 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty estimation in satellite precipitation spatial prediction by combining distributional regression algorithms
Jun 29, 2024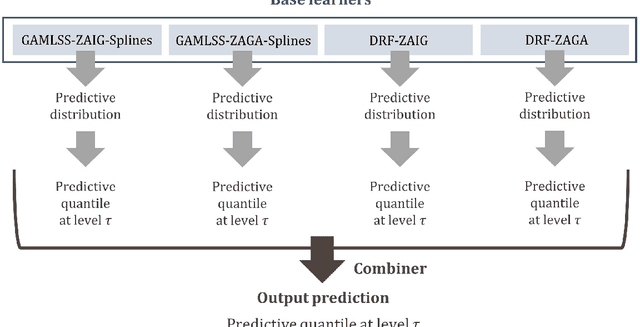
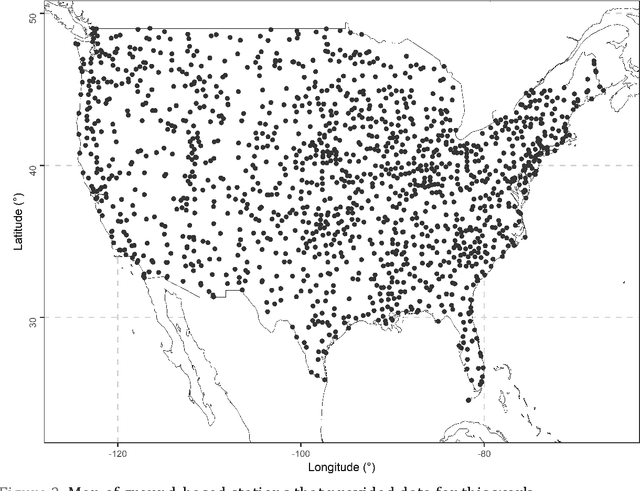
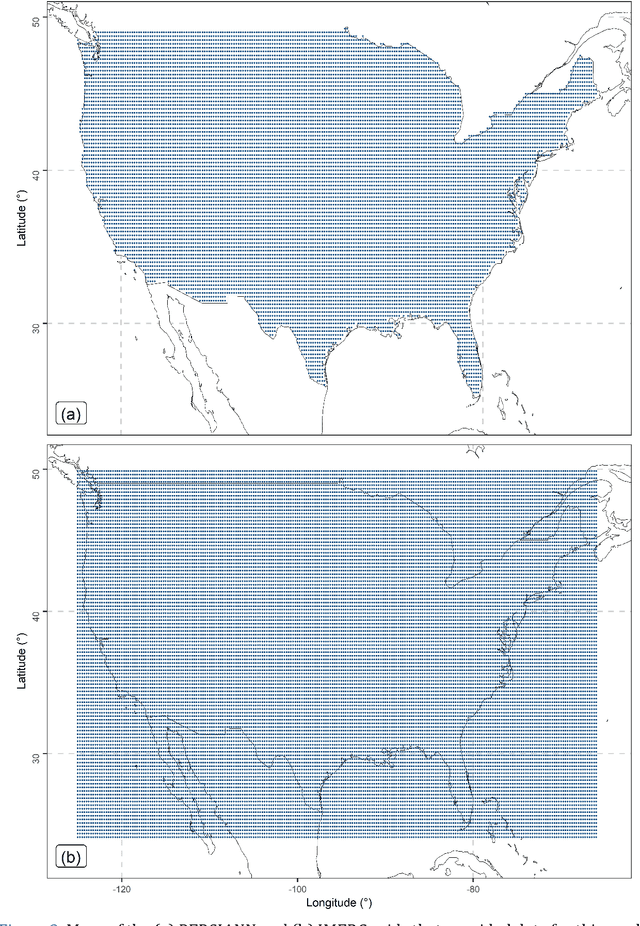
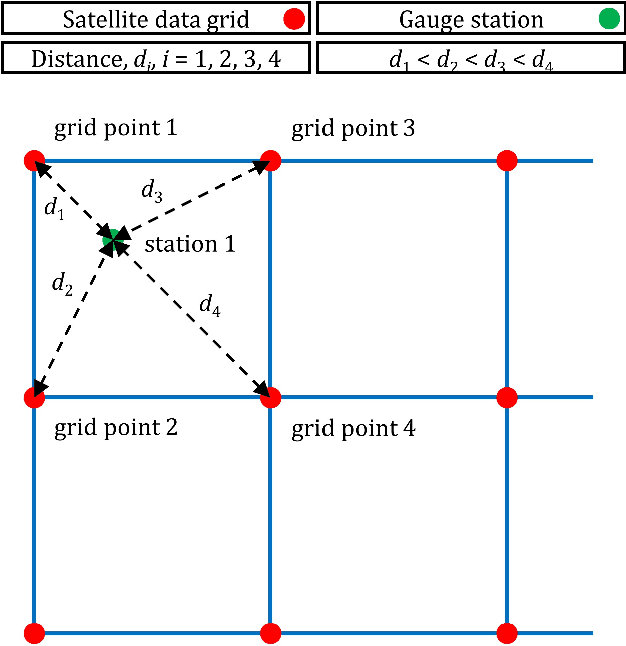
To facilitate effective decision-making, gridded satellite precipitation products should include uncertainty estimates. Machine learning has been proposed for issuing such estimates. However, most existing algorithms for this purpose rely on quantile regression. Distributional regression offers distinct advantages over quantile regression, including the ability to model intermittency as well as a stronger ability to extrapolate beyond the training data, which is critical for predicting extreme precipitation. In this work, we introduce the concept of distributional regression for the engineering task of creating precipitation datasets through data merging. Building upon this concept, we propose new ensemble learning methods that can be valuable not only for spatial prediction but also for prediction problems in general. These methods exploit conditional zero-adjusted probability distributions estimated with generalized additive models for location, scale, and shape (GAMLSS), spline-based GAMLSS and distributional regression forests as well as their ensembles (stacking based on quantile regression, and equal-weight averaging). To identify the most effective methods for our specific problem, we compared them to benchmarks using a large, multi-source precipitation dataset. Stacking emerged as the most successful strategy. Three specific stacking methods achieved the best performance based on the quantile scoring rule, although the ranking of these methods varied across quantile levels. This suggests that a task-specific combination of multiple algorithms could yield significant benefits.
Outlier detection in maritime environments using AIS data and deep recurrent architectures
Jun 14, 2024A methodology based on deep recurrent models for maritime surveillance, over publicly available Automatic Identification System (AIS) data, is presented in this paper. The setup employs a deep Recurrent Neural Network (RNN)-based model, for encoding and reconstructing the observed ships' motion patterns. Our approach is based on a thresholding mechanism, over the calculated errors between observed and reconstructed motion patterns of maritime vessels. Specifically, a deep-learning framework, i.e. an encoder-decoder architecture, is trained using the observed motion patterns, enabling the models to learn and predict the expected trajectory, which will be compared to the effective ones. Our models, particularly the bidirectional GRU with recurrent dropouts, showcased superior performance in capturing the temporal dynamics of maritime data, illustrating the potential of deep learning to enhance maritime surveillance capabilities. Our work lays a solid foundation for future research in this domain, highlighting a path toward improved maritime safety through the innovative application of technology.
