 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeValue-at-Risk Constrained Policy Optimization
Jan 30, 2026We introduce the Value-at-Risk Constrained Policy Optimization algorithm (VaR-CPO), a sample efficient and conservative method designed to optimize Value-at-Risk (VaR) constraints directly. Empirically, we demonstrate that VaR-CPO is capable of safe exploration, achieving zero constraint violations during training in feasible environments, a critical property that baseline methods fail to uphold. To overcome the inherent non-differentiability of the VaR constraint, we employ the one-sided Chebyshev inequality to obtain a tractable surrogate based on the first two moments of the cost return. Additionally, by extending the trust-region framework of the Constrained Policy Optimization (CPO) method, we provide rigorous worst-case bounds for both policy improvement and constraint violation during the training process.
End-to-End Policy Learning of a Statistical Arbitrage Autoencoder Architecture
Feb 13, 2024



In Statistical Arbitrage (StatArb), classical mean reversion trading strategies typically hinge on asset-pricing or PCA based models to identify the mean of a synthetic asset. Once such a (linear) model is identified, a separate mean reversion strategy is then devised to generate a trading signal. With a view of generalising such an approach and turning it truly data-driven, we study the utility of Autoencoder architectures in StatArb. As a first approach, we employ a standard Autoencoder trained on US stock returns to derive trading strategies based on the Ornstein-Uhlenbeck (OU) process. To further enhance this model, we take a policy-learning approach and embed the Autoencoder network into a neural network representation of a space of portfolio trading policies. This integration outputs portfolio allocations directly and is end-to-end trainable by backpropagation of the risk-adjusted returns of the neural policy. Our findings demonstrate that this innovative end-to-end policy learning approach not only simplifies the strategy development process, but also yields superior gross returns over its competitors illustrating the potential of end-to-end training over classical two-stage approaches.
Asynchronous Deep Double Duelling Q-Learning for Trading-Signal Execution in Limit Order Book Markets
Jan 20, 2023



We employ deep reinforcement learning (RL) to train an agent to successfully translate a high-frequency trading signal into a trading strategy that places individual limit orders. Based on the ABIDES limit order book simulator, we build a reinforcement learning OpenAI gym environment and utilise it to simulate a realistic trading environment for NASDAQ equities based on historic order book messages. To train a trading agent that learns to maximise its trading return in this environment, we use Deep Duelling Double Q-learning with the APEX (asynchronous prioritised experience replay) architecture. The agent observes the current limit order book state, its recent history, and a short-term directional forecast. To investigate the performance of RL for adaptive trading independently from a concrete forecasting algorithm, we study the performance of our approach utilising synthetic alpha signals obtained by perturbing forward-looking returns with varying levels of noise. Here, we find that the RL agent learns an effective trading strategy for inventory management and order placing that outperforms a heuristic benchmark trading strategy having access to the same signal.
