 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShifts 2.0: Extending The Dataset of Real Distributional Shifts
Jun 30, 2022



Distributional shift, or the mismatch between training and deployment data, is a significant obstacle to the usage of machine learning in high-stakes industrial applications, such as autonomous driving and medicine. This creates a need to be able to assess how robustly ML models generalize as well as the quality of their uncertainty estimates. Standard ML baseline datasets do not allow these properties to be assessed, as the training, validation and test data are often identically distributed. Recently, a range of dedicated benchmarks have appeared, featuring both distributionally matched and shifted data. Among these benchmarks, the Shifts dataset stands out in terms of the diversity of tasks as well as the data modalities it features. While most of the benchmarks are heavily dominated by 2D image classification tasks, Shifts contains tabular weather forecasting, machine translation, and vehicle motion prediction tasks. This enables the robustness properties of models to be assessed on a diverse set of industrial-scale tasks and either universal or directly applicable task-specific conclusions to be reached. In this paper, we extend the Shifts Dataset with two datasets sourced from industrial, high-risk applications of high societal importance. Specifically, we consider the tasks of segmentation of white matter Multiple Sclerosis lesions in 3D magnetic resonance brain images and the estimation of power consumption in marine cargo vessels. Both tasks feature ubiquitous distributional shifts and a strict safety requirement due to the high cost of errors. These new datasets will allow researchers to further explore robust generalization and uncertainty estimation in new situations. In this work, we provide a description of the dataset and baseline results for both tasks.
MAIN: Multihead-Attention Imputation Networks
Feb 10, 2021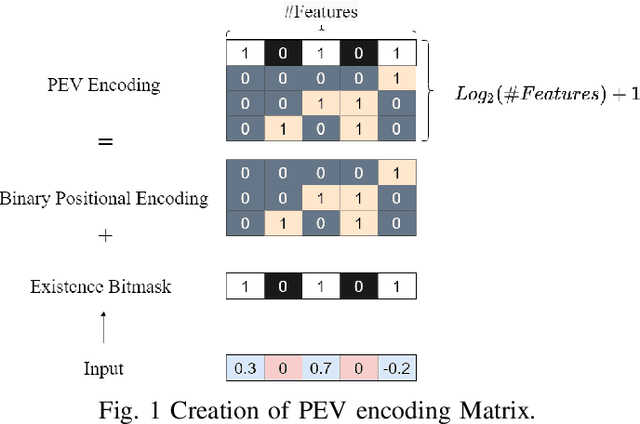
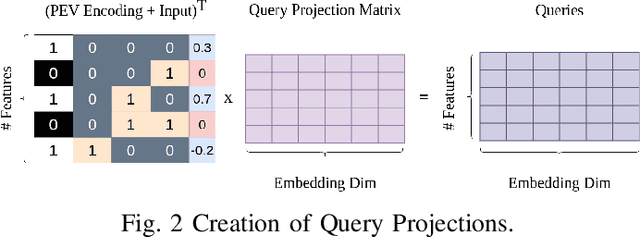
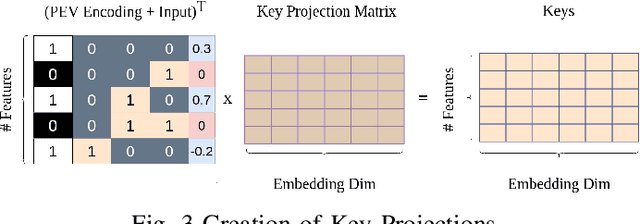
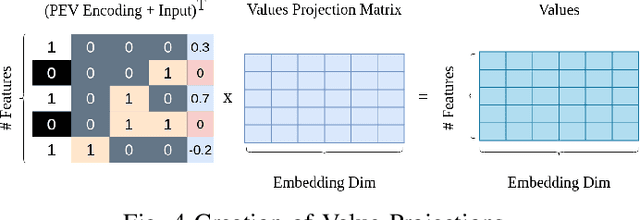
The problem of missing data, usually absent incurated and competition-standard datasets, is an unfortunate reality for most machine learning models used in industry applications. Recent work has focused on understanding the nature and the negative effects of such phenomena, while devising solutions for optimal imputation of the missing data, using both discriminative and generative approaches. We propose a novel mechanism based on multi-head attention which can be applied effortlessly in any model and achieves better downstream performance without the introduction of the full dataset in any part of the modeling pipeline. Our method inductively models patterns of missingness in the input data in order to increase the performance of the downstream task. Finally, after evaluating our method against baselines for a number of datasets, we found performance gains that tend to be larger in scenarios of high missingness.
