 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA vision-based framework for human behavior understanding in industrial assembly lines
Sep 25, 2024



This paper introduces a vision-based framework for capturing and understanding human behavior in industrial assembly lines, focusing on car door manufacturing. The framework leverages advanced computer vision techniques to estimate workers' locations and 3D poses and analyze work postures, actions, and task progress. A key contribution is the introduction of the CarDA dataset, which contains domain-relevant assembly actions captured in a realistic setting to support the analysis of the framework for human pose and action analysis. The dataset comprises time-synchronized multi-camera RGB-D videos, motion capture data recorded in a real car manufacturing environment, and annotations for EAWS-based ergonomic risk scores and assembly activities. Experimental results demonstrate the effectiveness of the proposed approach in classifying worker postures and robust performance in monitoring assembly task progress.
Learning using privileged information for segmenting tumors on digital mammograms
Feb 09, 2024

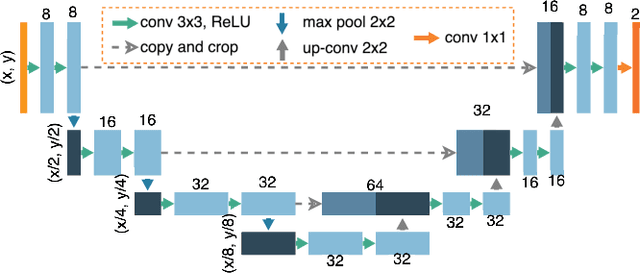

Limited amount of data and data sharing restrictions, due to GDPR compliance, constitute two common factors leading to reduced availability and accessibility when referring to medical data. To tackle these issues, we introduce the technique of Learning Using Privileged Information. Aiming to substantiate the idea, we attempt to build a robust model that improves the segmentation quality of tumors on digital mammograms, by gaining privileged information knowledge during the training procedure. Towards this direction, a baseline model, called student, is trained on patches extracted from the original mammograms, while an auxiliary model with the same architecture, called teacher, is trained on the corresponding enhanced patches accessing, in this way, privileged information. We repeat the student training procedure by providing the assistance of the teacher model this time. According to the experimental results, it seems that the proposed methodology performs better in the most of the cases and it can achieve 10% higher F1 score in comparison with the baseline.
A Few-Shot Attention Recurrent Residual U-Net for Crack Segmentation
Mar 02, 2023Recent studies indicate that deep learning plays a crucial role in the automated visual inspection of road infrastructures. However, current learning schemes are static, implying no dynamic adaptation to users' feedback. To address this drawback, we present a few-shot learning paradigm for the automated segmentation of road cracks, which is based on a U-Net architecture with recurrent residual and attention modules (R2AU-Net). The retraining strategy dynamically fine-tunes the weights of the U-Net as a few new rectified samples are being fed into the classifier. Extensive experiments show that the proposed few-shot R2AU-Net framework outperforms other state-of-the-art networks in terms of Dice and IoU metrics, on a new dataset, named CrackMap, which is made publicly available at https://github.com/ikatsamenis/CrackMap.
Evaluating Transferability for Covid 3D Localization Using CT SARS-CoV-2 segmentation models
May 19, 2022
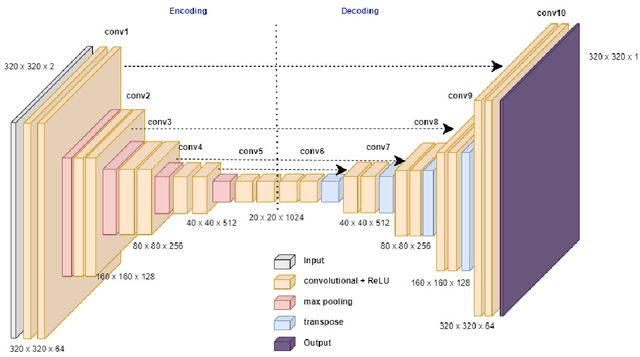


Recent studies indicate that detecting radiographic patterns on CT scans can yield high sensitivity and specificity for Covid-19 localization. In this paper, we investigate the appropriateness of deep learning models transferability, for semantic segmentation of pneumonia-infected areas in CT images. Transfer learning allows for the fast initialization/reutilization of detection models, given that large volumes of training data are not available. Our work explores the efficacy of using pre-trained U-Net architectures, on a specific CT data set, for identifying Covid-19 side-effects over images from different datasets. Experimental results indicate improvement in the segmentation accuracy of identifying Covid-19 infected regions.
Space-Time Domain Tensor Neural Networks: An Application on Human Pose Recognition
Apr 17, 2020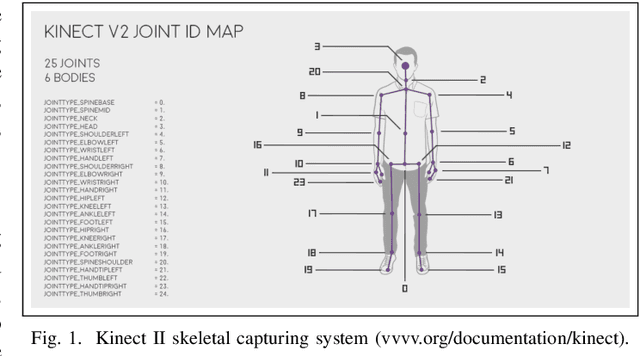

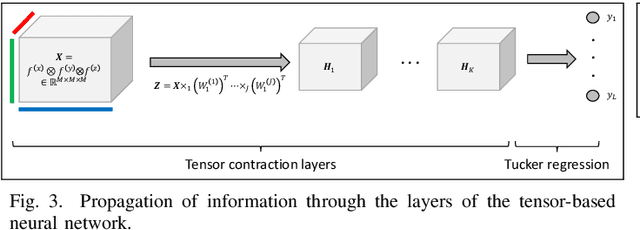

Recent advances in sensing technologies require the design and development of pattern recognition models capable of processing spatiotemporal data efficiently. In this work, we propose a spatially and temporally aware tensor-based neural network for human pose recognition using three-dimensional skeleton data. Our model employs three novel components. First, an input layer capable of constructing highly discriminative spatiotemporal features. Second, a tensor fusion operation that produces compact yet rich representations of the data, and third, a tensor-based neural network that processes data representations in their original tensor form. Our model is end-to-end trainable and characterized by a small number of trainable parameters making it suitable for problems where the annotated data is limited. Experimental validation of the proposed model indicates that it can achieve state-of-the-art performance. Although in this study, we consider the problem of human pose recognition, our methodology is general enough to be applied to any pattern recognition problem spatiotemporal data from sensor networks.