 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGoal-Conditioned Reinforcement Learning in the Presence of an Adversary
Nov 13, 2022
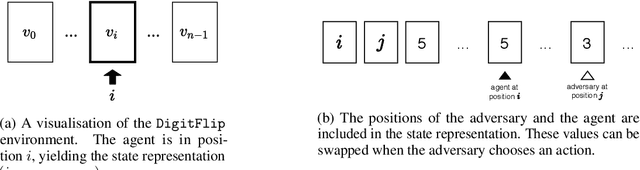


Reinforcement learning has seen increasing applications in real-world contexts over the past few years. However, physical environments are often imperfect and policies that perform well in simulation might not achieve the same performance when applied elsewhere. A common approach to combat this is to train agents in the presence of an adversary. An adversary acts to destabilise the agent, which learns a more robust policy and can better handle realistic conditions. Many real-world applications of reinforcement learning also make use of goal-conditioning: this is particularly useful in the context of robotics, as it allows the agent to act differently, depending on which goal is selected. Here, we focus on the problem of goal-conditioned learning in the presence of an adversary. We first present DigitFlip and CLEVR-Play, two novel goal-conditioned environments that support acting against an adversary. Next, we propose EHER and CHER -- two HER-based algorithms for goal-conditioned learning -- and evaluate their performance. Finally, we unify the two threads and introduce IGOAL: a novel framework for goal-conditioned learning in the presence of an adversary. Experimental results show that combining IGOAL with EHER allows agents to significantly outperform existing approaches, when acting against both random and competent adversaries.
Active Acquisition for Multimodal Temporal Data: A Challenging Decision-Making Task
Nov 09, 2022

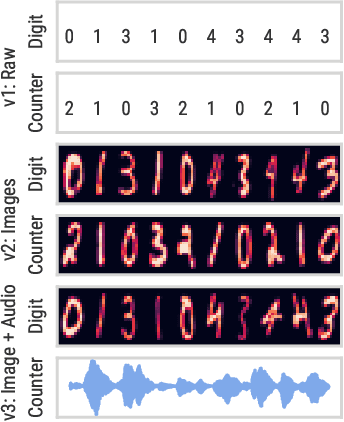

We introduce a challenging decision-making task that we call active acquisition for multimodal temporal data (A2MT). In many real-world scenarios, input features are not readily available at test time and must instead be acquired at significant cost. With A2MT, we aim to learn agents that actively select which modalities of an input to acquire, trading off acquisition cost and predictive performance. A2MT extends a previous task called active feature acquisition to temporal decision making about high-dimensional inputs. Further, we propose a method based on the Perceiver IO architecture to address A2MT in practice. Our agents are able to solve a novel synthetic scenario requiring practically relevant cross-modal reasoning skills. On two large-scale, real-world datasets, Kinetics-700 and AudioSet, our agents successfully learn cost-reactive acquisition behavior. However, an ablation reveals they are unable to learn to learn adaptive acquisition strategies, emphasizing the difficulty of the task even for state-of-the-art models. Applications of A2MT may be impactful in domains like medicine, robotics, or finance, where modalities differ in acquisition cost and informativeness.
