 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Task-Independent Game State Representations from Unlabeled Images
Paper and Code
Jun 13, 2022

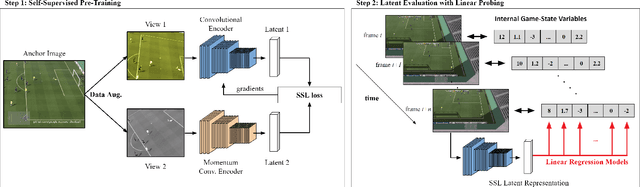
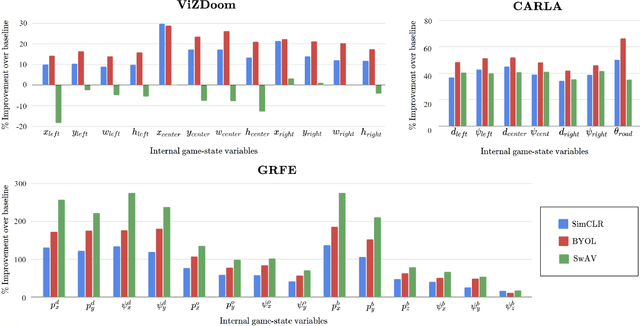
Self-supervised learning (SSL) techniques have been widely used to learn compact and informative representations from high-dimensional complex data. In many computer vision tasks, such as image classification, such methods achieve state-of-the-art results that surpass supervised learning approaches. In this paper, we investigate whether SSL methods can be leveraged for the task of learning accurate state representations of games, and if so, to what extent. For this purpose, we collect game footage frames and corresponding sequences of games' internal state from three different 3D games: VizDoom, the CARLA racing simulator and the Google Research Football Environment. We train an image encoder with three widely used SSL algorithms using solely the raw frames, and then attempt to recover the internal state variables from the learned representations. Our results across all three games showcase significantly higher correlation between SSL representations and the game's internal state compared to pre-trained baseline models such as ImageNet. Such findings suggest that SSL-based visual encoders can yield general -- not tailored to a specific task -- yet informative game representations solely from game pixel information. Such representations can, in turn, form the basis for boosting the performance of downstream learning tasks in games, including gameplaying, content generation and player modeling.