 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Large Language Models for Qualitative Analysis can Introduce Serious Bias
Oct 05, 2023Large Language Models (LLMs) are quickly becoming ubiquitous, but the implications for social science research are not yet well understood. This paper asks whether LLMs can help us analyse large-N qualitative data from open-ended interviews, with an application to transcripts of interviews with Rohingya refugees in Cox's Bazaar, Bangladesh. We find that a great deal of caution is needed in using LLMs to annotate text as there is a risk of introducing biases that can lead to misleading inferences. We here mean bias in the technical sense, that the errors that LLMs make in annotating interview transcripts are not random with respect to the characteristics of the interview subjects. Training simpler supervised models on high-quality human annotations with flexible coding leads to less measurement error and bias than LLM annotations. Therefore, given that some high quality annotations are necessary in order to asses whether an LLM introduces bias, we argue that it is probably preferable to train a bespoke model on these annotations than it is to use an LLM for annotation.
Bayesian Topic Regression for Causal Inference
Sep 11, 2021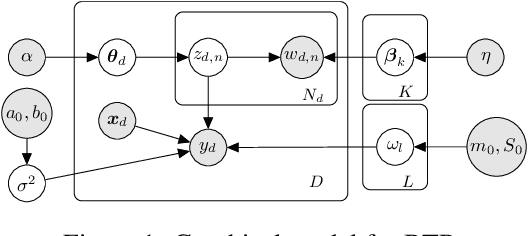
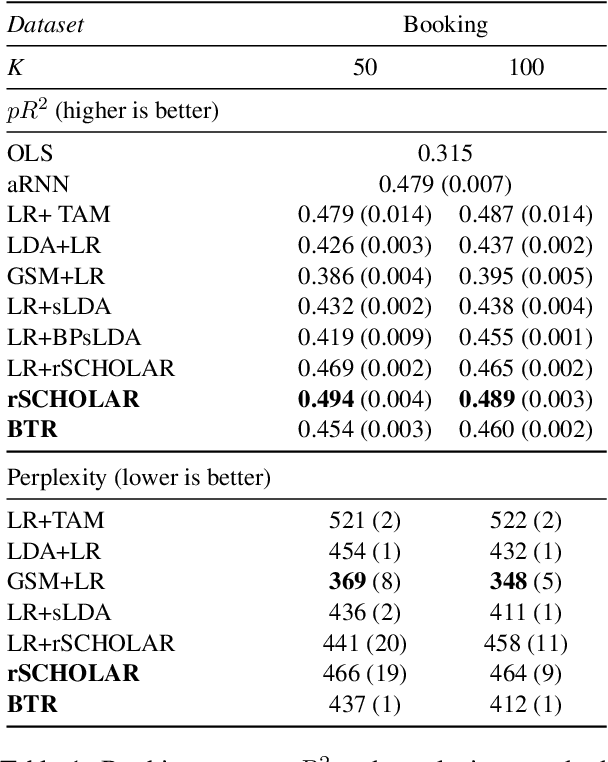
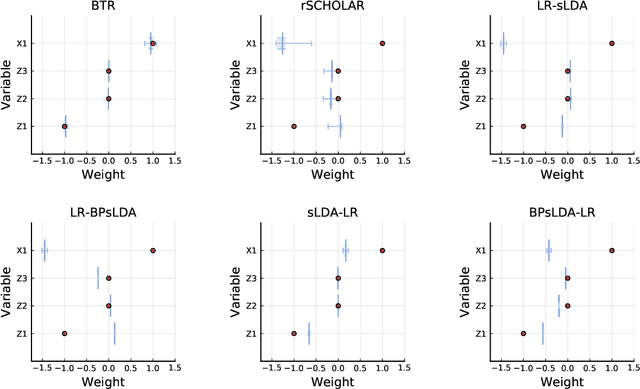
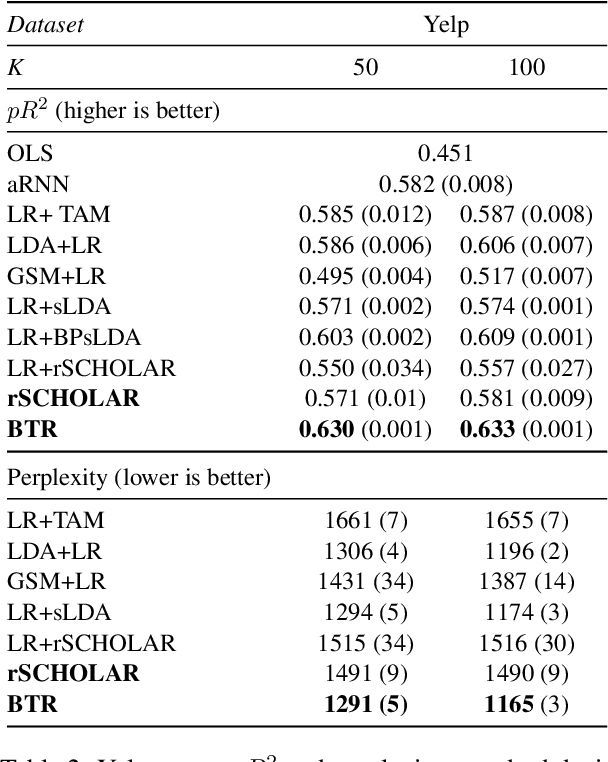
Causal inference using observational text data is becoming increasingly popular in many research areas. This paper presents the Bayesian Topic Regression (BTR) model that uses both text and numerical information to model an outcome variable. It allows estimation of both discrete and continuous treatment effects. Furthermore, it allows for the inclusion of additional numerical confounding factors next to text data. To this end, we combine a supervised Bayesian topic model with a Bayesian regression framework and perform supervised representation learning for the text features jointly with the regression parameter training, respecting the Frisch-Waugh-Lovell theorem. Our paper makes two main contributions. First, we provide a regression framework that allows causal inference in settings when both text and numerical confounders are of relevance. We show with synthetic and semi-synthetic datasets that our joint approach recovers ground truth with lower bias than any benchmark model, when text and numerical features are correlated. Second, experiments on two real-world datasets demonstrate that a joint and supervised learning strategy also yields superior prediction results compared to strategies that estimate regression weights for text and non-text features separately, being even competitive with more complex deep neural networks.