Multi-scale Intervention Planning based on Generative Design
Apr 23, 2024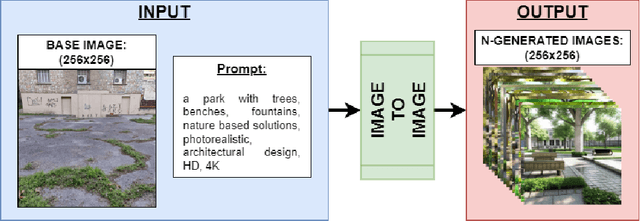



The scarcity of green spaces, in urban environments, consists a critical challenge. There are multiple adverse effects, impacting the health and well-being of the citizens. Small scale interventions, e.g. pocket parks, is a viable solution, but comes with multiple constraints, involving the design and implementation over a specific area. In this study, we harness the capabilities of generative AI for multi-scale intervention planning, focusing on nature based solutions. By leveraging image-to-image and image inpainting algorithms, we propose a methodology to address the green space deficit in urban areas. Focusing on two alleys in Thessaloniki, where greenery is lacking, we demonstrate the efficacy of our approach in visualizing NBS interventions. Our findings underscore the transformative potential of emerging technologies in shaping the future of urban intervention planning processes.
Uncertainty estimation in spatial interpolation of satellite precipitation with ensemble learning
Mar 14, 2024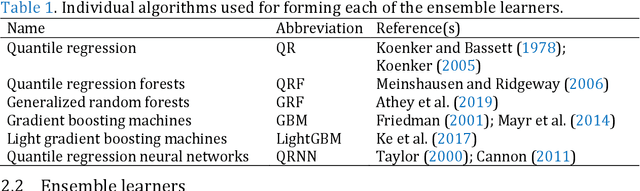

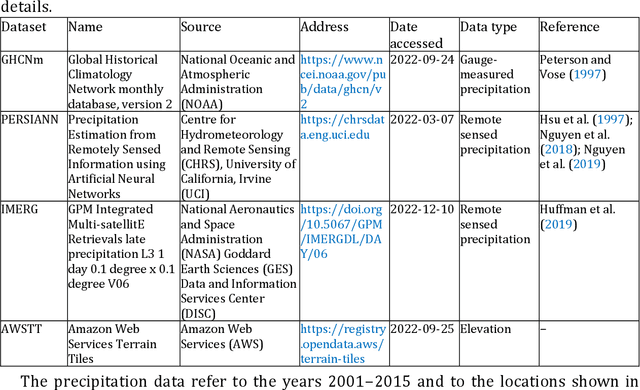
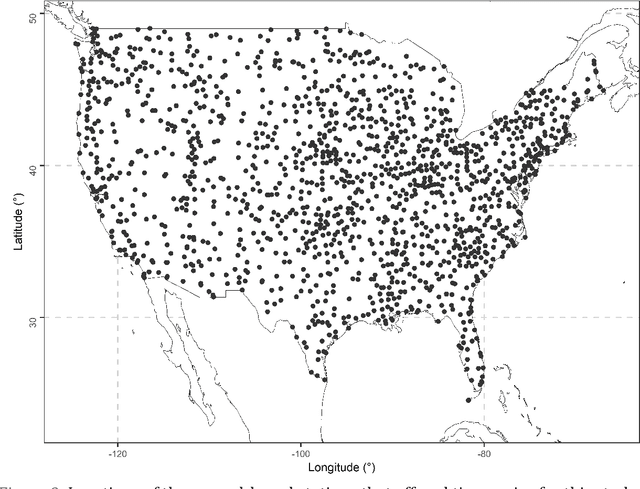
Predictions in the form of probability distributions are crucial for decision-making. Quantile regression enables this within spatial interpolation settings for merging remote sensing and gauge precipitation data. However, ensemble learning of quantile regression algorithms remains unexplored in this context. Here, we address this gap by introducing nine quantile-based ensemble learners and applying them to large precipitation datasets. We employed a novel feature engineering strategy, reducing predictors to distance-weighted satellite precipitation at relevant locations, combined with location elevation. Our ensemble learners include six stacking and three simple methods (mean, median, best combiner), combining six individual algorithms: quantile regression (QR), quantile regression forests (QRF), generalized random forests (GRF), gradient boosting machines (GBM), light gradient boosting machines (LightGBM), and quantile regression neural networks (QRNN). These algorithms serve as both base learners and combiners within different stacking methods. We evaluated performance against QR using quantile scoring functions in a large dataset comprising 15 years of monthly gauge-measured and satellite precipitation in contiguous US (CONUS). Stacking with QR and QRNN yielded the best results across quantile levels of interest (0.025, 0.050, 0.075, 0.100, 0.200, 0.300, 0.400, 0.500, 0.600, 0.700, 0.800, 0.900, 0.925, 0.950, 0.975), surpassing the reference method by 3.91% to 8.95%. This demonstrates the potential of stacking to improve probabilistic predictions in spatial interpolation and beyond.
