 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Object Detection with Privileged Information: A Model-Agnostic Teacher-Student Approach
Jan 05, 2026This paper investigates the integration of the Learning Using Privileged Information (LUPI) paradigm in object detection to exploit fine-grained, descriptive information available during training but not at inference. We introduce a general, model-agnostic methodology for injecting privileged information-such as bounding box masks, saliency maps, and depth cues-into deep learning-based object detectors through a teacher-student architecture. Experiments are conducted across five state-of-the-art object detection models and multiple public benchmarks, including UAV-based litter detection datasets and Pascal VOC 2012, to assess the impact on accuracy, generalization, and computational efficiency. Our results demonstrate that LUPI-trained students consistently outperform their baseline counterparts, achieving significant boosts in detection accuracy with no increase in inference complexity or model size. Performance improvements are especially marked for medium and large objects, while ablation studies reveal that intermediate weighting of teacher guidance optimally balances learning from privileged and standard inputs. The findings affirm that the LUPI framework provides an effective and practical strategy for advancing object detection systems in both resource-constrained and real-world settings.
Learning using privileged information for segmenting tumors on digital mammograms
Feb 09, 2024

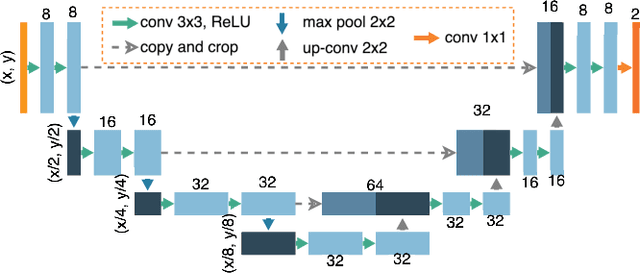

Limited amount of data and data sharing restrictions, due to GDPR compliance, constitute two common factors leading to reduced availability and accessibility when referring to medical data. To tackle these issues, we introduce the technique of Learning Using Privileged Information. Aiming to substantiate the idea, we attempt to build a robust model that improves the segmentation quality of tumors on digital mammograms, by gaining privileged information knowledge during the training procedure. Towards this direction, a baseline model, called student, is trained on patches extracted from the original mammograms, while an auxiliary model with the same architecture, called teacher, is trained on the corresponding enhanced patches accessing, in this way, privileged information. We repeat the student training procedure by providing the assistance of the teacher model this time. According to the experimental results, it seems that the proposed methodology performs better in the most of the cases and it can achieve 10% higher F1 score in comparison with the baseline.
Simulator-Free Visual Domain Randomization via Video Games
Feb 02, 2024Domain randomization is an effective computer vision technique for improving transferability of vision models across visually distinct domains exhibiting similar content. Existing approaches, however, rely extensively on tweaking complex and specialized simulation engines that are difficult to construct, subsequently affecting their feasibility and scalability. This paper introduces BehAVE, a video understanding framework that uniquely leverages the plethora of existing commercial video games for domain randomization, without requiring access to their simulation engines. Under BehAVE (1) the inherent rich visual diversity of video games acts as the source of randomization and (2) player behavior -- represented semantically via textual descriptions of actions -- guides the *alignment* of videos with similar content. We test BehAVE on 25 games of the first-person shooter (FPS) genre across various video and text foundation models and we report its robustness for domain randomization. BehAVE successfully aligns player behavioral patterns and is able to zero-shot transfer them to multiple unseen FPS games when trained on just one FPS game. In a more challenging setting, BehAVE manages to improve the zero-shot transferability of foundation models to unseen FPS games (up to 22%) even when trained on a game of a different genre (Minecraft). Code and dataset can be found at https://github.com/nrasajski/BehAVE.
