 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty estimation in satellite precipitation spatial prediction by combining distributional regression algorithms
Paper and Code
Jun 29, 2024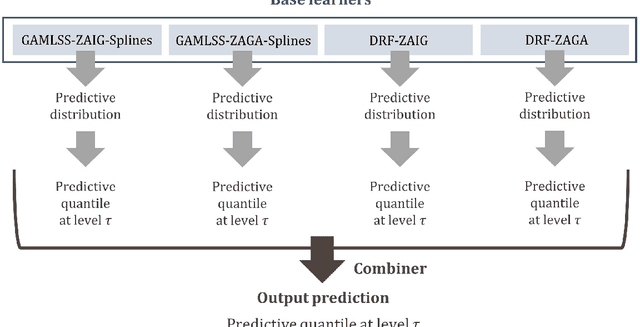
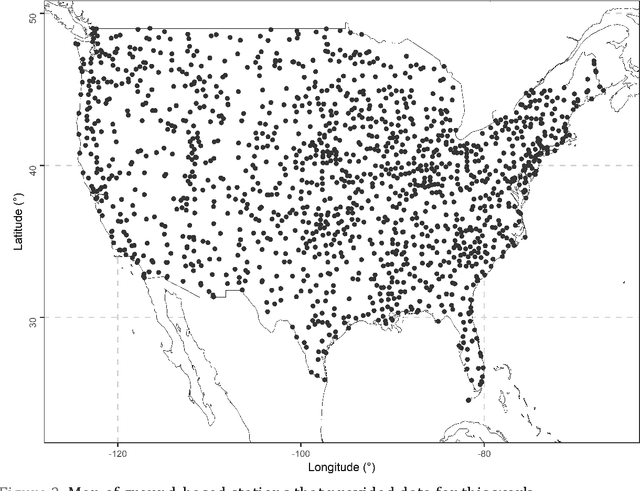
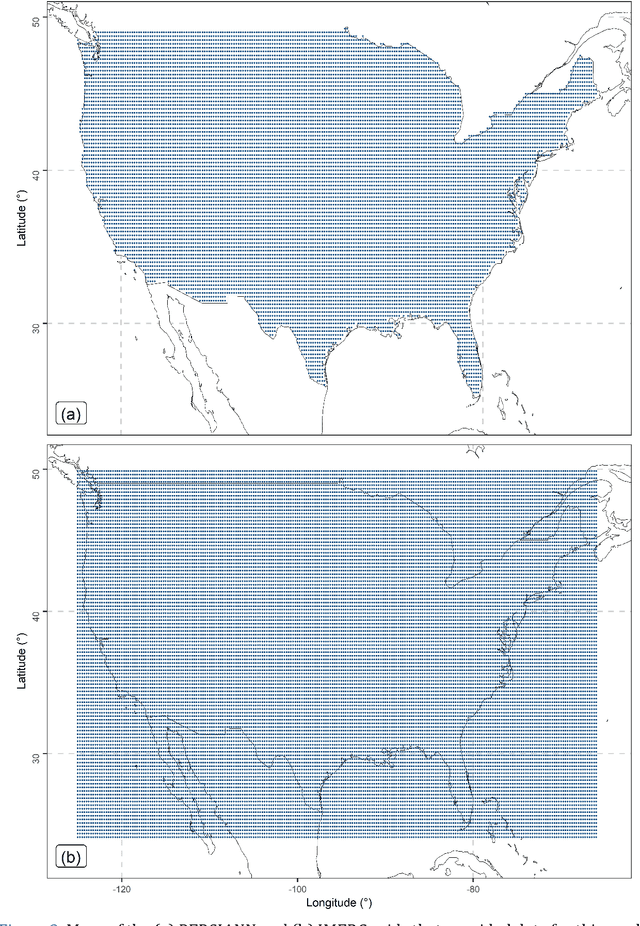
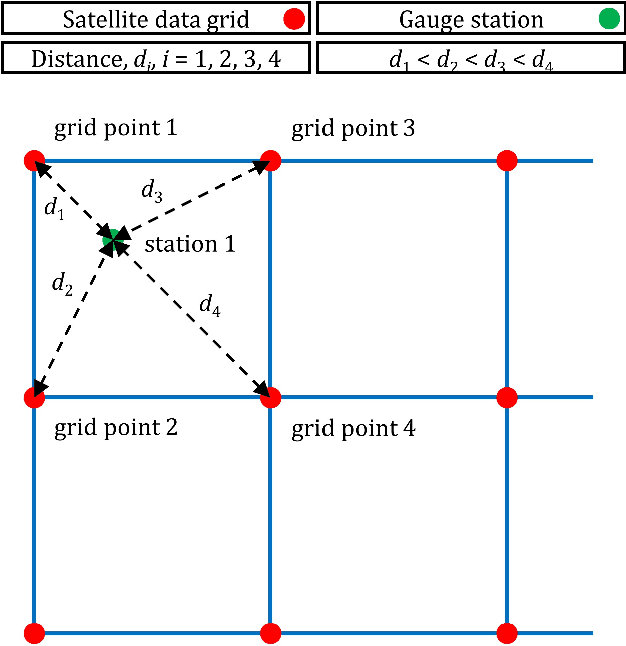
To facilitate effective decision-making, gridded satellite precipitation products should include uncertainty estimates. Machine learning has been proposed for issuing such estimates. However, most existing algorithms for this purpose rely on quantile regression. Distributional regression offers distinct advantages over quantile regression, including the ability to model intermittency as well as a stronger ability to extrapolate beyond the training data, which is critical for predicting extreme precipitation. In this work, we introduce the concept of distributional regression for the engineering task of creating precipitation datasets through data merging. Building upon this concept, we propose new ensemble learning methods that can be valuable not only for spatial prediction but also for prediction problems in general. These methods exploit conditional zero-adjusted probability distributions estimated with generalized additive models for location, scale, and shape (GAMLSS), spline-based GAMLSS and distributional regression forests as well as their ensembles (stacking based on quantile regression, and equal-weight averaging). To identify the most effective methods for our specific problem, we compared them to benchmarks using a large, multi-source precipitation dataset. Stacking emerged as the most successful strategy. Three specific stacking methods achieved the best performance based on the quantile scoring rule, although the ranking of these methods varied across quantile levels. This suggests that a task-specific combination of multiple algorithms could yield significant benefits.