 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Lines and Circles: Unveiling the Geometric Reasoning Gap in Large Language Models
Feb 14, 2024



Large Language Models (LLMs) demonstrate ever-increasing abilities in mathematical and algorithmic tasks, yet their geometric reasoning skills are underexplored. We investigate LLMs' abilities in constructive geometric problem-solving one of the most fundamental steps in the development of human mathematical reasoning. Our work reveals notable challenges that the state-of-the-art LLMs face in this domain despite many successes in similar areas. LLMs exhibit biases in target variable selection and struggle with 2D spatial relationships, often misrepresenting and hallucinating objects and their placements. To this end, we introduce a framework that formulates an LLMs-based multi-agents system that enhances their existing reasoning potential by conducting an internal dialogue. This work underscores LLMs' current limitations in geometric reasoning and improves geometric reasoning capabilities through self-correction, collaboration, and diverse role specializations.
A Simple, Yet Effective Approach to Finding Biases in Code Generation
Oct 31, 2022



Recently, scores of high-performing code generation systems have surfaced. As has become a popular choice in many domains, code generation is often approached using large language models as a core, trained under the masked or causal language modeling schema. This work shows that current code generation systems exhibit biases inherited from large language model backbones, which might leak into generated code under specific circumstances. To investigate the effect, we propose a framework that automatically removes hints and exposes various biases that these code generation models use. We apply our framework to three coding challenges and test it across top-performing coding generation models. Our experiments reveal biases towards specific prompt structure and exploitation of keywords during code generation. Finally, we demonstrate how to use our framework as a data transformation technique, which we find a promising direction toward more robust code generation.
Measuring CLEVRness: Blackbox testing of Visual Reasoning Models
Feb 28, 2022
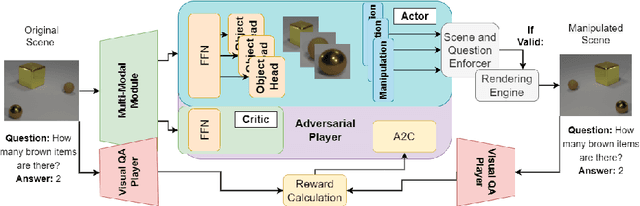
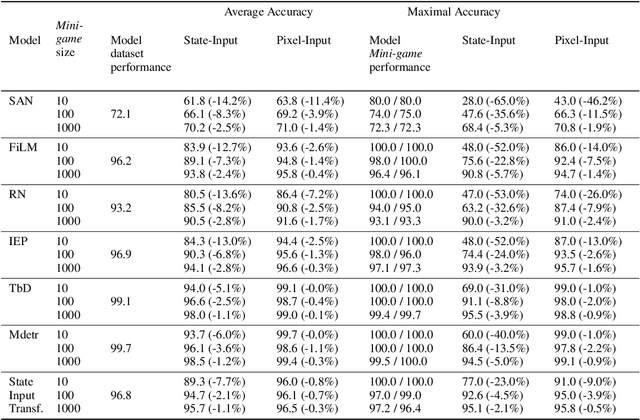
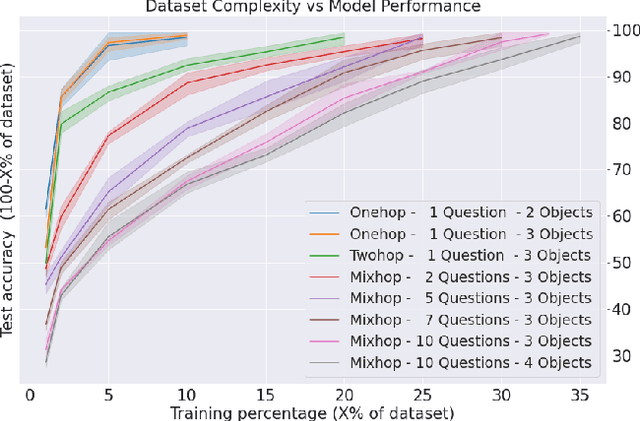
How can we measure the reasoning capabilities of intelligence systems? Visual question answering provides a convenient framework for testing the model's abilities by interrogating the model through questions about the scene. However, despite scores of various visual QA datasets and architectures, which sometimes yield even a super-human performance, the question of whether those architectures can actually reason remains open to debate. To answer this, we extend the visual question answering framework and propose the following behavioral test in the form of a two-player game. We consider black-box neural models of CLEVR. These models are trained on a diagnostic dataset benchmarking reasoning. Next, we train an adversarial player that re-configures the scene to fool the CLEVR model. We show that CLEVR models, which otherwise could perform at a human level, can easily be fooled by our agent. Our results put in doubt whether data-driven approaches can do reasoning without exploiting the numerous biases that are often present in those datasets. Finally, we also propose a controlled experiment measuring the efficiency of such models to learn and perform reasoning.
