 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAIN: Multihead-Attention Imputation Networks
Feb 10, 2021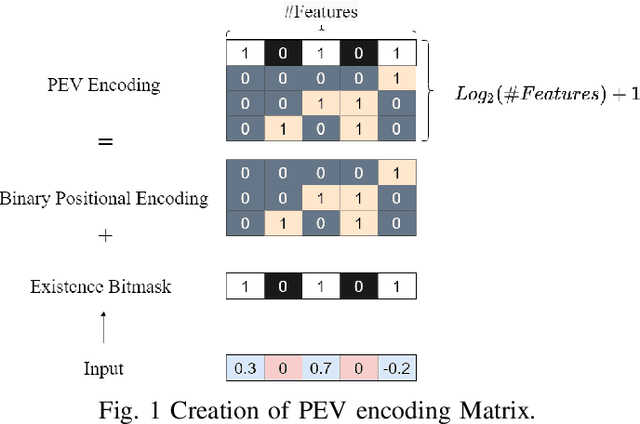
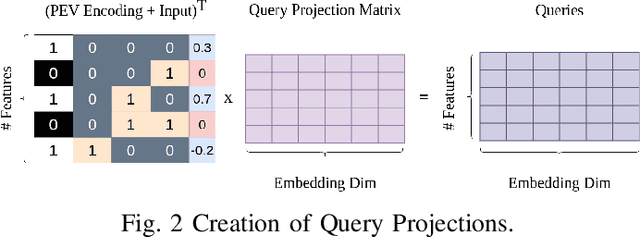
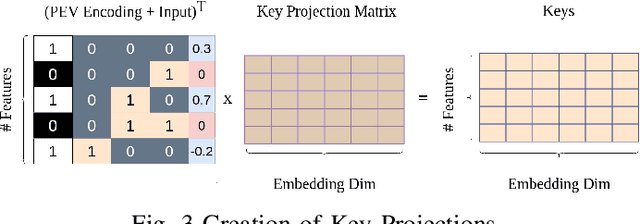
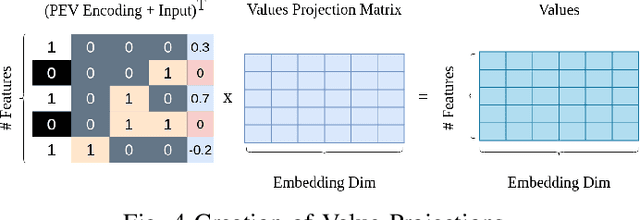
The problem of missing data, usually absent incurated and competition-standard datasets, is an unfortunate reality for most machine learning models used in industry applications. Recent work has focused on understanding the nature and the negative effects of such phenomena, while devising solutions for optimal imputation of the missing data, using both discriminative and generative approaches. We propose a novel mechanism based on multi-head attention which can be applied effortlessly in any model and achieves better downstream performance without the introduction of the full dataset in any part of the modeling pipeline. Our method inductively models patterns of missingness in the input data in order to increase the performance of the downstream task. Finally, after evaluating our method against baselines for a number of datasets, we found performance gains that tend to be larger in scenarios of high missingness.
SafePILCO: a software tool for safe and data-efficient policy synthesis
Aug 07, 2020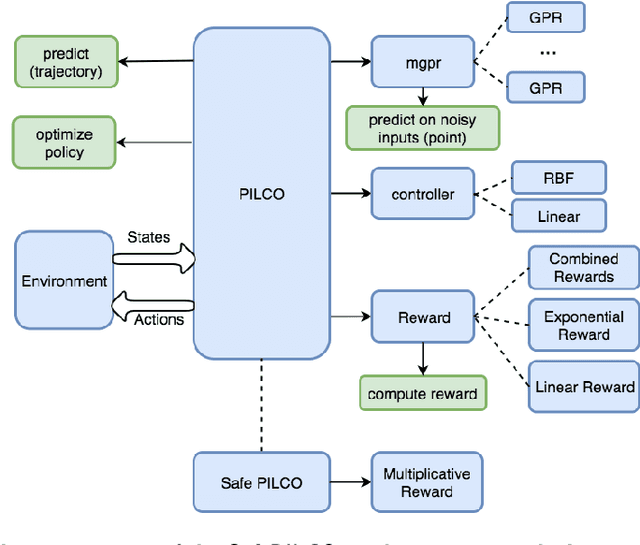
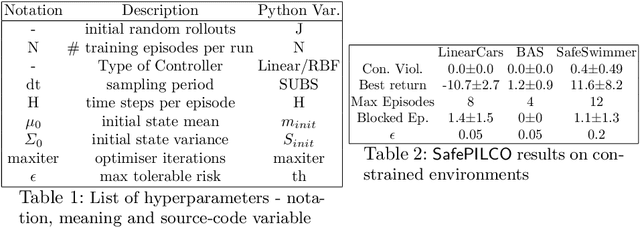
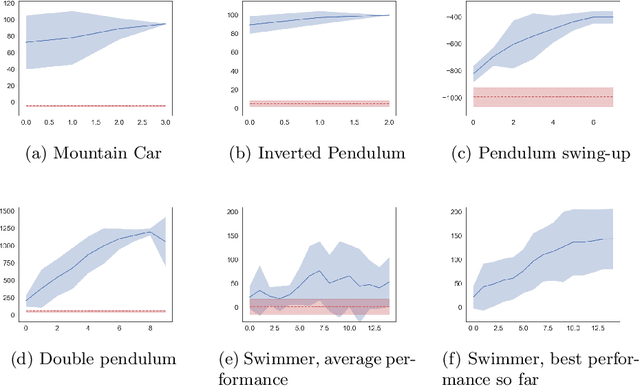
SafePILCO is a software tool for safe and data-efficient policy search with reinforcement learning. It extends the known PILCO algorithm, originally written in MATLAB, to support safe learning. We provide a Python implementation and leverage existing libraries that allow the codebase to remain short and modular, which is appropriate for wider use by the verification, reinforcement learning, and control communities.