Towards General Game Representations: Decomposing Games Pixels into Content and Style
Jul 20, 2023On-screen game footage contains rich contextual information that players process when playing and experiencing a game. Learning pixel representations of games can benefit artificial intelligence across several downstream tasks including game-playing agents, procedural content generation, and player modelling. The generalizability of these methods, however, remains a challenge, as learned representations should ideally be shared across games with similar game mechanics. This could allow, for instance, game-playing agents trained on one game to perform well in similar games with no re-training. This paper explores how generalizable pre-trained computer vision encoders can be for such tasks, by decomposing the latent space into content embeddings and style embeddings. The goal is to minimize the domain gap between games of the same genre when it comes to game content critical for downstream tasks, and ignore differences in graphical style. We employ a pre-trained Vision Transformer encoder and a decomposition technique based on game genres to obtain separate content and style embeddings. Our findings show that the decomposed embeddings achieve style invariance across multiple games while still maintaining strong content extraction capabilities. We argue that the proposed decomposition of content and style offers better generalization capacities across game environments independently of the downstream task.
From the Lab to the Wild: Affect Modeling via Privileged Information
May 18, 2023
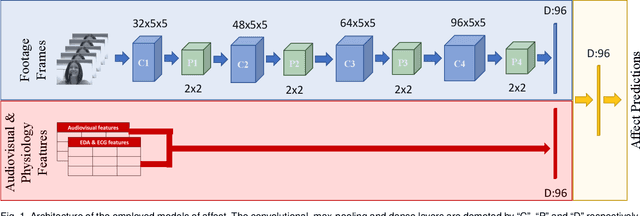
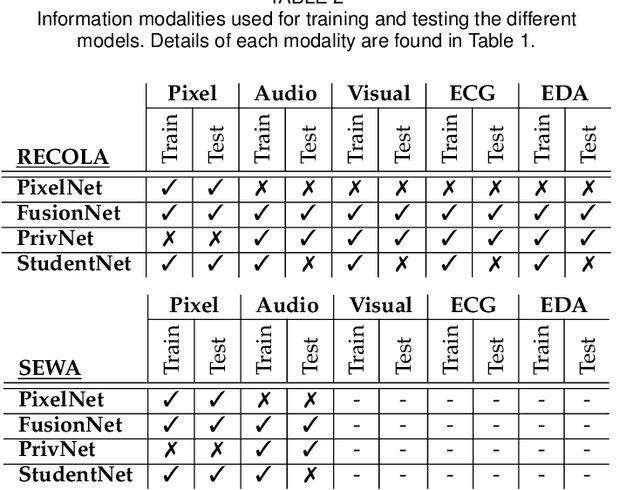
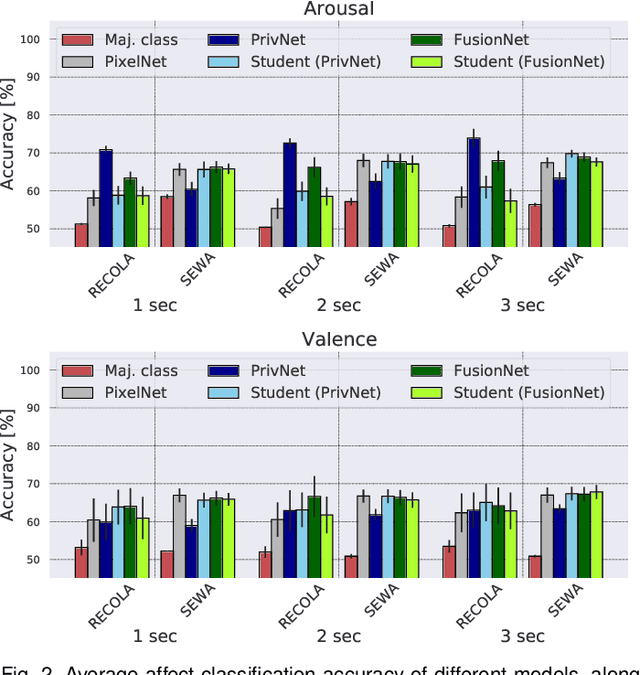
How can we reliably transfer affect models trained in controlled laboratory conditions (in-vitro) to uncontrolled real-world settings (in-vivo)? The information gap between in-vitro and in-vivo applications defines a core challenge of affective computing. This gap is caused by limitations related to affect sensing including intrusiveness, hardware malfunctions and availability of sensors. As a response to these limitations, we introduce the concept of privileged information for operating affect models in real-world scenarios (in the wild). Privileged information enables affect models to be trained across multiple modalities available in a lab, and ignore, without significant performance drops, those modalities that are not available when they operate in the wild. Our approach is tested in two multimodal affect databases one of which is designed for testing models of affect in the wild. By training our affect models using all modalities and then using solely raw footage frames for testing the models, we reach the performance of models that fuse all available modalities for both training and testing. The results are robust across both classification and regression affect modeling tasks which are dominant paradigms in affective computing. Our findings make a decisive step towards realizing affect interaction in the wild.