Bayesian Topic Regression for Causal Inference
Sep 11, 2021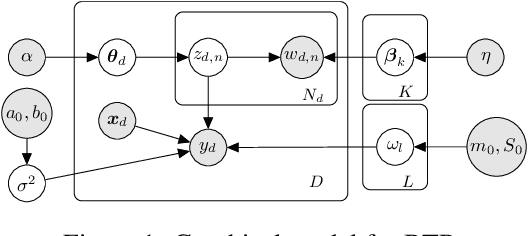
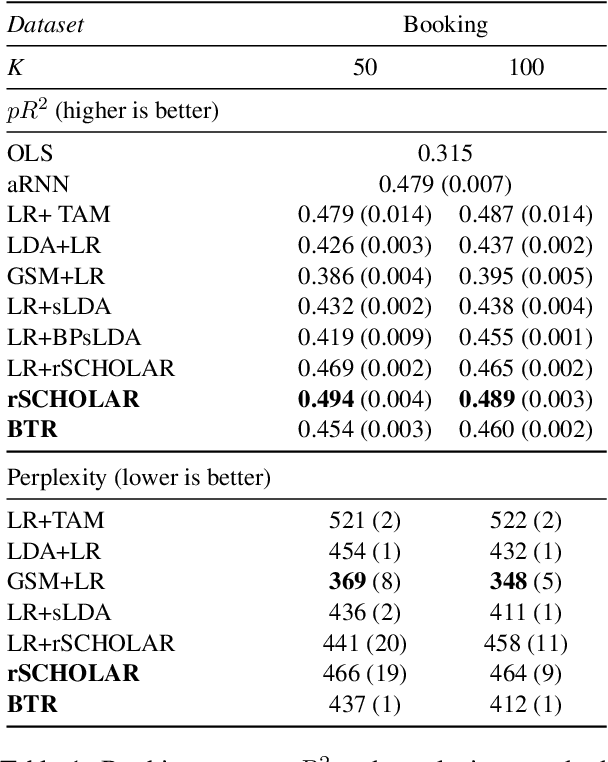
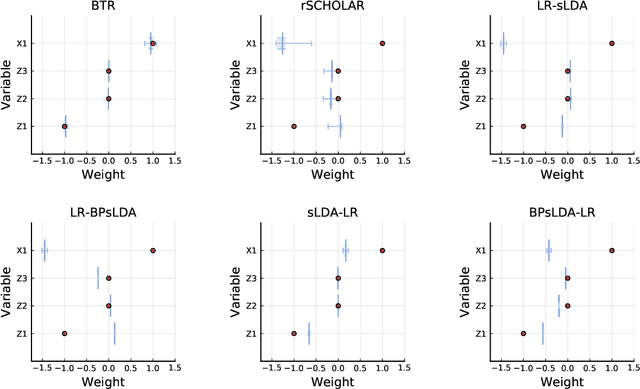
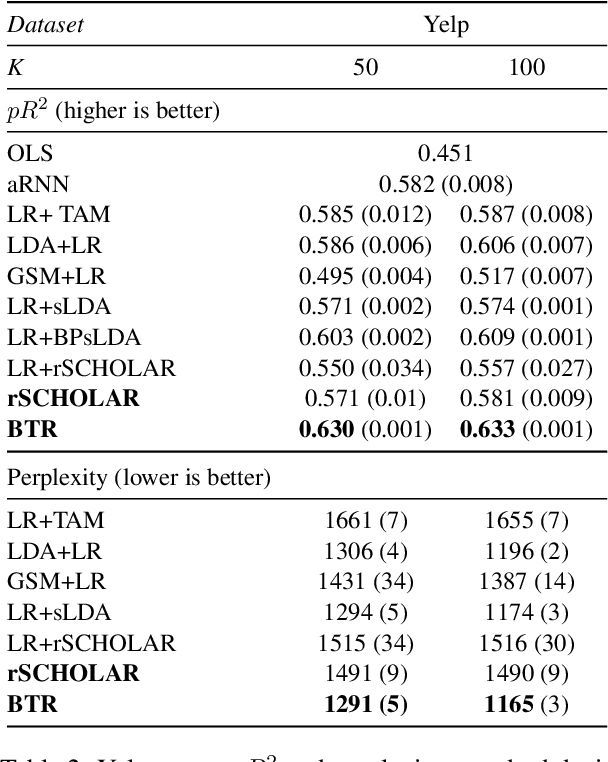
Causal inference using observational text data is becoming increasingly popular in many research areas. This paper presents the Bayesian Topic Regression (BTR) model that uses both text and numerical information to model an outcome variable. It allows estimation of both discrete and continuous treatment effects. Furthermore, it allows for the inclusion of additional numerical confounding factors next to text data. To this end, we combine a supervised Bayesian topic model with a Bayesian regression framework and perform supervised representation learning for the text features jointly with the regression parameter training, respecting the Frisch-Waugh-Lovell theorem. Our paper makes two main contributions. First, we provide a regression framework that allows causal inference in settings when both text and numerical confounders are of relevance. We show with synthetic and semi-synthetic datasets that our joint approach recovers ground truth with lower bias than any benchmark model, when text and numerical features are correlated. Second, experiments on two real-world datasets demonstrate that a joint and supervised learning strategy also yields superior prediction results compared to strategies that estimate regression weights for text and non-text features separately, being even competitive with more complex deep neural networks.