General-purpose, long-context autoregressive modeling with Perceiver AR
Feb 15, 2022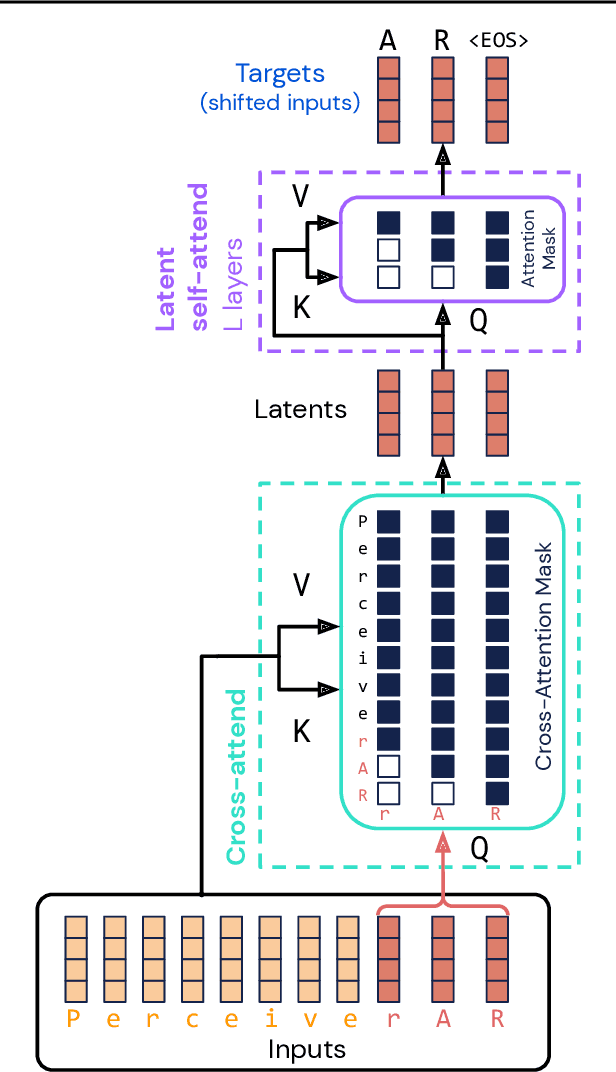
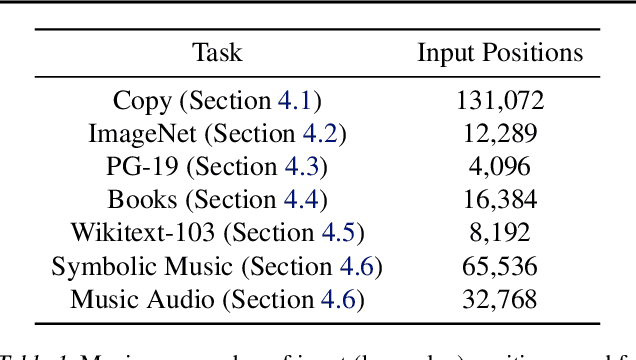
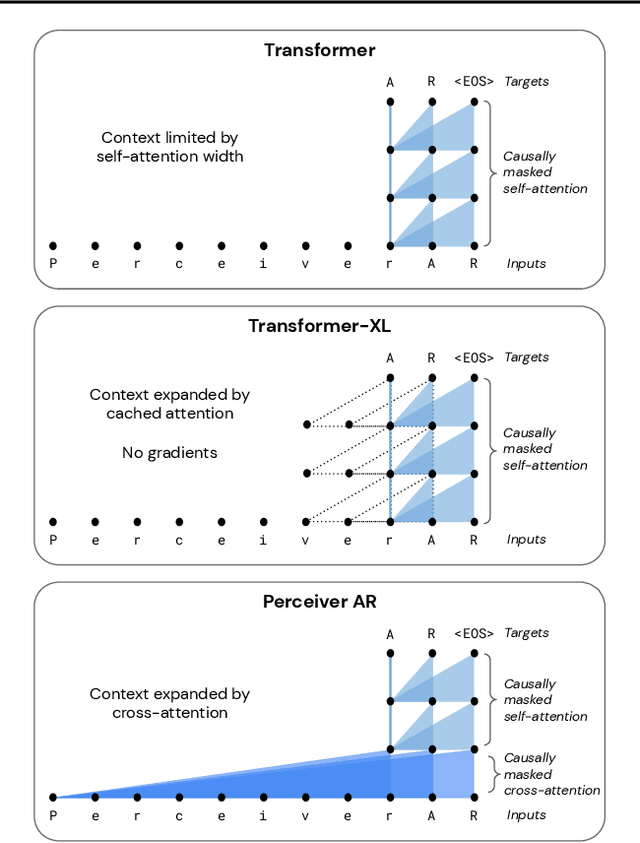
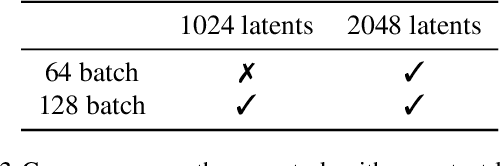
Real-world data is high-dimensional: a book, image, or musical performance can easily contain hundreds of thousands of elements even after compression. However, the most commonly used autoregressive models, Transformers, are prohibitively expensive to scale to the number of inputs and layers needed to capture this long-range structure. We develop Perceiver AR, an autoregressive, modality-agnostic architecture which uses cross-attention to map long-range inputs to a small number of latents while also maintaining end-to-end causal masking. Perceiver AR can directly attend to over a hundred thousand tokens, enabling practical long-context density estimation without the need for hand-crafted sparsity patterns or memory mechanisms. When trained on images or music, Perceiver AR generates outputs with clear long-term coherence and structure. Our architecture also obtains state-of-the-art likelihood on long-sequence benchmarks, including 64 x 64 ImageNet images and PG-19 books.