Tensor-Based Classifiers for Hyperspectral Data Analysis
Jul 03, 2018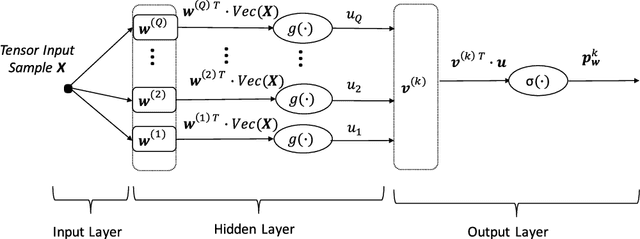
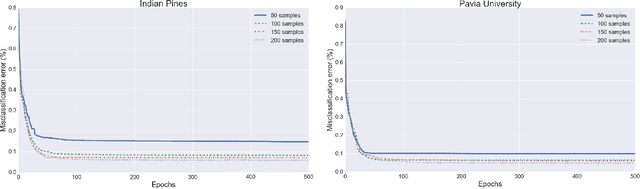
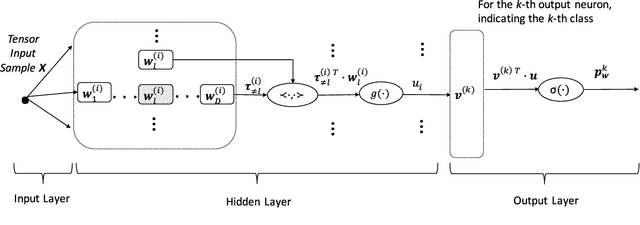
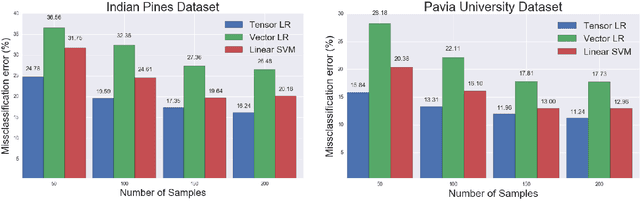
In this work, we present tensor-based linear and nonlinear models for hyperspectral data classification and analysis. By exploiting principles of tensor algebra, we introduce new classification architectures, the weight parameters of which satisfies the {\it rank}-1 canonical decomposition property. Then, we introduce learning algorithms to train both the linear and the non-linear classifier in a way to i) to minimize the error over the training samples and ii) the weight coefficients satisfies the {\it rank}-1 canonical decomposition property. The advantages of the proposed classification model is that i) it reduces the number of parameters required and thus reduces the respective number of training samples required to properly train the model, ii) it provides a physical interpretation regarding the model coefficients on the classification output and iii) it retains the spatial and spectral coherency of the input samples. To address issues related with linear classification, characterizing by low capacity, since it can produce rules that are linear in the input space, we introduce non-linear classification models based on a modification of a feedforward neural network. We call the proposed architecture {\it rank}-1 Feedfoward Neural Network (FNN), since their weights satisfy the {\it rank}-1 caconical decomposition property. Appropriate learning algorithms are also proposed to train the network. Experimental results and comparisons with state of the art classification methods, either linear (e.g., SVM) and non-linear (e.g., deep learning) indicates the outperformance of the proposed scheme, especially in cases where a small number of training samples are available. Furthermore, the proposed tensor-based classfiers are evaluated against their capabilities in dimensionality reduction.