Safety Guarantees for Planning Based on Iterative Gaussian Processes
Jan 17, 2020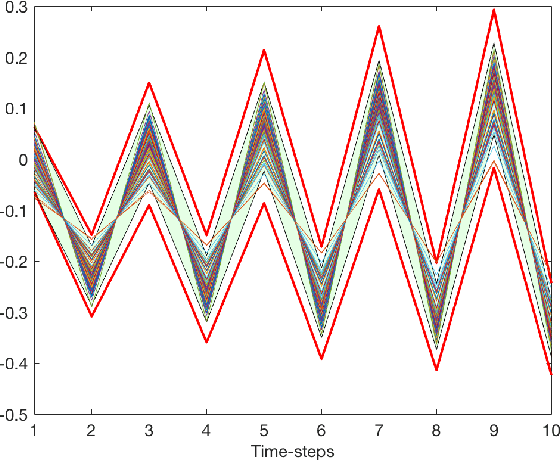
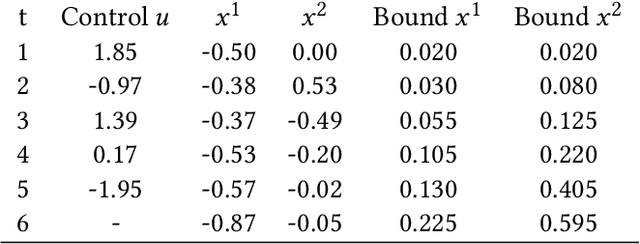
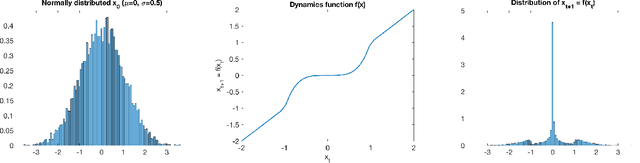
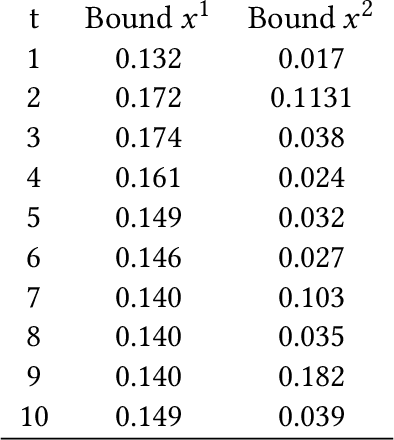
Gaussian Processes (GPs) are widely employed in control and learning because of their principled treatment of uncertainty. However, tracking uncertainty for iterative, multi-step predictions in general leads to an analytically intractable problem. While approximation methods exist, they do not come with guarantees, making it difficult to estimate their reliability and to trust their predictions. In this work, we derive formal probability error bounds for iterative prediction and planning with GPs. Building on GP properties, we bound the probability that random trajectories lie in specific regions around the predicted values. Namely, given a tolerance $\epsilon > 0 $, we compute regions around the predicted trajectory values, such that GP trajectories are guaranteed to lie inside them with probability at least $1-\epsilon$. We verify experimentally that our method tracks the predictive uncertainty correctly, even when current approximation techniques fail. Furthermore, we show how the proposed bounds can be employed within a safe reinforcement learning framework to verify the safety of candidate control policies, guiding the synthesis of provably safe controllers.