Structure-aware generation of drug-like molecules
Nov 07, 2021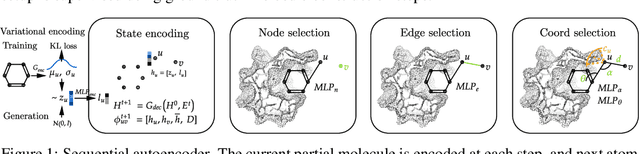
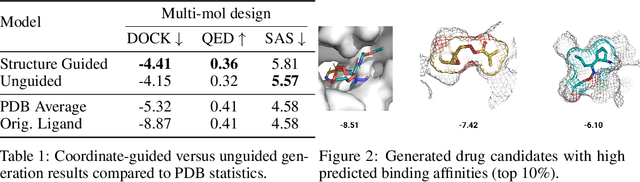
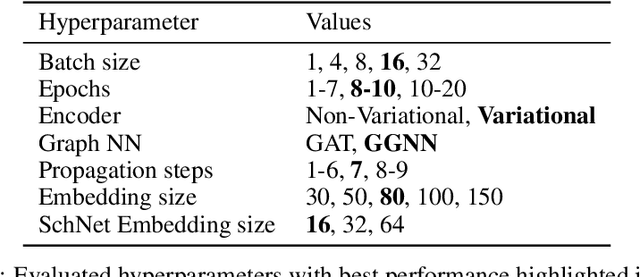
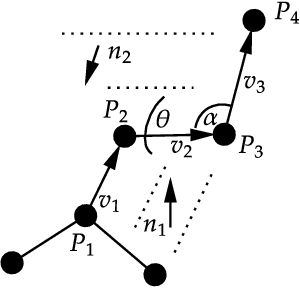
Structure-based drug design involves finding ligand molecules that exhibit structural and chemical complementarity to protein pockets. Deep generative methods have shown promise in proposing novel molecules from scratch (de-novo design), avoiding exhaustive virtual screening of chemical space. Most generative de-novo models fail to incorporate detailed ligand-protein interactions and 3D pocket structures. We propose a novel supervised model that generates molecular graphs jointly with 3D pose in a discretised molecular space. Molecules are built atom-by-atom inside pockets, guided by structural information from crystallographic data. We evaluate our model using a docking benchmark and find that guided generation improves predicted binding affinities by 8% and drug-likeness scores by 10% over the baseline. Furthermore, our model proposes molecules with binding scores exceeding some known ligands, which could be useful in future wet-lab studies.