MAIN: Multihead-Attention Imputation Networks
Feb 10, 2021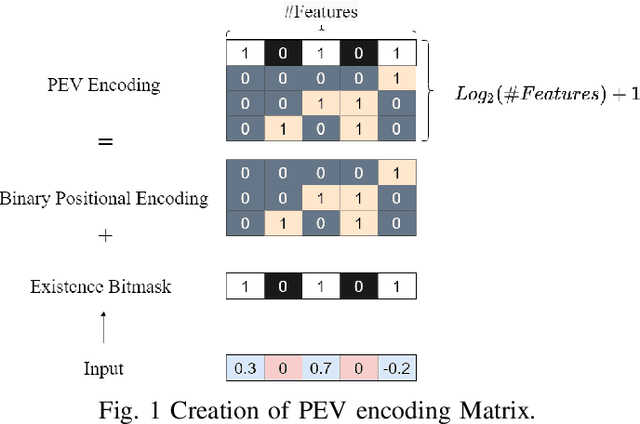
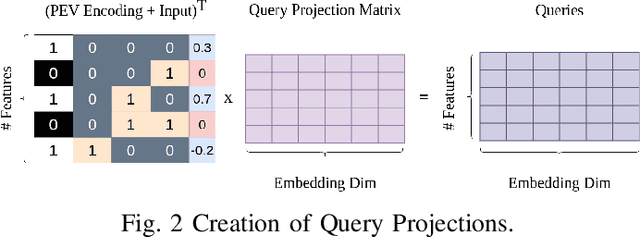
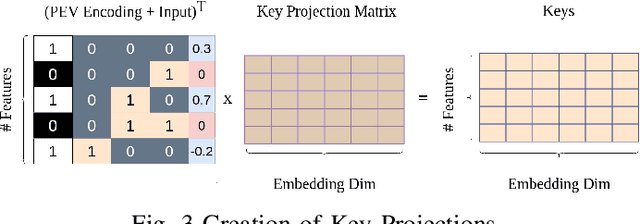
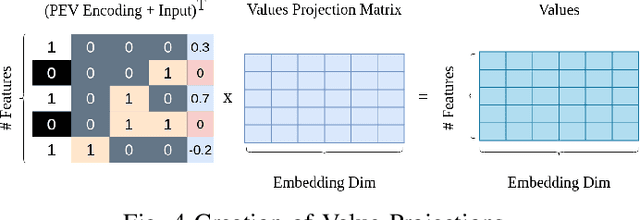
The problem of missing data, usually absent incurated and competition-standard datasets, is an unfortunate reality for most machine learning models used in industry applications. Recent work has focused on understanding the nature and the negative effects of such phenomena, while devising solutions for optimal imputation of the missing data, using both discriminative and generative approaches. We propose a novel mechanism based on multi-head attention which can be applied effortlessly in any model and achieves better downstream performance without the introduction of the full dataset in any part of the modeling pipeline. Our method inductively models patterns of missingness in the input data in order to increase the performance of the downstream task. Finally, after evaluating our method against baselines for a number of datasets, we found performance gains that tend to be larger in scenarios of high missingness.