 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimulator-Free Visual Domain Randomization via Video Games
Feb 02, 2024Domain randomization is an effective computer vision technique for improving transferability of vision models across visually distinct domains exhibiting similar content. Existing approaches, however, rely extensively on tweaking complex and specialized simulation engines that are difficult to construct, subsequently affecting their feasibility and scalability. This paper introduces BehAVE, a video understanding framework that uniquely leverages the plethora of existing commercial video games for domain randomization, without requiring access to their simulation engines. Under BehAVE (1) the inherent rich visual diversity of video games acts as the source of randomization and (2) player behavior -- represented semantically via textual descriptions of actions -- guides the *alignment* of videos with similar content. We test BehAVE on 25 games of the first-person shooter (FPS) genre across various video and text foundation models and we report its robustness for domain randomization. BehAVE successfully aligns player behavioral patterns and is able to zero-shot transfer them to multiple unseen FPS games when trained on just one FPS game. In a more challenging setting, BehAVE manages to improve the zero-shot transferability of foundation models to unseen FPS games (up to 22%) even when trained on a game of a different genre (Minecraft). Code and dataset can be found at https://github.com/nrasajski/BehAVE.
Towards General Game Representations: Decomposing Games Pixels into Content and Style
Jul 20, 2023On-screen game footage contains rich contextual information that players process when playing and experiencing a game. Learning pixel representations of games can benefit artificial intelligence across several downstream tasks including game-playing agents, procedural content generation, and player modelling. The generalizability of these methods, however, remains a challenge, as learned representations should ideally be shared across games with similar game mechanics. This could allow, for instance, game-playing agents trained on one game to perform well in similar games with no re-training. This paper explores how generalizable pre-trained computer vision encoders can be for such tasks, by decomposing the latent space into content embeddings and style embeddings. The goal is to minimize the domain gap between games of the same genre when it comes to game content critical for downstream tasks, and ignore differences in graphical style. We employ a pre-trained Vision Transformer encoder and a decomposition technique based on game genres to obtain separate content and style embeddings. Our findings show that the decomposed embeddings achieve style invariance across multiple games while still maintaining strong content extraction capabilities. We argue that the proposed decomposition of content and style offers better generalization capacities across game environments independently of the downstream task.
Game State Learning via Game Scene Augmentation
Jul 08, 2022

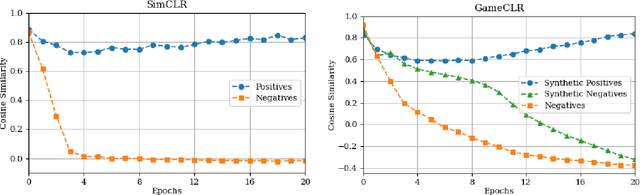

Having access to accurate game state information is of utmost importance for any artificial intelligence task including game-playing, testing, player modeling, and procedural content generation. Self-Supervised Learning (SSL) techniques have shown to be capable of inferring accurate game state information from the high-dimensional pixel input of game footage into compressed latent representations. Contrastive Learning is a popular SSL paradigm where the visual understanding of the game's images comes from contrasting dissimilar and similar game states defined by simple image augmentation methods. In this study, we introduce a new game scene augmentation technique -- named GameCLR -- that takes advantage of the game-engine to define and synthesize specific, highly-controlled renderings of different game states, thereby, boosting contrastive learning performance. We test our GameCLR technique on images of the CARLA driving simulator environment and compare it against the popular SimCLR baseline SSL method. Our results suggest that GameCLR can infer the game's state information from game footage more accurately compared to the baseline. Our proposed approach allows us to conduct game artificial intelligence research by directly utilizing screen pixels as input.
Revisiting lp-constrained Softmax Loss: A Comprehensive Study
Jun 20, 2022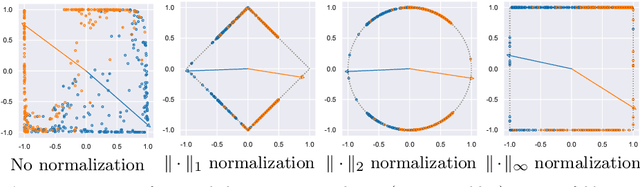
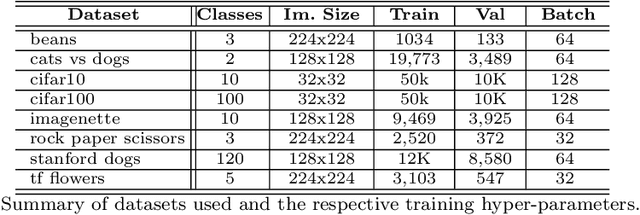