Learning using privileged information for segmenting tumors on digital mammograms
Feb 09, 2024

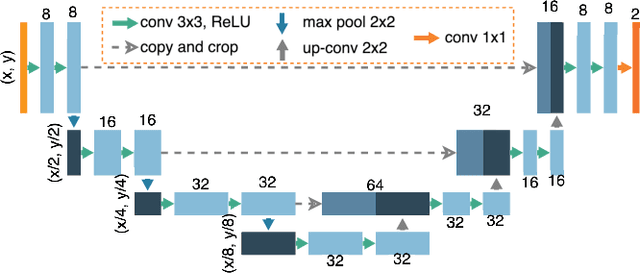

Limited amount of data and data sharing restrictions, due to GDPR compliance, constitute two common factors leading to reduced availability and accessibility when referring to medical data. To tackle these issues, we introduce the technique of Learning Using Privileged Information. Aiming to substantiate the idea, we attempt to build a robust model that improves the segmentation quality of tumors on digital mammograms, by gaining privileged information knowledge during the training procedure. Towards this direction, a baseline model, called student, is trained on patches extracted from the original mammograms, while an auxiliary model with the same architecture, called teacher, is trained on the corresponding enhanced patches accessing, in this way, privileged information. We repeat the student training procedure by providing the assistance of the teacher model this time. According to the experimental results, it seems that the proposed methodology performs better in the most of the cases and it can achieve 10% higher F1 score in comparison with the baseline.
Machine learning for uncertainty estimation in fusing precipitation observations from satellites and ground-based gauges
Nov 13, 2023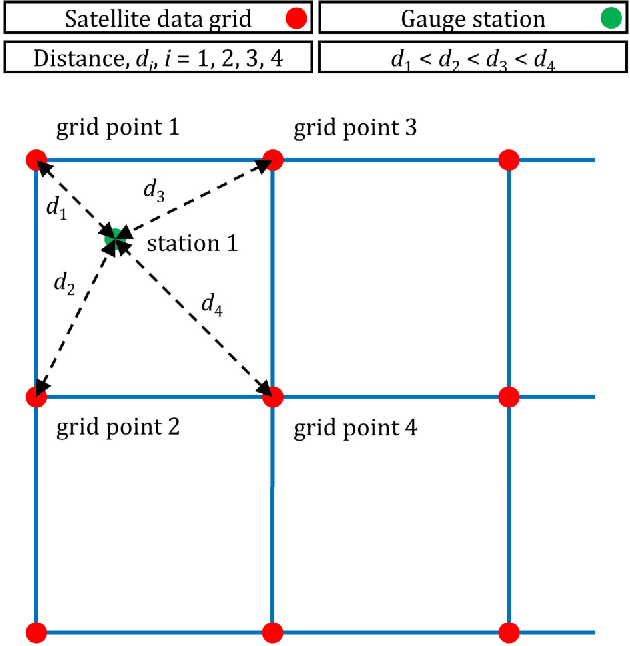
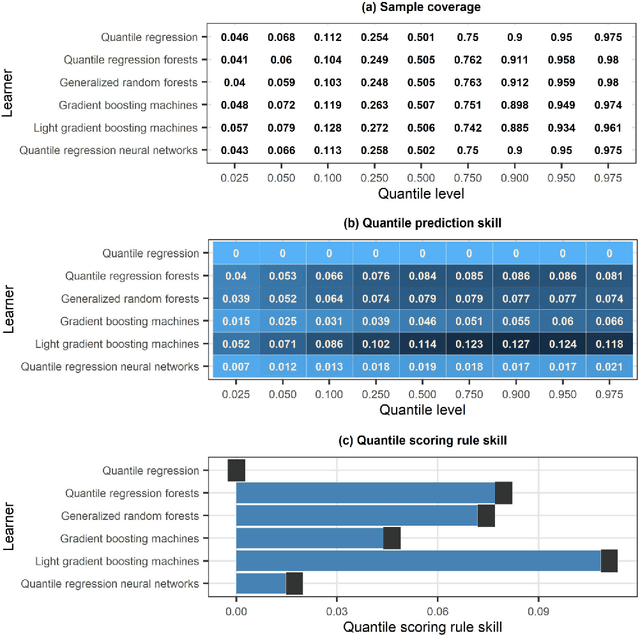

To form precipitation datasets that are accurate and, at the same time, have high spatial densities, data from satellites and gauges are often merged in the literature. However, uncertainty estimates for the data acquired in this manner are scarcely provided, although the importance of uncertainty quantification in predictive modelling is widely recognized. Furthermore, the benefits that machine learning can bring to the task of providing such estimates have not been broadly realized and properly explored through benchmark experiments. The present study aims at filling in this specific gap by conducting the first benchmark tests on the topic. On a large dataset that comprises 15-year-long monthly data spanning across the contiguous United States, we extensively compared six learners that are, by their construction, appropriate for predictive uncertainty quantification. These are the quantile regression (QR), quantile regression forests (QRF), generalized random forests (GRF), gradient boosting machines (GBM), light gradient boosting machines (LightGBM) and quantile regression neural networks (QRNN). The comparison referred to the competence of the learners in issuing predictive