Tensor-based Nonlinear Classifier for High-Order Data Analysis
Feb 15, 2018

In this paper we propose a tensor-based nonlinear model for high-order data classification. The advantages of the proposed scheme are that (i) it significantly reduces the number of weight parameters, and hence of required training samples, and (ii) it retains the spatial structure of the input samples. The proposed model, called \textit{Rank}-1 FNN, is based on a modification of a feedforward neural network (FNN), such that its weights satisfy the {\it rank}-1 canonical decomposition. We also introduce a new learning algorithm to train the model, and we evaluate the \textit{Rank}-1 FNN on third-order hyperspectral data. Experimental results and comparisons indicate that the proposed model outperforms state of the art classification methods, including deep learning based ones, especially in cases with small numbers of available training samples.
Data-Driven Background Subtraction Algorithm for in-Camera Acceleration in Thermal Imagery
Oct 15, 2017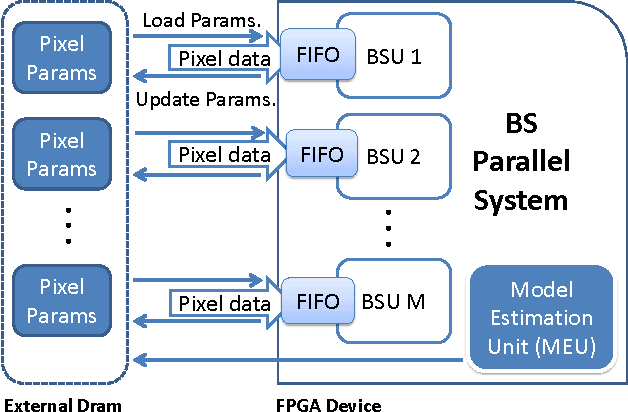
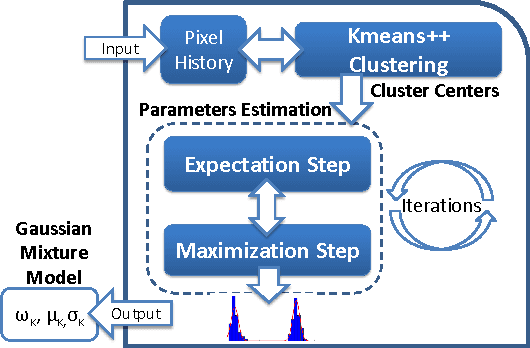
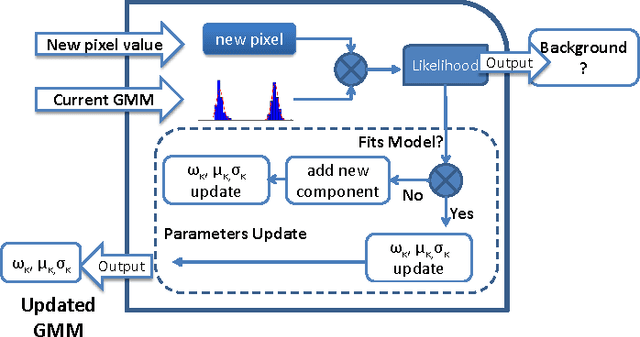

Detection of moving objects in videos is a crucial step towards successful surveillance and monitoring applications. A key component for such tasks is called background subtraction and tries to extract regions of interest from the image background for further processing or action. For this reason, its accuracy and real-time performance is of great significance. Although, effective background subtraction methods have been proposed, only a few of them take into consideration the special characteristics of thermal imagery. In this work, we propose a background subtraction scheme, which models the thermal responses of each pixel as a mixture of Gaussians with unknown number of components. Following a Bayesian approach, our method automatically estimates the mixture structure, while simultaneously it avoids over/under fitting. The pixel density estimate is followed by an efficient and highly accurate updating mechanism, which permits our system to be automatically adapted to dynamically changing operation conditions. We propose a reference implementation of our method in reconfigurable hardware achieving both adequate performance and low power consumption. Adopting a High Level Synthesis design, demanding floating point arithmetic operations are mapped in reconfigurable hardware; demonstrating fast-prototyping and on-field customization at the same time.
* 15 pages. arXiv admin note: text overlap with arXiv:1506.08581