 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResource-Constrained Affect Modelling via Variance Regularisation Pruning
May 26, 2026Affective computing systems are increasingly embedded in pervasive and interactive environments, such as adaptive games, assistive technologies, and resource-constrained platforms, where computational efficiency must be balanced with reliability across diverse users. Model pruning offers an effective way to reduce computational demands, yet existing approaches typically optimise for sparsity alone, without accounting for how parameter removal impacts robustness across individuals. In this work, we introduce Variance-Regularised Pruning (VR), a pruning framework that explicitly incorporates cross-participant stability into the sparsification process. Rather than relying solely on average prediction error, VR evaluates each connection based on its joint contribution to both prediction accuracy and variability across users, prioritising parameters that remain reliable under distributional differences. We evaluate the proposed approach on the AGAIN dataset, which includes arousal annotations collected across nine affect-eliciting game environments. Experimental results demonstrate that VR maintains competitive Concordance Correlation Coefficient (CCC) performance even at 80\% sparsity without additional fine-tuning, highlighting its suitability for deployment in real-world, resource-limited affect-aware systems. Overall, the proposed framework supports the development of compact, robust affective models that can operate reliably in real-world interactive environments.
Beyond the Mean: Modelling Annotation Distributions in Continuous Affect Prediction
Apr 08, 2026Emotion annotation is inherently subjective and cognitively demanding, producing signals that reflect diverse perceptions across annotators rather than a single ground truth. In continuous affect prediction, this variability is typically collapsed into point estimates such as the mean or median, discarding valuable information about annotator disagreement and uncertainty. In this work, we propose a distribution-aware framework that models annotation consensus using the Beta distribution. Instead of predicting a single affect value, models estimate the mean and standard deviation of the annotation distribution, which are transformed into valid Beta parameters through moment matching. This formulation enables the recovery of higher-order distributional descriptors, including skewness, kurtosis, and quantiles, in closed form. As a result, the model captures not only the central tendency of emotional perception but also variability, asymmetry, and uncertainty in annotator responses. We evaluate the proposed approach on the SEWA and RECOLA datasets using multimodal features. Experimental results show that Beta-based modelling produces predictive distributions that closely match the empirical annotator distributions while achieving competitive performance with conventional regression approaches. These findings highlight the importance of modelling annotation uncertainty in affective computing and demonstrate the potential of distribution-aware learning for subjective signal analysis.