quantiles at nine levels that facilitate a good approximation of the entire predictive probability distribution, and was primarily based on the quantile and continuous ranked probability skill scores. Three types of predictor variables (i.e., satellite precipitation variables, distances between a point of interest and satellite grid points, and elevation at a point of interest) were used in the comparison and were additionally compared with each other. This additional comparison was based on the explainable machine learning concept of feature importance. The results suggest that the order from the best to the worst of the learners for the task investigated is the following: LightGBM, QRF, GRF, GBM, QRNN and QR...
Ensemble learning for blending gridded satellite and gauge-measured precipitation data
Jul 09, 2023Regression algorithms are regularly used for improving the accuracy of satellite precipitation products. In this context, ground-based measurements are the dependent variable and the satellite data are the predictor variables, together with topography factors. Alongside this, it is increasingly recognised in many fields that combinations of algorithms through ensemble learning can lead to substantial predictive performance improvements. Still, a sufficient number of ensemble learners for improving the accuracy of satellite precipitation products and their large-scale comparison are currently missing from the literature. In this work, we fill this specific gap by proposing 11 new ensemble learners in the field and by extensively comparing them for the entire contiguous United States and for a 15-year period. We use monthly data from the PERSIANN (Precipitation Estimation from Remotely Sensed Information using Artificial Neural Networks) and IMERG (Integrated Multi-satellitE Retrievals for GPM) gridded datasets. We also use gauge-measured precipitation data from the Global Historical Climatology Network monthly database, version 2 (GHCNm). The ensemble learners combine the predictions by six regression algorithms (base learners), namely the multivariate adaptive regression splines (MARS), multivariate adaptive polynomial splines (poly-MARS), random forests (RF), gradient boosting machines (GBM), extreme gradient boosting (XGBoost) and Bayesian regularized neural networks (BRNN), and each of them is based on a different combiner. The combiners include the equal-weight combiner, the median combiner, two best learners and seven variants of a sophisticated stacking method. The latter stacks a regression algorithm on the top of the base learners to combine their independent predictions...