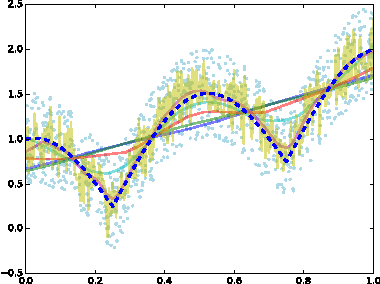
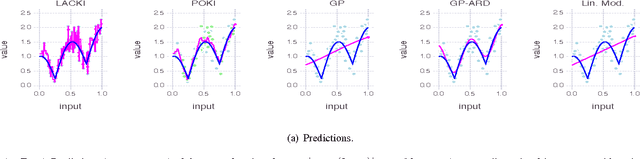
Lazily Adapted Constant Kinky Inference for Nonparametric Regression and Model-Reference Adaptive Control
Apr 12, 2018

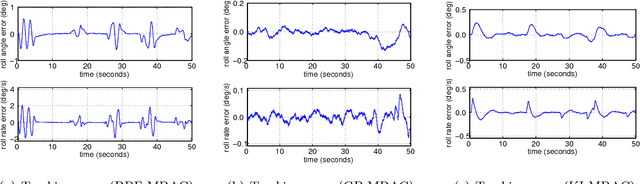

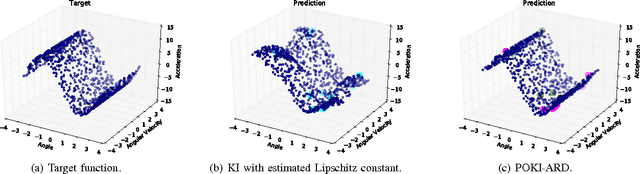
Techniques known as Nonlinear Set Membership prediction, Lipschitz Interpolation or Kinky Inference are approaches to machine learning that utilise presupposed Lipschitz properties to compute inferences over unobserved function values. Provided a bound on the true best Lipschitz constant of the target function is known a priori they offer convergence guarantees as well as bounds around the predictions. Considering a more general setting that builds on Hoelder continuity relative to pseudo-metrics, we propose an online method for estimating the Hoelder constant online from function value observations that possibly are corrupted by bounded observational errors. Utilising this to compute adaptive parameters within a kinky inference rule gives rise to a nonparametric machine learning method, for which we establish strong universal approximation guarantees. That is, we show that our prediction rule can learn any continuous function in the limit of increasingly dense data to within a worst-case error bound that depends on the level of observational uncertainty. We apply our method in the context of nonparametric model-reference adaptive control (MRAC). Across a range of simulated aircraft roll-dynamics and performance metrics our approach outperforms recently proposed alternatives that were based on Gaussian processes and RBF-neural networks. For discrete-time systems, we provide guarantees on the tracking success of our learning-based controllers both for the batch and the online learning setting.
Lipschitz Optimisation for Lipschitz Interpolation
Feb 28, 2017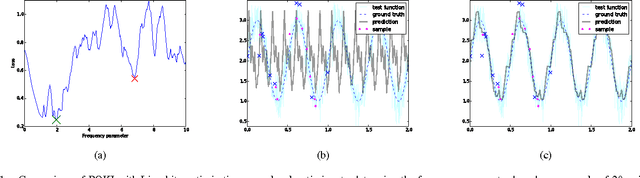
Techniques known as Nonlinear Set Membership prediction, Kinky Inference or Lipschitz Interpolation are fast and numerically robust approaches to nonparametric machine learning that have been proposed to be utilised in the context of system identification and learning-based control. They utilise presupposed Lipschitz properties in order to compute inferences over unobserved function values. Unfortunately, most of these approaches rely on exact knowledge about the input space metric as well as about the Lipschitz constant. Furthermore, existing techniques to estimate the Lipschitz constants from the data are not robust to noise or seem to be ad-hoc and typically are decoupled from the ultimate learning and prediction task. To overcome these limitations, we propose an approach for optimising parameters of the presupposed metrics by minimising validation set prediction errors. To avoid poor performance due to local minima, we propose to utilise Lipschitz properties of the optimisation objective to ensure global optimisation success. The resulting approach is a new flexible method for nonparametric black-box learning. We provide experimental evidence of the competitiveness of our approach on artificial as well as on real data.