Message Passing Neural Processes
Sep 29, 2020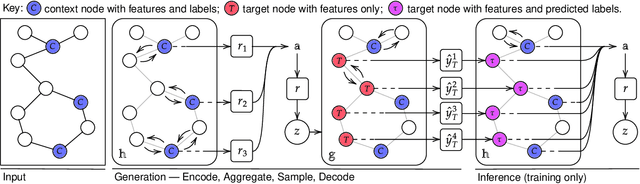
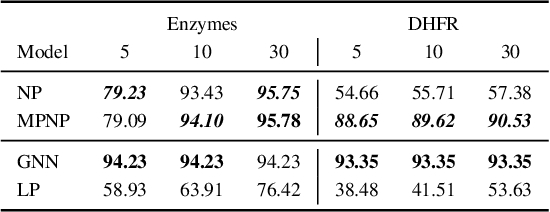
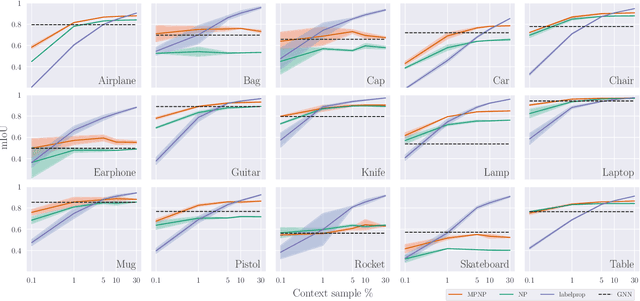
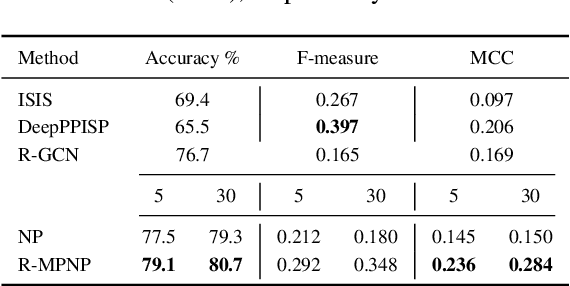
Neural Processes (NPs) are powerful and flexible models able to incorporate uncertainty when representing stochastic processes, while maintaining a linear time complexity. However, NPs produce a latent description by aggregating independent representations of context points and lack the ability to exploit relational information present in many datasets. This renders NPs ineffective in settings where the stochastic process is primarily governed by neighbourhood rules, such as cellular automata (CA), and limits performance for any task where relational information remains unused. We address this shortcoming by introducing Message Passing Neural Processes (MPNPs), the first class of NPs that explicitly makes use of relational structure within the model. Our evaluation shows that MPNPs thrive at lower sampling rates, on existing benchmarks and newly-proposed CA and Cora-Branched tasks. We further report strong generalisation over density-based CA rule-sets and significant gains in challenging arbitrary-labelling and few-shot learning setups.
Generative Graph Perturbations for Scene Graph Prediction
Jul 11, 2020



Inferring objects and their relationships from an image is useful in many applications at the intersection of vision and language. Due to a long tail data distribution, the task is challenging, with the inevitable appearance of zero-shot compositions of objects and relationships at test time. Current models often fail to properly understand a scene in such cases, as during training they only observe a tiny fraction of the distribution corresponding to the most frequent compositions. This motivates us to study whether increasing the diversity of the training distribution, by generating replacement for parts of real scene graphs, can lead to better generalization? We employ generative adversarial networks (GANs) conditioned on scene graphs to generate augmented visual features. To increase their diversity, we propose several strategies to perturb the conditioning. One of them is to use a language model, such as BERT, to synthesize plausible yet still unlikely scene graphs. By evaluating our model on Visual Genome, we obtain both positive and negative results. This prompts us to make several observations that can potentially lead to further improvements.
Wiki-CS: A Wikipedia-Based Benchmark for Graph Neural Networks
Jul 06, 2020
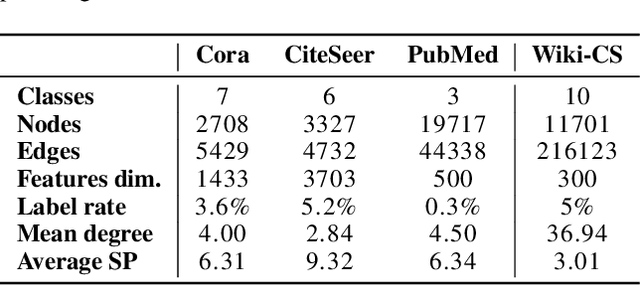
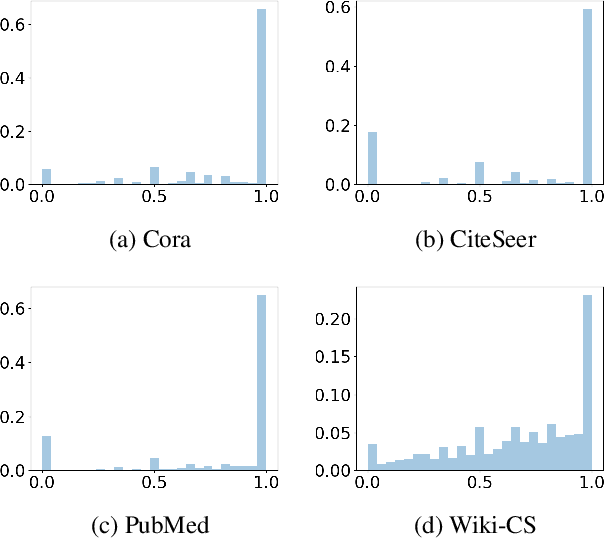
We present Wiki-CS, a novel dataset derived from Wikipedia for benchmarking Graph Neural Networks. The dataset consists of nodes corresponding to Computer Science articles, with edges based on hyperlinks and 10 classes representing different branches of the field. We use the dataset to evaluate semi-supervised node classification and single-relation link prediction models. Our experiments show that these methods perform well on a new domain, with structural properties different from earlier benchmarks. The dataset is publicly available, along with the implementation of the data pipeline and the benchmark experiments, at https://github.com/pmernyei/wiki-cs-dataset .