LaScA: Language-Conditioned Scalable Modelling of Affective Dynamics
Apr 08, 2026Predicting affect in unconstrained environments remains a fundamental challenge in human-centered AI. While deep neural embeddings dominate contemporary approaches, they often lack interpretability and limit expert-driven refinement. We propose a novel framework that uses Language Models (LMs) as semantic context conditioners over handcrafted affect descriptors to model changes in Valence and Arousal. Our approach begins with interpretable facial geometry and acoustic features derived from structured domain knowledge. These features are transformed into symbolic natural-language descriptions encoding their affective implications. A pretrained LM processes these descriptions to generate semantic context embeddings that act as high-level priors over affective dynamics. Unlike end-to-end black-box pipelines, our framework preserves feature transparency while leveraging the contextual abstraction capabilities of LMs. We evaluate the proposed method on the Aff-Wild2 and SEWA datasets for affect change prediction. Experimental results show consistent improvements in accuracy for both Valence and Arousal compared to handcrafted-only and deep-embedding baselines. Our findings demonstrate that semantic conditioning enables interpretable affect modelling without sacrificing predictive performance, offering a transparent and computationally efficient alternative to fully end-to-end architectures
From the Lab to the Wild: Affect Modeling via Privileged Information
May 18, 2023
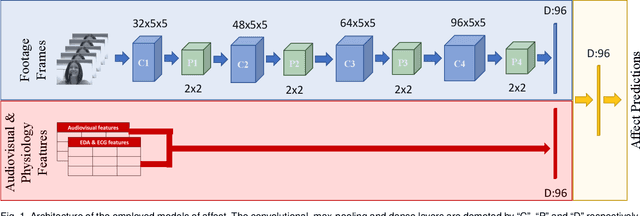
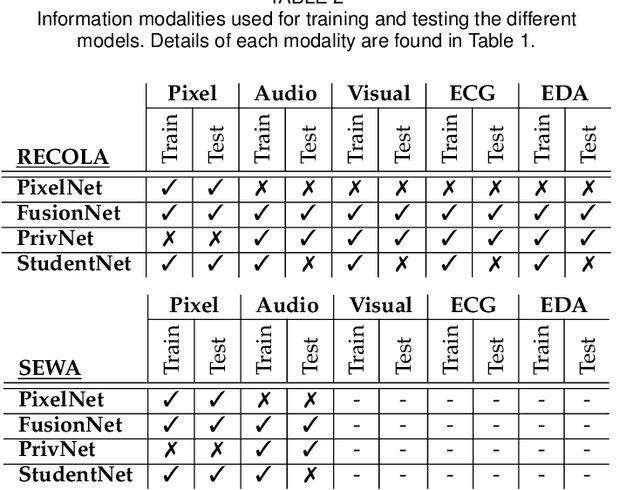
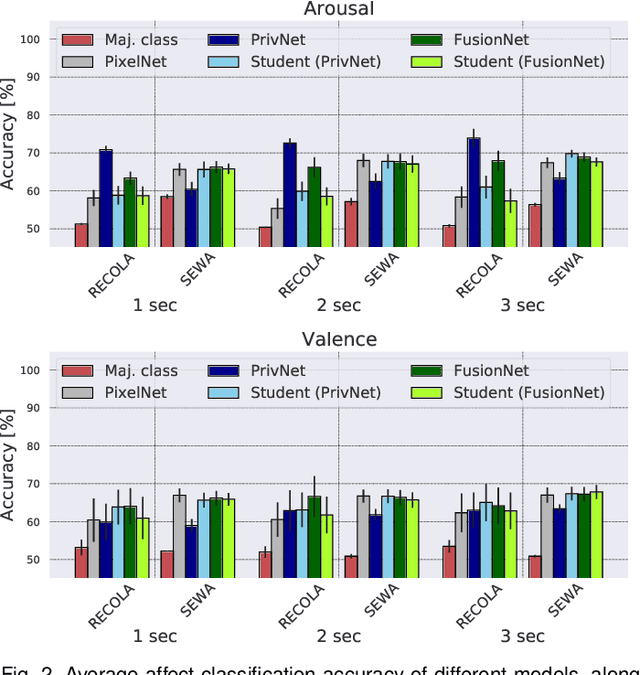
How can we reliably transfer affect models trained in controlled laboratory conditions (in-vitro) to uncontrolled real-world settings (in-vivo)? The information gap between in-vitro and in-vivo applications defines a core challenge of affective computing. This gap is caused by limitations related to affect sensing including intrusiveness, hardware malfunctions and availability of sensors. As a response to these limitations, we introduce the concept of privileged information for operating affect models in real-world scenarios (in the wild). Privileged information enables affect models to be trained across multiple modalities available in a lab, and ignore, without significant performance drops, those modalities that are not available when they operate in the wild. Our approach is tested in two multimodal affect databases one of which is designed for testing models of affect in the wild. By training our affect models using all modalities and then using solely raw footage frames for testing the models, we reach the performance of models that fuse all available modalities for both training and testing. The results are robust across both classification and regression affect modeling tasks which are dominant paradigms in affective computing. Our findings make a decisive step towards realizing affect interaction in the wild.