A Few-Shot Attention Recurrent Residual U-Net for Crack Segmentation
Mar 02, 2023Recent studies indicate that deep learning plays a crucial role in the automated visual inspection of road infrastructures. However, current learning schemes are static, implying no dynamic adaptation to users' feedback. To address this drawback, we present a few-shot learning paradigm for the automated segmentation of road cracks, which is based on a U-Net architecture with recurrent residual and attention modules (R2AU-Net). The retraining strategy dynamically fine-tunes the weights of the U-Net as a few new rectified samples are being fed into the classifier. Extensive experiments show that the proposed few-shot R2AU-Net framework outperforms other state-of-the-art networks in terms of Dice and IoU metrics, on a new dataset, named CrackMap, which is made publicly available at https://github.com/ikatsamenis/CrackMap.
Merging satellite and gauge-measured precipitation using LightGBM with an emphasis on extreme quantiles
Feb 02, 2023Knowing the actual precipitation in space and time is critical in hydrological modelling applications, yet the spatial coverage with rain gauge stations is limited due to economic constraints. Gridded satellite precipitation datasets offer an alternative option for estimating the actual precipitation by covering uniformly large areas, albeit related estimates are not accurate. To improve precipitation estimates, machine learning is applied to merge rain gauge-based measurements and gridded satellite precipitation products. In this context, observed precipitation plays the role of the dependent variable, while satellite data play the role of predictor variables. Random forests is the dominant machine learning algorithm in relevant applications. In those spatial predictions settings, point predictions (mostly the mean or the median of the conditional distribution) of the dependent variable are issued. Here we propose, issuing probabilistic spatial predictions of precipitation using Light Gradient Boosting Machine (LightGBM). LightGBM is a boosting algorithm, highlighted by prize-winning entries in prediction and forecasting competitions. To assess LightGBM, we contribute a large-scale application that includes merging daily precipitation measurements in contiguous US with PERSIANN and GPM-IMERG satellite precipitation data. We focus on extreme quantiles of the probability distribution of the dependent variable, where LightGBM outperforms quantile regression forests (QRF, a variant of random forests) in terms of quantile score. LightGBM and QRF show similar performance when predicting functionals at the centre of the conditional probability distribution, including the conditional median. Our study offers understanding of probabilistic predictions in spatial settings using machine learning.
Comparison of tree-based ensemble algorithms for merging satellite and earth-observed precipitation data at the daily time scale
Dec 31, 2022Merging satellite products and ground-based measurements is often required for obtaining precipitation datasets that simultaneously cover large regions with high density and are more accurate than pure satellite precipitation products. Machine and statistical learning regression algorithms are regularly utilized in this endeavour. At the same time, tree-based ensemble algorithms for regression are adopted in various fields for solving algorithmic problems with high accuracy and low computational cost. The latter can constitute a crucial factor for selecting algorithms for satellite precipitation product correction at the daily and finer time scales, where the size of the datasets is particularly large. Still, information on which tree-based ensemble algorithm to select in such a case for the contiguous United States (US) is missing from the literature. In this work, we conduct an extensive comparison between three tree-based ensemble algorithms, specifically random forests, gradient boosting machines (gbm) and extreme gradient boosting (XGBoost), in the context of interest. We use daily data from the PERSIANN (Precipitation Estimation from Remotely Sensed Information using Artificial Neural Networks) and the IMERG (Integrated Multi-satellitE Retrievals for GPM) gridded datasets. We also use earth-observed precipitation data from the Global Historical Climatology Network daily (GHCNd) database. The experiments refer to the entire contiguous US and additionally include the application of the linear regression algorithm for benchmarking purposes. The results suggest that XGBoost is the best-performing tree-based ensemble algorithm among those compared. They also suggest that IMERG is more useful than PERSIANN in the context investigated.