 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable Data-Driven Ship Dynamics Model: Enhancing Physics-Based Motion Prediction with Parameter Optimization
Feb 25, 2025The deployment of autonomous navigation systems on ships necessitates accurate motion prediction models tailored to individual vessels. Traditional physics-based models, while grounded in hydrodynamic principles, often fail to account for ship-specific behaviors under real-world conditions. Conversely, purely data-driven models offer specificity but lack interpretability and robustness in edge cases. This study proposes a data-driven physics-based model that integrates physics-based equations with data-driven parameter optimization, leveraging the strengths of both approaches to ensure interpretability and adaptability. The model incorporates physics-based components such as 3-DoF dynamics, rudder, and propeller forces, while parameters such as resistance curve and rudder coefficients are optimized using synthetic data. By embedding domain knowledge into the parameter optimization process, the fitted model maintains physical consistency. Validation of the approach is realized with two container ships by comparing, both qualitatively and quantitatively, predictions against ground-truth trajectories. The results demonstrate significant improvements, in predictive accuracy and reliability, of the data-driven physics-based models over baseline physics-based models tuned with traditional marine engineering practices. The fitted models capture ship-specific behaviors in diverse conditions with their predictions being, 51.6% (ship A) and 57.8% (ship B) more accurate, 72.36% (ship A) and 89.67% (ship B) more consistent.
Towards Real-World Validation of a Physics-Based Ship Motion Prediction Model
Jan 23, 2025



The maritime industry aims towards a sustainable future, which requires significant improvements in operational efficiency. Current approaches focus on minimising fuel consumption and emissions through greater autonomy. Efficient and safe autonomous navigation requires high-fidelity ship motion models applicable to real-world conditions. Although physics-based ship motion models can predict ships' motion with sub-second resolution, their validation in real-world conditions is rarely found in the literature. This study presents a physics-based 3D dynamics motion model that is tailored to a container-ship, and compares its predictions against real-world voyages. The model integrates vessel motion over time and accounts for its hydrodynamic behavior under different environmental conditions. The model's predictions are evaluated against real vessel data both visually and using multiple distance measures. Both methodologies demonstrate that the model's predictions align closely with the real-world trajectories of the container-ship.
Shifts 2.0: Extending The Dataset of Real Distributional Shifts
Jun 30, 2022



Distributional shift, or the mismatch between training and deployment data, is a significant obstacle to the usage of machine learning in high-stakes industrial applications, such as autonomous driving and medicine. This creates a need to be able to assess how robustly ML models generalize as well as the quality of their uncertainty estimates. Standard ML baseline datasets do not allow these properties to be assessed, as the training, validation and test data are often identically distributed. Recently, a range of dedicated benchmarks have appeared, featuring both distributionally matched and shifted data. Among these benchmarks, the Shifts dataset stands out in terms of the diversity of tasks as well as the data modalities it features. While most of the benchmarks are heavily dominated by 2D image classification tasks, Shifts contains tabular weather forecasting, machine translation, and vehicle motion prediction tasks. This enables the robustness properties of models to be assessed on a diverse set of industrial-scale tasks and either universal or directly applicable task-specific conclusions to be reached. In this paper, we extend the Shifts Dataset with two datasets sourced from industrial, high-risk applications of high societal importance. Specifically, we consider the tasks of segmentation of white matter Multiple Sclerosis lesions in 3D magnetic resonance brain images and the estimation of power consumption in marine cargo vessels. Both tasks feature ubiquitous distributional shifts and a strict safety requirement due to the high cost of errors. These new datasets will allow researchers to further explore robust generalization and uncertainty estimation in new situations. In this work, we provide a description of the dataset and baseline results for both tasks.
MAIN: Multihead-Attention Imputation Networks
Feb 10, 2021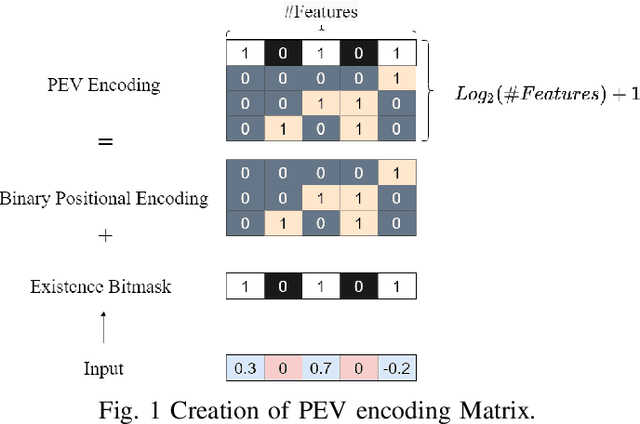
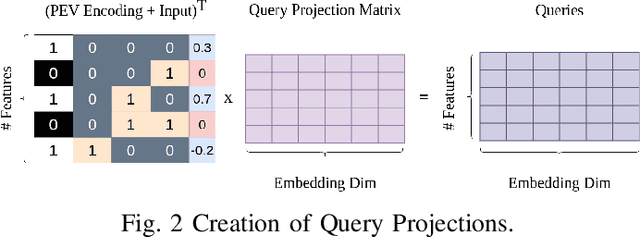
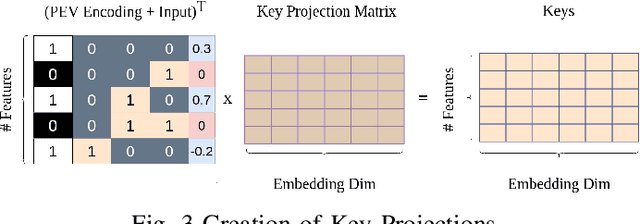
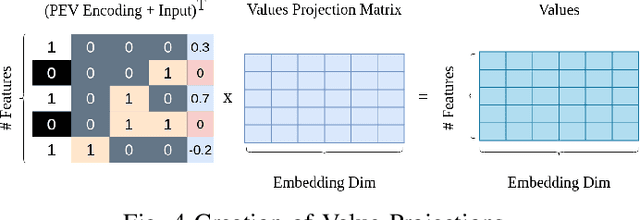
The problem of missing data, usually absent incurated and competition-standard datasets, is an unfortunate reality for most machine learning models used in industry applications. Recent work has focused on understanding the nature and the negative effects of such phenomena, while devising solutions for optimal imputation of the missing data, using both discriminative and generative approaches. We propose a novel mechanism based on multi-head attention which can be applied effortlessly in any model and achieves better downstream performance without the introduction of the full dataset in any part of the modeling pipeline. Our method inductively models patterns of missingness in the input data in order to increase the performance of the downstream task. Finally, after evaluating our method against baselines for a number of datasets, we found performance gains that tend to be larger in scenarios of high missingness.