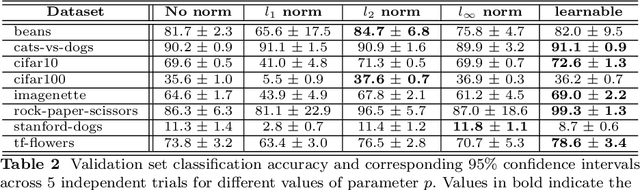
Normalization is a vital process for any machine learning task as it controls the properties of data and affects model performance at large. The impact of particular forms of normalization, however, has so far been investigated in limited domain-specific classification tasks and not in a general fashion. Motivated by the lack of such a comprehensive study, in this paper we investigate the performance of lp-constrained softmax loss classifiers across different norm orders, magnitudes, and data dimensions in both proof-of-concept classification problems and real-world popular image classification tasks. Experimental results suggest collectively that lp-constrained softmax loss classifiers not only can achieve more accurate classification results but, at the same time, appear to be less prone to overfitting. The core findings hold across the three popular deep learning architectures tested and eight datasets examined, and suggest that lp normalization is a recommended data representation practice for image classification in terms of performance and convergence, and against overfitting.
Learning Task-Independent Game State Representations from Unlabeled Images
Jun 13, 2022

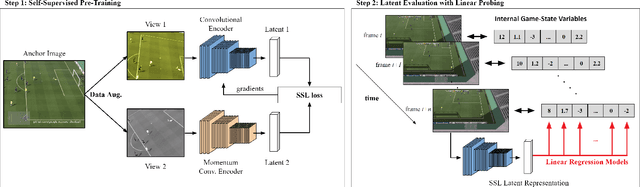
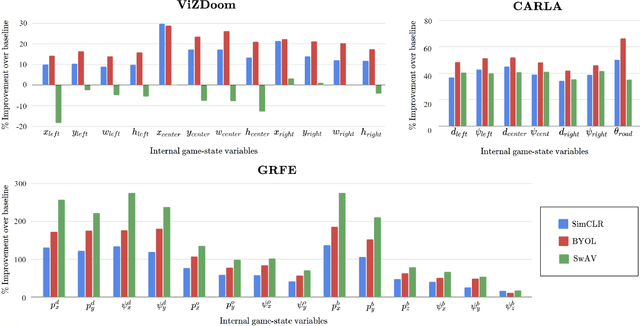
Self-supervised learning (SSL) techniques have been widely used to learn compact and informative representations from high-dimensional complex data. In many computer vision tasks, such as image classification, such methods achieve state-of-the-art results that surpass supervised learning approaches. In this paper, we investigate whether SSL methods can be leveraged for the task of learning accurate state representations of games, and if so, to what extent. For this purpose, we collect game footage frames and corresponding sequences of games' internal state from three different 3D games: VizDoom, the CARLA racing simulator and the Google Research Football Environment. We train an image encoder with three widely used SSL algorithms using solely the raw frames, and then attempt to recover the internal state variables from the learned representations. Our results across all three games showcase significantly higher correlation between SSL representations and the game's internal state compared to pre-trained baseline models such as ImageNet. Such findings suggest that SSL-based visual encoders can yield general -- not tailored to a specific task -- yet informative game representations solely from game pixel information. Such representations can, in turn, form the basis for boosting the performance of downstream learning tasks in games, including gameplaying, content generation and player modeling.
Contrastive Learning of Generalized Game Representations
Jun 18, 2021
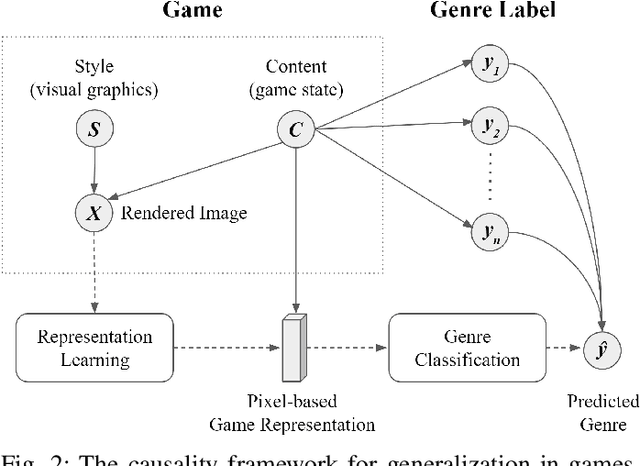


Representing games through their pixels offers a promising approach for building general-purpose and versatile game models. While games are not merely images, neural network models trained on game pixels often capture differences of the visual style of the image rather than the content of the game. As a result, such models cannot generalize well even within similar games of the same genre. In this paper we build on recent advances in contrastive learning and showcase its benefits for representation learning in games. Learning to contrast images of games not only classifies games in a more efficient manner; it also yields models that separate games in a more meaningful fashion by ignoring the visual style and focusing, instead, on their content. Our results in a large dataset of sports video games containing 100k images across 175 games and 10 game genres suggest that contrastive learning is better suited for learning generalized game representations compared to conventional supervised learning. The findings of this study bring us closer to universal visual encoders for games that can be reused across previously unseen games without requiring retraining or fine-tuning.