Safety Guarantees for Planning Based on Iterative Gaussian Processes
Jan 17, 2020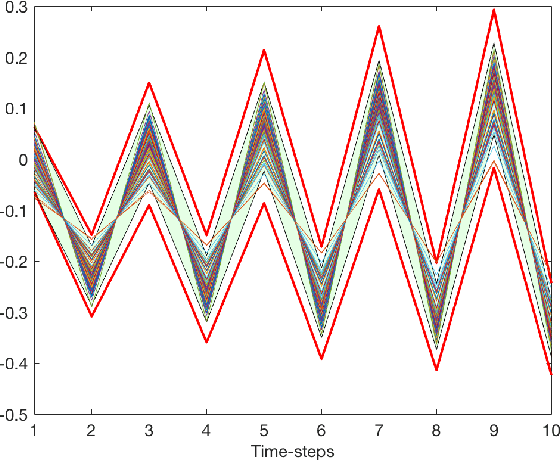
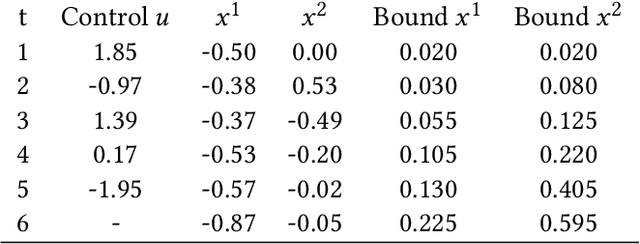
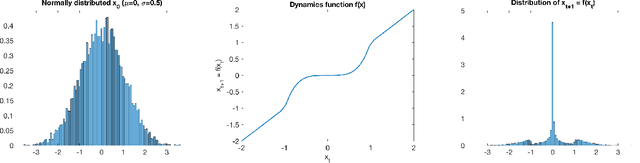
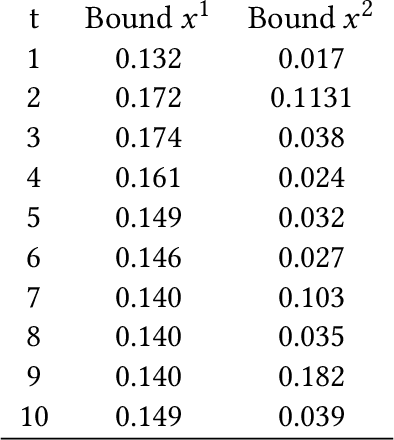
Gaussian Processes (GPs) are widely employed in control and learning because of their principled treatment of uncertainty. However, tracking uncertainty for iterative, multi-step predictions in general leads to an analytically intractable problem. While approximation methods exist, they do not come with guarantees, making it difficult to estimate their reliability and to trust their predictions. In this work, we derive formal probability error bounds for iterative prediction and planning with GPs. Building on GP properties, we bound the probability that random trajectories lie in specific regions around the predicted values. Namely, given a tolerance $\epsilon > 0 $, we compute regions around the predicted trajectory values, such that GP trajectories are guaranteed to lie inside them with probability at least $1-\epsilon$. We verify experimentally that our method tracks the predictive uncertainty correctly, even when current approximation techniques fail. Furthermore, we show how the proposed bounds can be employed within a safe reinforcement learning framework to verify the safety of candidate control policies, guiding the synthesis of provably safe controllers.
Safe Policy Search with Gaussian Process Models
Dec 15, 2017
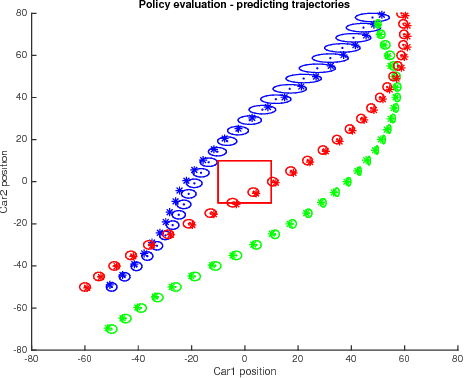
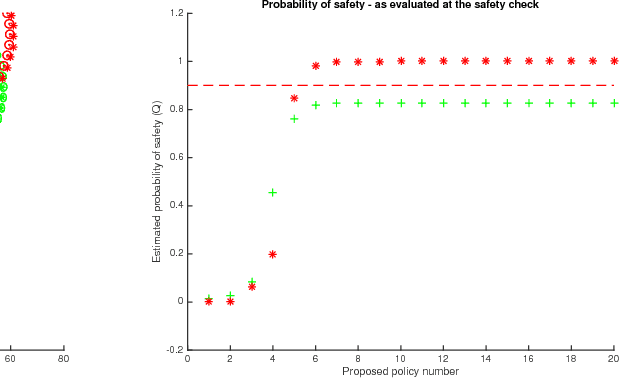
We propose a method to optimise the parameters of a policy which will be used to safely perform a given task in a data-efficient manner. We train a Gaussian process model to capture the system dynamics, based on the PILCO framework. Our model has useful analytic properties, which allow closed form computation of error gradients and estimating the probability of violating given state space constraints. During training, as well as operation, only policies that are deemed safe are implemented on the real system, minimising the risk of failure.