The Invariant Ground Truth of Affect
Oct 14, 2022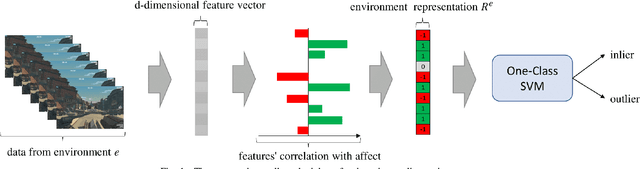

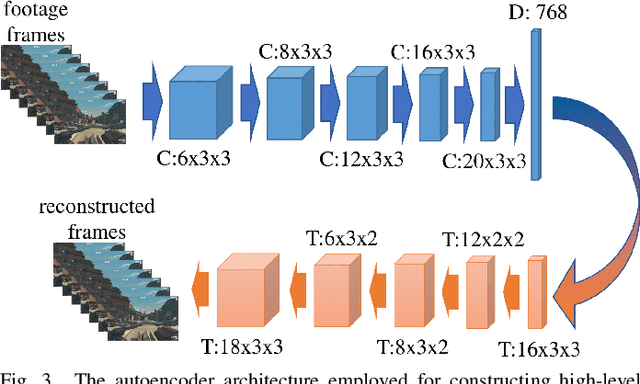
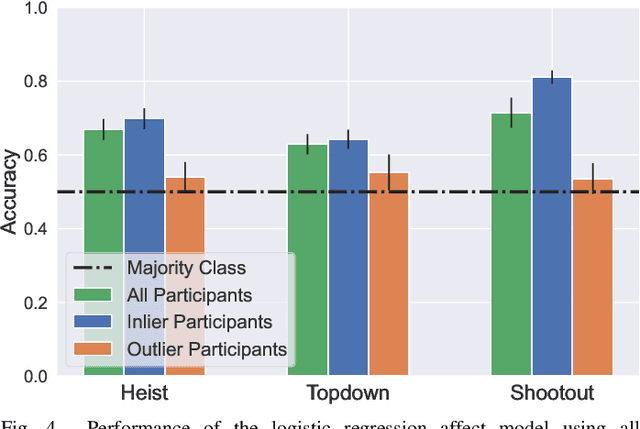
Affective computing strives to unveil the unknown relationship between affect elicitation, manifestation of affect and affect annotations. The ground truth of affect, however, is predominately attributed to the affect labels which inadvertently include biases inherent to the subjective nature of emotion and its labeling. The response to such limitations is usually augmenting the dataset with more annotations per data point; however, this is not possible when we are interested in self-reports via first-person annotation. Moreover, outlier detection methods based on inter-annotator agreement only consider the annotations themselves and ignore the context and the corresponding affect manifestation. This paper reframes the ways one may obtain a reliable ground truth of affect by transferring aspects of causation theory to affective computing. In particular, we assume that the ground truth of affect can be found in the causal relationships between elicitation, manifestation and annotation that remain \emph{invariant} across tasks and participants. To test our assumption we employ causation inspired methods for detecting outliers in affective corpora and building affect models that are robust across participants and tasks. We validate our methodology within the domain of digital games, with experimental results showing that it can successfully detect outliers and boost the accuracy of affect models. To the best of our knowledge, this study presents the first attempt to integrate causation tools in affective computing, making a crucial and decisive step towards general affect modeling.