Conservative collision prediction and avoidance for stochastic trajectories in continuous time and space
May 12, 2014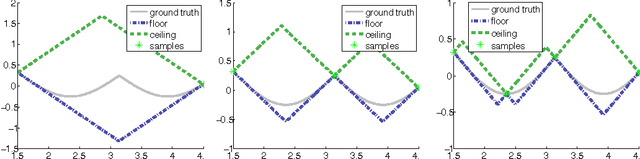

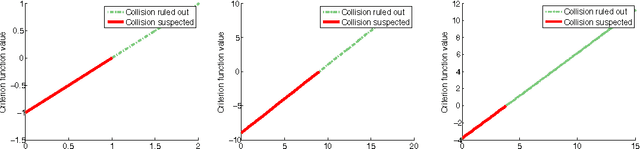
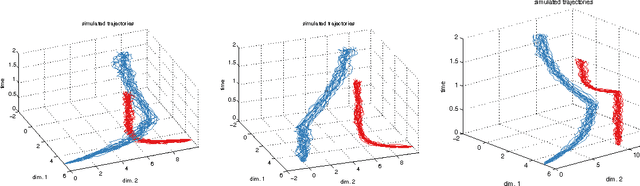
Existing work in multi-agent collision prediction and avoidance typically assumes discrete-time trajectories with Gaussian uncertainty or that are completely deterministic. We propose an approach that allows detection of collisions even between continuous, stochastic trajectories with the only restriction that means and variances can be computed. To this end, we employ probabilistic bounds to derive criterion functions whose negative sign provably is indicative of probable collisions. For criterion functions that are Lipschitz, an algorithm is provided to rapidly find negative values or prove their absence. We propose an iterative policy-search approach that avoids prior discretisations and yields collision-free trajectories with adjustably high certainty. We test our method with both fixed-priority and auction-based protocols for coordinating the iterative planning process. Results are provided in collision-avoidance simulations of feedback controlled plants.
Stochastic processes and feedback-linearisation for online identification and Bayesian adaptive control of fully-actuated mechanical systems
Apr 01, 2014
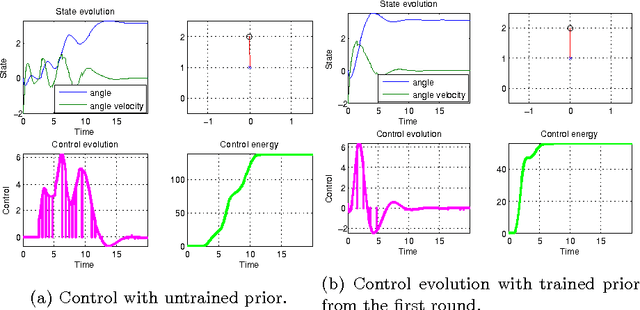

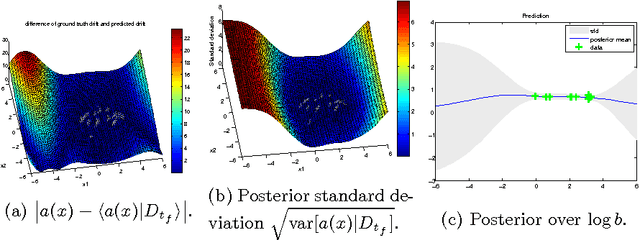
This work proposes a new method for simultaneous probabilistic identification and control of an observable, fully-actuated mechanical system. Identification is achieved by conditioning stochastic process priors on observations of configurations and noisy estimates of configuration derivatives. In contrast to previous work that has used stochastic processes for identification, we leverage the structural knowledge afforded by Lagrangian mechanics and learn the drift and control input matrix functions of the control-affine system separately. We utilise feedback-linearisation to reduce, in expectation, the uncertain nonlinear control problem to one that is easy to regulate in a desired manner. Thereby, our method combines the flexibility of nonparametric Bayesian learning with epistemological guarantees on the expected closed-loop trajectory. We illustrate our method in the context of torque-actuated pendula where the dynamics are learned with a combination of normal and log-normal processes.