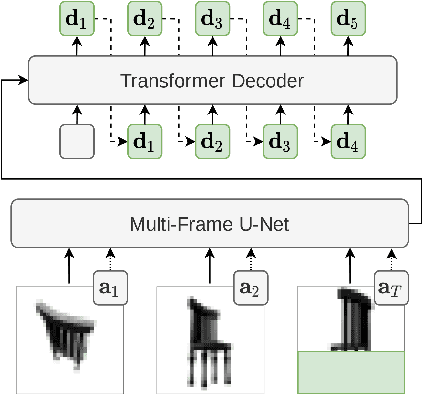

We present a general-purpose framework for image modelling and vision tasks based on probabilistic frame prediction. Our approach unifies a broad range of tasks, from image segmentation, to novel view synthesis and video interpolation. We pair this framework with an architecture we term Transframer, which uses U-Net and Transformer components to condition on annotated context frames, and outputs sequences of sparse, compressed image features. Transframer is the state-of-the-art on a variety of video generation benchmarks, is competitive with the strongest models on few-shot view synthesis, and can generate coherent 30 second videos from a single image without any explicit geometric information. A single generalist Transframer simultaneously produces promising results on 8 tasks, including semantic segmentation, image classification and optical flow prediction with no task-specific architectural components, demonstrating that multi-task computer vision can be tackled using probabilistic image models. Our approach can in principle be applied to a wide range of applications that require learning the conditional structure of annotated image-formatted data.
Measuring CLEVRness: Blackbox testing of Visual Reasoning Models
Feb 28, 2022
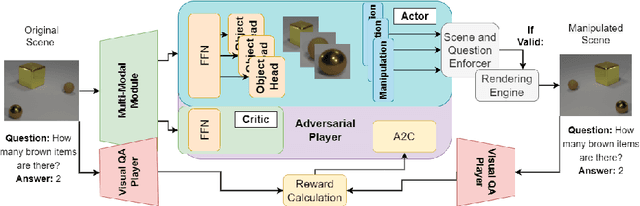
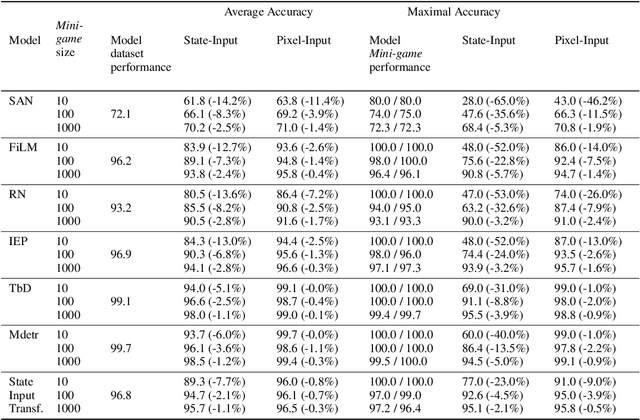
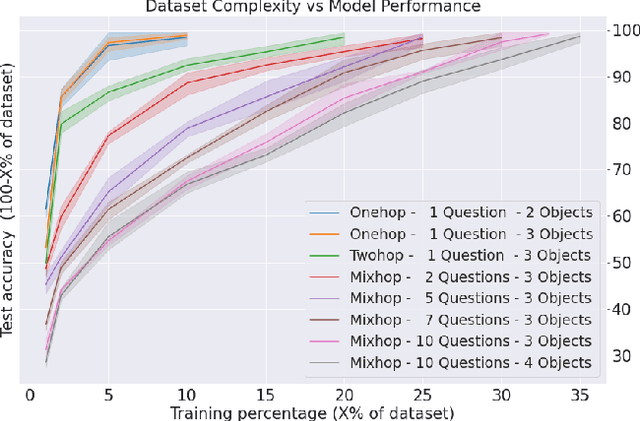
How can we measure the reasoning capabilities of intelligence systems? Visual question answering provides a convenient framework for testing the model's abilities by interrogating the model through questions about the scene. However, despite scores of various visual QA datasets and architectures, which sometimes yield even a super-human performance, the question of whether those architectures can actually reason remains open to debate. To answer this, we extend the visual question answering framework and propose the following behavioral test in the form of a two-player game. We consider black-box neural models of CLEVR. These models are trained on a diagnostic dataset benchmarking reasoning. Next, we train an adversarial player that re-configures the scene to fool the CLEVR model. We show that CLEVR models, which otherwise could perform at a human level, can easily be fooled by our agent. Our results put in doubt whether data-driven approaches can do reasoning without exploiting the numerous biases that are often present in those datasets. Finally, we also propose a controlled experiment measuring the efficiency of such models to learn and perform reasoning.