Supervised Contrastive Learning for Affect Modelling
Aug 25, 2022

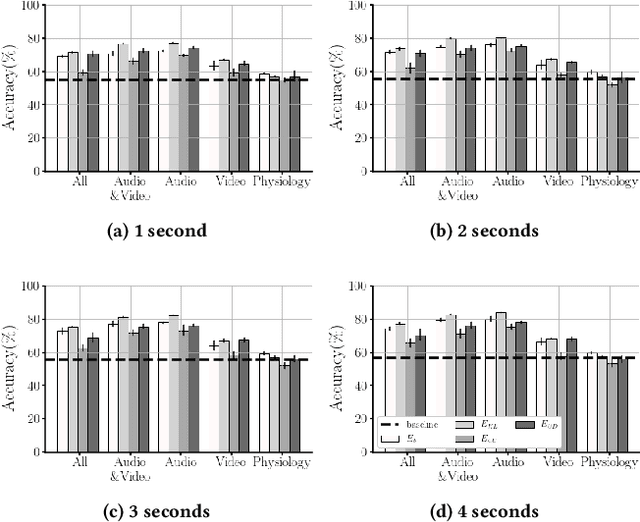
Affect modeling is viewed, traditionally, as the process of mapping measurable affect manifestations from multiple modalities of user input to affect labels. That mapping is usually inferred through end-to-end (manifestation-to-affect) machine learning processes. What if, instead, one trains general, subject-invariant representations that consider affect information and then uses such representations to model affect? In this paper we assume that affect labels form an integral part, and not just the training signal, of an affect representation and we explore how the recent paradigm of contrastive learning can be employed to discover general high-level affect-infused representations for the purpose of modeling affect. We introduce three different supervised contrastive learning approaches for training representations that consider affect information. In this initial study we test the proposed methods for arousal prediction in the RECOLA dataset based on user information from multiple modalities. Results demonstrate the representation capacity of contrastive learning and its efficiency in boosting the accuracy of affect models. Beyond their evidenced higher performance compared to end-to-end arousal classification, the resulting representations are general-purpose and subject-agnostic, as training is guided though general affect information available in any multimodal corpus.
Game State Learning via Game Scene Augmentation
Jul 08, 2022

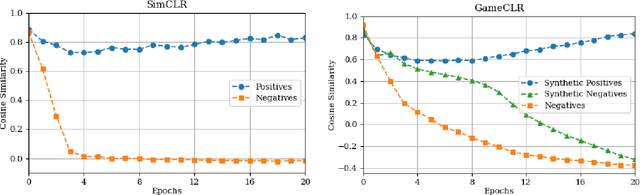

Having access to accurate game state information is of utmost importance for any artificial intelligence task including game-playing, testing, player modeling, and procedural content generation. Self-Supervised Learning (SSL) techniques have shown to be capable of inferring accurate game state information from the high-dimensional pixel input of game footage into compressed latent representations. Contrastive Learning is a popular SSL paradigm where the visual understanding of the game's images comes from contrasting dissimilar and similar game states defined by simple image augmentation methods. In this study, we introduce a new game scene augmentation technique -- named GameCLR -- that takes advantage of the game-engine to define and synthesize specific, highly-controlled renderings of different game states, thereby, boosting contrastive learning performance. We test our GameCLR technique on images of the CARLA driving simulator environment and compare it against the popular SimCLR baseline SSL method. Our results suggest that GameCLR can infer the game's state information from game footage more accurately compared to the baseline. Our proposed approach allows us to conduct game artificial intelligence research by directly utilizing screen pixels as input.