The Invariant Ground Truth of Affect
Oct 14, 2022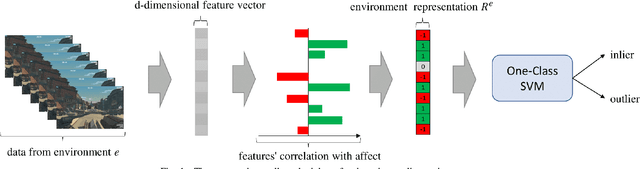

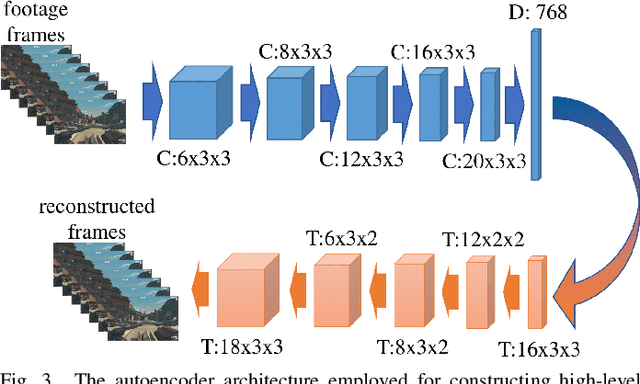
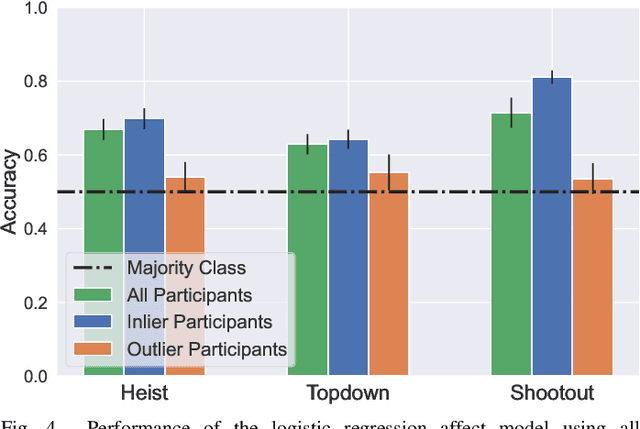
Affective computing strives to unveil the unknown relationship between affect elicitation, manifestation of affect and affect annotations. The ground truth of affect, however, is predominately attributed to the affect labels which inadvertently include biases inherent to the subjective nature of emotion and its labeling. The response to such limitations is usually augmenting the dataset with more annotations per data point; however, this is not possible when we are interested in self-reports via first-person annotation. Moreover, outlier detection methods based on inter-annotator agreement only consider the annotations themselves and ignore the context and the corresponding affect manifestation. This paper reframes the ways one may obtain a reliable ground truth of affect by transferring aspects of causation theory to affective computing. In particular, we assume that the ground truth of affect can be found in the causal relationships between elicitation, manifestation and annotation that remain \emph{invariant} across tasks and participants. To test our assumption we employ causation inspired methods for detecting outliers in affective corpora and building affect models that are robust across participants and tasks. We validate our methodology within the domain of digital games, with experimental results showing that it can successfully detect outliers and boost the accuracy of affect models. To the best of our knowledge, this study presents the first attempt to integrate causation tools in affective computing, making a crucial and decisive step towards general affect modeling.
