 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSHARC: Reference point driven Spherical Harmonic Representation for Complex Shapes
Apr 02, 2026We propose SHARC, a novel framework that synthesizes arbitrary, genus-agnostic shapes by means of a collection of Spherical Harmonic (SH) representations of distance fields. These distance fields are anchored at optimally placed reference points in the interior volume of the surface in a way that maximizes learning of the finer details of the surface. To achieve this, we employ a cost function that jointly maximizes sparsity and centrality in terms of positioning, as well as visibility of the surface from their location. For each selected reference point, we sample the visible distance field to the surface geometry via ray-casting and compute the SH coefficients using the Fast Spherical Harmonic Transform (FSHT). To enhance geometric fidelity, we apply a configurable low-pass filter to the coefficients and refine the output using a local consistency constraint based on proximity. Evaluation of SHARC against state-of-the-art methods demonstrates that the proposed method outperforms existing approaches in both reconstruction accuracy and time efficiency without sacrificing model parsimony. The source code is available at https://github.com/POSE-Lab/SHARC.
Shape Representation using Gaussian Process mixture models
Apr 01, 2026Traditional explicit 3D representations, such as point clouds and meshes, demand significant storage to capture fine geometric details and require complex indexing systems for surface lookups, making functional representations an efficient, compact, and continuous alternative. In this work, we propose a novel, object-specific functional shape representation that models surface geometry with Gaussian Process (GP) mixture models. Rather than relying on computationally heavy neural architectures, our method is lightweight, leveraging GPs to learn continuous directional distance fields from sparsely sampled point clouds. We capture complex topologies by anchoring local GP priors at strategic reference points, which can be flexibly extracted using any structural decomposition method (e.g. skeletonization, distance-based clustering). Extensive evaluations on the ShapeNetCore and IndustryShapes datasets demonstrate that our method can efficiently and accurately represent complex geometries.
IndustryShapes: An RGB-D Benchmark dataset for 6D object pose estimation of industrial assembly components and tools
Feb 05, 2026We introduce IndustryShapes, a new RGB-D benchmark dataset of industrial tools and components, designed for both instance-level and novel object 6D pose estimation approaches. The dataset provides a realistic and application-relevant testbed for benchmarking these methods in the context of industrial robotics bridging the gap between lab-based research and deployment in real-world manufacturing scenarios. Unlike many previous datasets that focus on household or consumer products or use synthetic, clean tabletop datasets, or objects captured solely in controlled lab environments, IndustryShapes introduces five new object types with challenging properties, also captured in realistic industrial assembly settings. The dataset has diverse complexity, from simple to more challenging scenes, with single and multiple objects, including scenes with multiple instances of the same object and it is organized in two parts: the classic set and the extended set. The classic set includes a total of 4,6k images and 6k annotated poses. The extended set introduces additional data modalities to support the evaluation of model-free and sequence-based approaches. To the best of our knowledge, IndustryShapes is the first dataset to offer RGB-D static onboarding sequences. We further evaluate the dataset on a representative set of state-of-the art methods for instance-based and novel object 6D pose estimation, including also object detection, segmentation, showing that there is room for improvement in this domain. The dataset page can be found in https://pose-lab.github.io/IndustryShapes.
A vision-based framework for human behavior understanding in industrial assembly lines
Sep 25, 2024



This paper introduces a vision-based framework for capturing and understanding human behavior in industrial assembly lines, focusing on car door manufacturing. The framework leverages advanced computer vision techniques to estimate workers' locations and 3D poses and analyze work postures, actions, and task progress. A key contribution is the introduction of the CarDA dataset, which contains domain-relevant assembly actions captured in a realistic setting to support the analysis of the framework for human pose and action analysis. The dataset comprises time-synchronized multi-camera RGB-D videos, motion capture data recorded in a real car manufacturing environment, and annotations for EAWS-based ergonomic risk scores and assembly activities. Experimental results demonstrate the effectiveness of the proposed approach in classifying worker postures and robust performance in monitoring assembly task progress.
COBRA -- COnfidence score Based on shape Regression Analysis for method-independent quality assessment of object pose estimation from single images
Apr 25, 2024We present a generic algorithm for scoring pose estimation methods that rely on single image semantic analysis. The algorithm employs a lightweight putative shape representation using a combination of multiple Gaussian Processes. Each Gaussian Process (GP) yields distance normal distributions from multiple reference points in the object's coordinate system to its surface, thus providing a geometric evaluation framework for scoring predicted poses. Our confidence measure comprises the average mixture probability of pixel back-projections onto the shape template. In the reported experiments, we compare the accuracy of our GP based representation of objects versus the actual geometric models and demonstrate the ability of our method to capture the influence of outliers as opposed to the corresponding intrinsic measures that ship with the segmentation and pose estimation methods.
The ACM Multimedia 2022 Computational Paralinguistics Challenge: Vocalisations, Stuttering, Activity, & Mosquitoes
May 13, 2022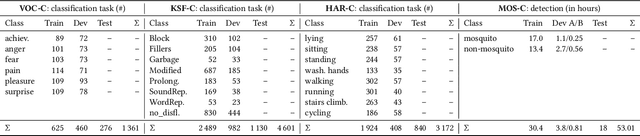
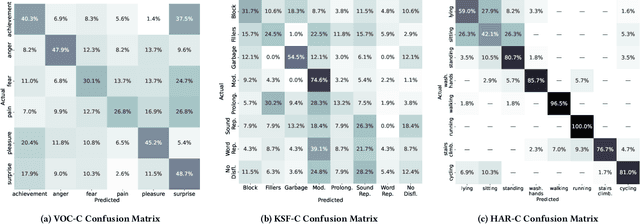

The ACM Multimedia 2022 Computational Paralinguistics Challenge addresses four different problems for the first time in a research competition under well-defined conditions: In the Vocalisations and Stuttering Sub-Challenges, a classification on human non-verbal vocalisations and speech has to be made; the Activity Sub-Challenge aims at beyond-audio human activity recognition from smartwatch sensor data; and in the Mosquitoes Sub-Challenge, mosquitoes need to be detected. We describe the Sub-Challenges, baseline feature extraction, and classifiers based on the usual ComPaRE and BoAW features, the auDeep toolkit, and deep feature extraction from pre-trained CNNs using the DeepSpectRum toolkit; in addition, we add end-to-end sequential modelling, and a log-mel-128-BNN.