General-purpose, long-context autoregressive modeling with Perceiver AR
Feb 15, 2022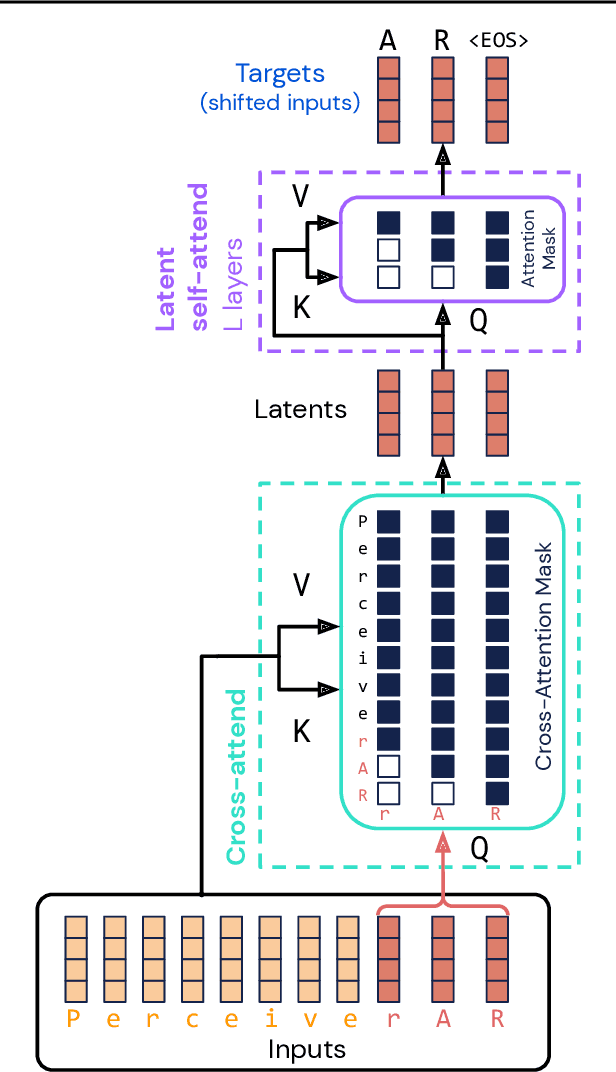
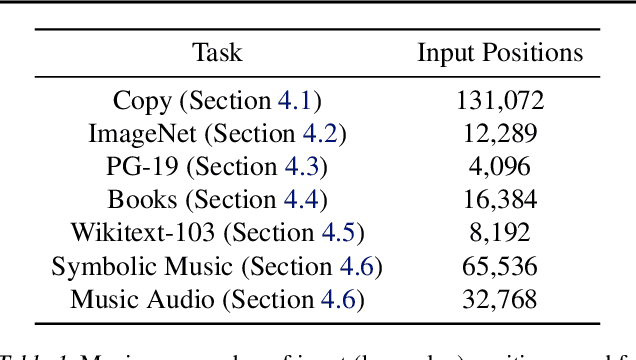
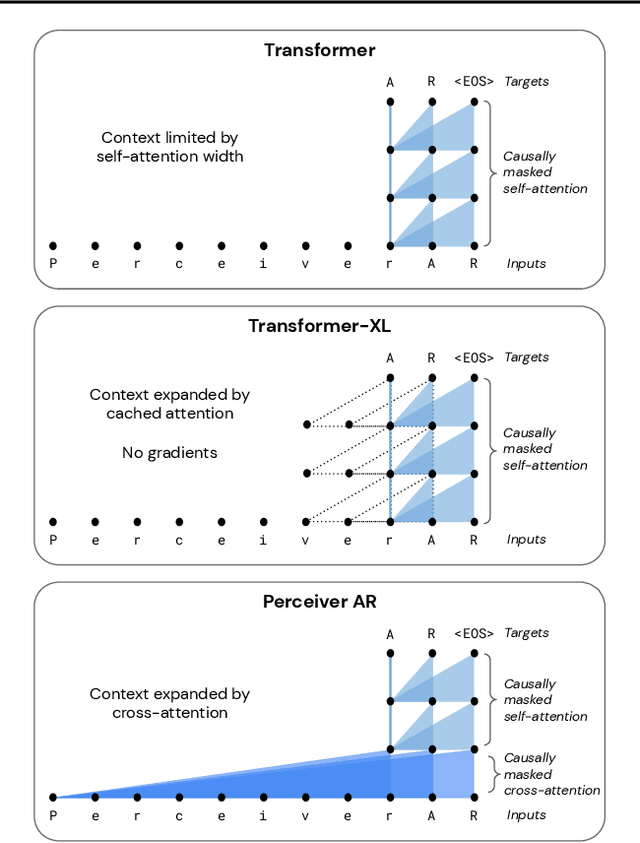
Real-world data is high-dimensional: a book, image, or musical performance can easily contain hundreds of thousands of elements even after compression. However, the most commonly used autoregressive models, Transformers, are prohibitively expensive to scale to the number of inputs and layers needed to capture this long-range structure. We develop Perceiver AR, an autoregressive, modality-agnostic architecture which uses cross-attention to map long-range inputs to a small number of latents while also maintaining end-to-end causal masking. Perceiver AR can directly attend to over a hundred thousand tokens, enabling practical long-context density estimation without the need for hand-crafted sparsity patterns or memory mechanisms. When trained on images or music, Perceiver AR generates outputs with clear long-term coherence and structure. Our architecture also obtains state-of-the-art likelihood on long-sequence benchmarks, including 64 x 64 ImageNet images and PG-19 books.