Automatic inspection of cultural monuments using deep and tensor-based learning on hyperspectral imagery
Jul 05, 2022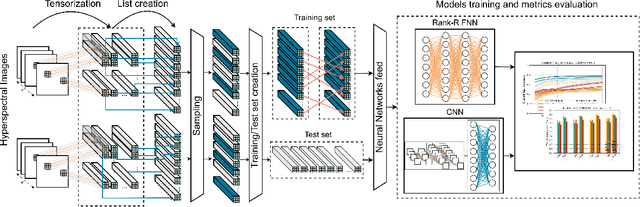
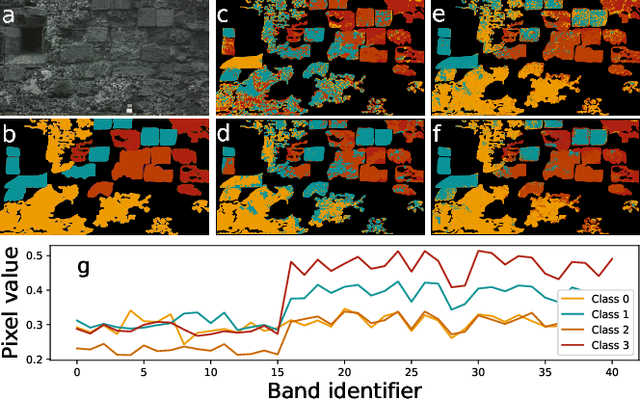
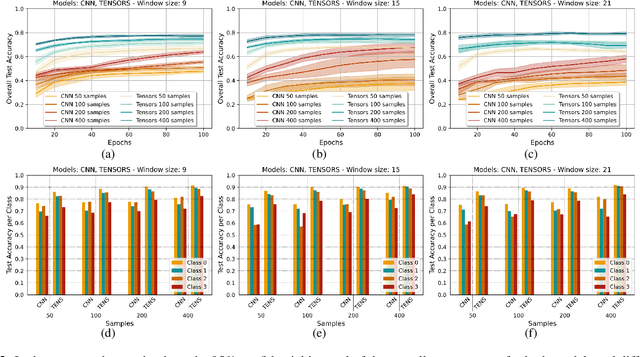
In Cultural Heritage, hyperspectral images are commonly used since they provide extended information regarding the optical properties of materials. Thus, the processing of such high-dimensional data becomes challenging from the perspective of machine learning techniques to be applied. In this paper, we propose a Rank-$R$ tensor-based learning model to identify and classify material defects on Cultural Heritage monuments. In contrast to conventional deep learning approaches, the proposed high order tensor-based learning demonstrates greater accuracy and robustness against overfitting. Experimental results on real-world data from UNESCO protected areas indicate the superiority of the proposed scheme compared to conventional deep learning models.
Revisiting lp-constrained Softmax Loss: A Comprehensive Study
Jun 20, 2022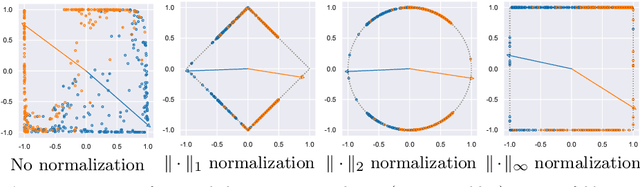
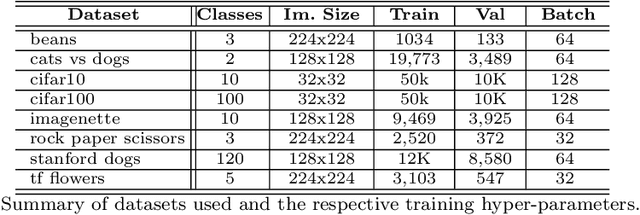

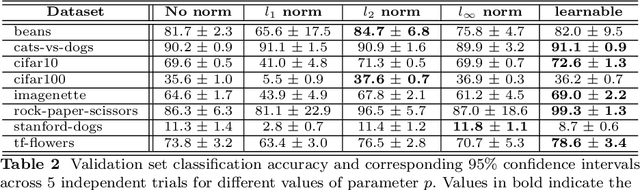
Normalization is a vital process for any machine learning task as it controls the properties of data and affects model performance at large. The impact of particular forms of normalization, however, has so far been investigated in limited domain-specific classification tasks and not in a general fashion. Motivated by the lack of such a comprehensive study, in this paper we investigate the performance of lp-constrained softmax loss classifiers across different norm orders, magnitudes, and data dimensions in both proof-of-concept classification problems and real-world popular image classification tasks. Experimental results suggest collectively that lp-constrained softmax loss classifiers not only can achieve more accurate classification results but, at the same time, appear to be less prone to overfitting. The core findings hold across the three popular deep learning architectures tested and eight datasets examined, and suggest that lp normalization is a recommended data representation practice for image classification in terms of performance and convergence, and against overfitting.