Supervised Contrastive Learning for Affect Modelling
Aug 25, 2022

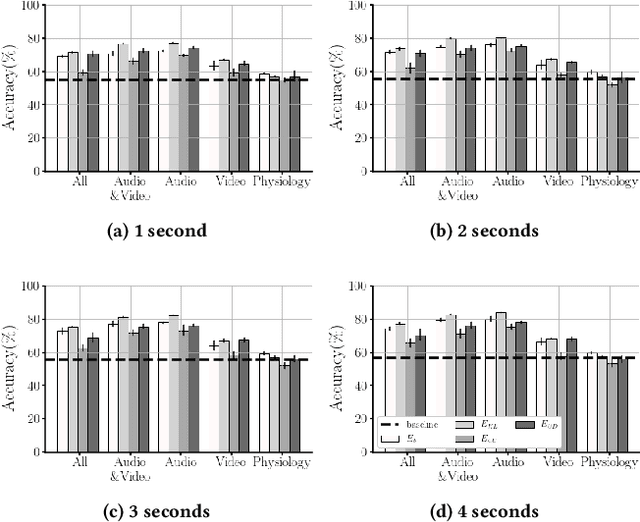
Affect modeling is viewed, traditionally, as the process of mapping measurable affect manifestations from multiple modalities of user input to affect labels. That mapping is usually inferred through end-to-end (manifestation-to-affect) machine learning processes. What if, instead, one trains general, subject-invariant representations that consider affect information and then uses such representations to model affect? In this paper we assume that affect labels form an integral part, and not just the training signal, of an affect representation and we explore how the recent paradigm of contrastive learning can be employed to discover general high-level affect-infused representations for the purpose of modeling affect. We introduce three different supervised contrastive learning approaches for training representations that consider affect information. In this initial study we test the proposed methods for arousal prediction in the RECOLA dataset based on user information from multiple modalities. Results demonstrate the representation capacity of contrastive learning and its efficiency in boosting the accuracy of affect models. Beyond their evidenced higher performance compared to end-to-end arousal classification, the resulting representations are general-purpose and subject-agnostic, as training is guided though general affect information available in any multimodal corpus.
RankNEAT: Outperforming Stochastic Gradient Search in Preference Learning Tasks
Apr 14, 2022

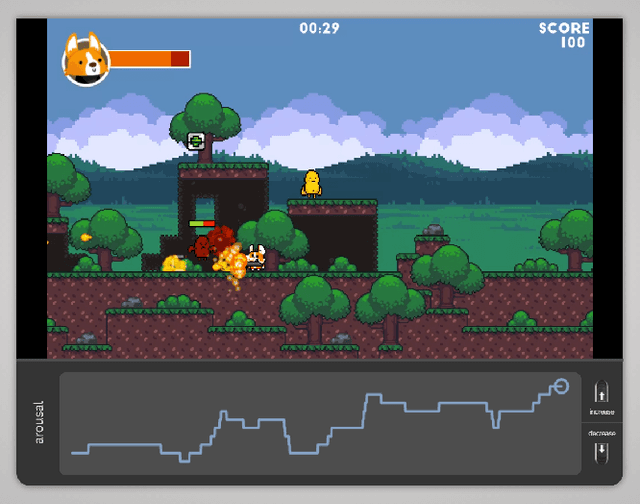
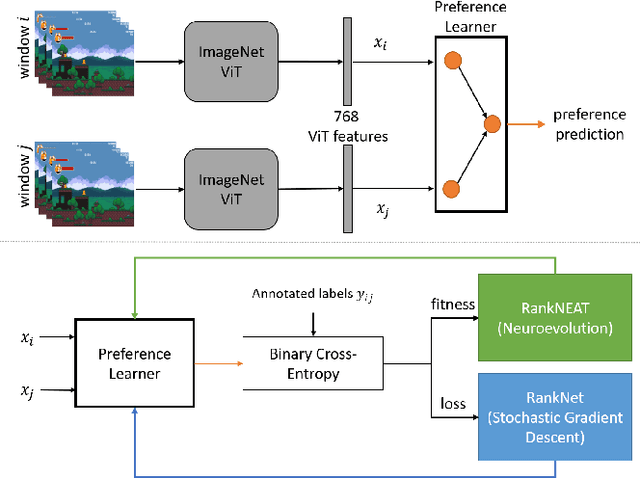
Stochastic gradient descent (SGD) is a premium optimization method for training neural networks, especially for learning objectively defined labels such as image objects and events. When a neural network is instead faced with subjectively defined labels--such as human demonstrations or annotations--SGD may struggle to explore the deceptive and noisy loss landscapes caused by the inherent bias and subjectivity of humans. While neural networks are often trained via preference learning algorithms in an effort to eliminate such data noise, the de facto training methods rely on gradient descent. Motivated by the lack of empirical studies on the impact of evolutionary search to the training of preference learners, we introduce the RankNEAT algorithm which learns to rank through neuroevolution of augmenting topologies. We test the hypothesis that RankNEAT outperforms traditional gradient-based preference learning within the affective computing domain, in particular predicting annotated player arousal from the game footage of three dissimilar games. RankNEAT yields superior performances compared to the gradient-based preference learner (RankNet) in the majority of experiments since its architecture optimization capacity acts as an efficient feature selection mechanism, thereby, eliminating overfitting. Results suggest that RankNEAT is a viable and highly efficient evolutionary alternative to preference learning.
