 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAIN: Multihead-Attention Imputation Networks
Paper and Code
Feb 10, 2021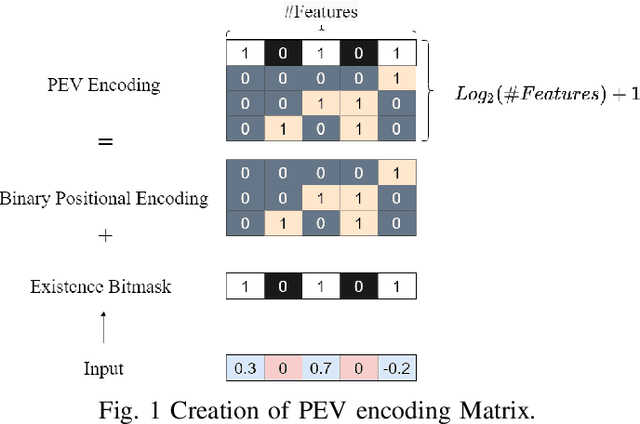
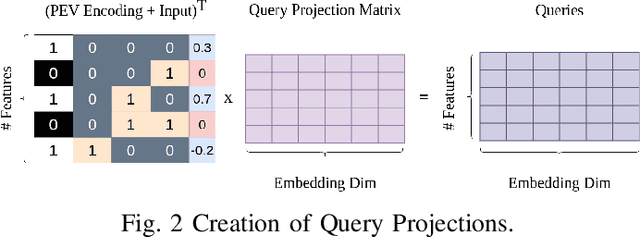
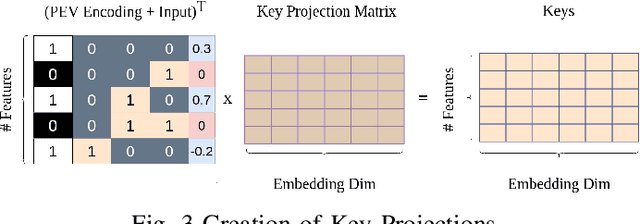
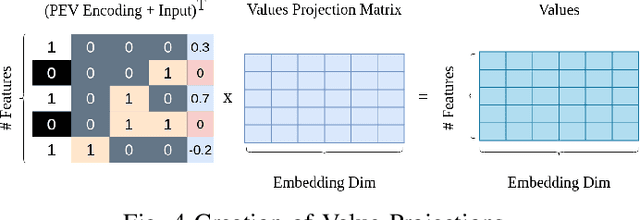
The problem of missing data, usually absent incurated and competition-standard datasets, is an unfortunate reality for most machine learning models used in industry applications. Recent work has focused on understanding the nature and the negative effects of such phenomena, while devising solutions for optimal imputation of the missing data, using both discriminative and generative approaches. We propose a novel mechanism based on multi-head attention which can be applied effortlessly in any model and achieves better downstream performance without the introduction of the full dataset in any part of the modeling pipeline. Our method inductively models patterns of missingness in the input data in order to increase the performance of the downstream task. Finally, after evaluating our method against baselines for a number of datasets, we found performance gains that tend to be larger in scenarios of high missingness.