Dendritic Self-Organizing Maps for Continual Learning
Oct 18, 2021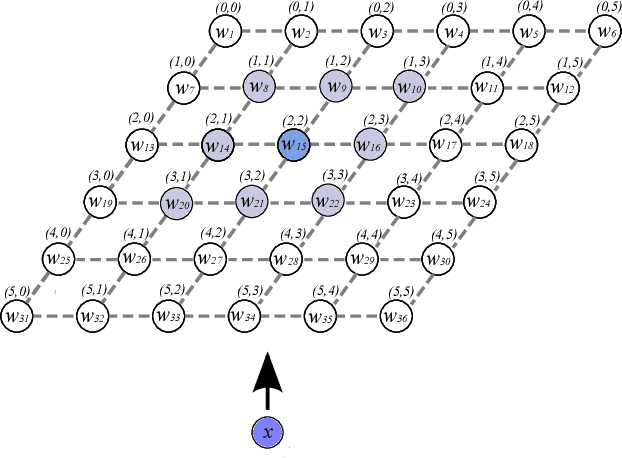

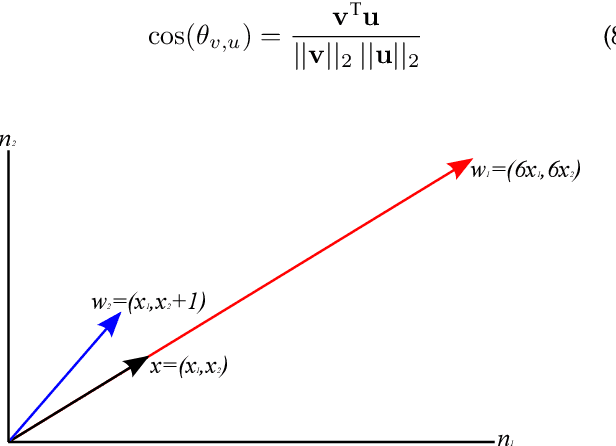
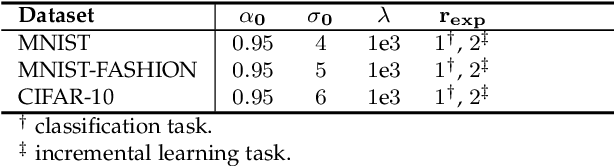
Current deep learning architectures show remarkable performance when trained in large-scale, controlled datasets. However, the predictive ability of these architectures significantly decreases when learning new classes incrementally. This is due to their inclination to forget the knowledge acquired from previously seen data, a phenomenon termed catastrophic-forgetting. On the other hand, Self-Organizing Maps (SOMs) can model the input space utilizing constrained k-means and thus maintain past knowledge. Here, we propose a novel algorithm inspired by biological neurons, termed Dendritic-Self-Organizing Map (DendSOM). DendSOM consists of a single layer of SOMs, which extract patterns from specific regions of the input space accompanied by a set of hit matrices, one per SOM, which estimate the association between units and labels. The best-matching unit of an input pattern is selected using the maximum cosine similarity rule, while the point-wise mutual information is employed for class inference. DendSOM performs unsupervised feature extraction as it does not use labels for targeted updating of the weights. It outperforms classical SOMs and several state-of-the-art continual learning algorithms on benchmark datasets, such as the Split-MNIST and Split-CIFAR-10. We propose that the incorporation of neuronal properties in SOMs may help remedy catastrophic forgetting.