Graph Density-Aware Losses for Novel Compositions in Scene Graph Generation
May 17, 2020
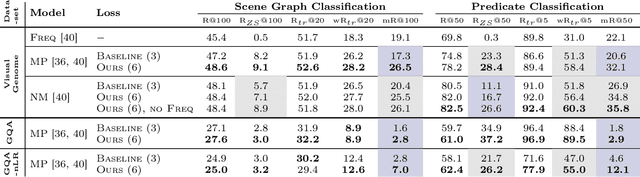
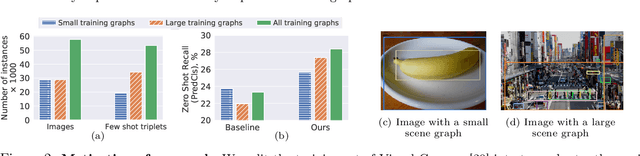
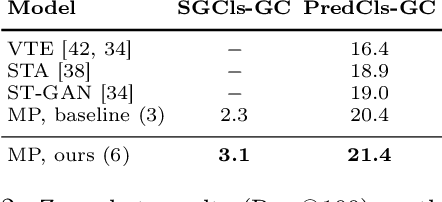
Scene graph generation (SGG) aims to predict graph-structured descriptions of input images, in the form of objects and relationships between them. This task is becoming increasingly useful for progress at the interface of vision and language. Here, it is important - yet challenging - to perform well on novel (zero-shot) or rare (few-shot) compositions of objects and relationships. In this paper, we identify two key issues that limit such generalization. Firstly, we show that the standard loss used in this task is unintentionally a function of scene graph density. This leads to the neglect of individual edges in large sparse graphs during training, even though these contain diverse few-shot examples that are important for generalization. Secondly, the frequency of relationships can create a strong bias in this task, such that a blind model predicting the most frequent relationship achieves good performance. Consequently, some state-of-the-art models exploit this bias to improve results. We show that such models can suffer the most in their ability to generalize to rare compositions, evaluating two different models on the Visual Genome dataset and its more recent, improved version, GQA. To address these issues, we introduce a density-normalized edge loss, which provides more than a two-fold improvement in certain generalization metrics. Compared to other works in this direction, our enhancements require only a few lines of code and no added computational cost. We also highlight the difficulty of accurately evaluating models using existing metrics, especially on zero/few shots, and introduce a novel weighted metric.
Deep Graph Mapper: Seeing Graphs through the Neural Lens
Feb 20, 2020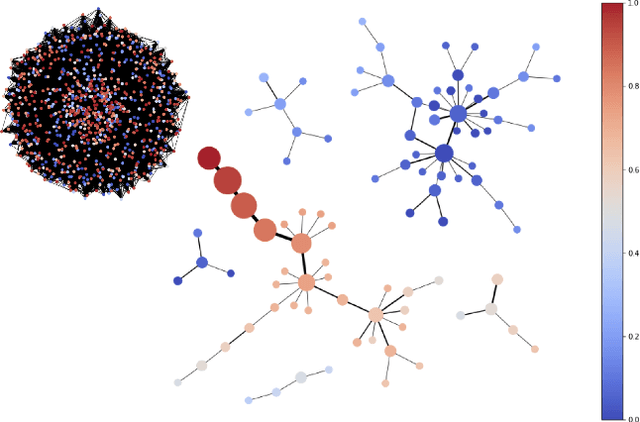
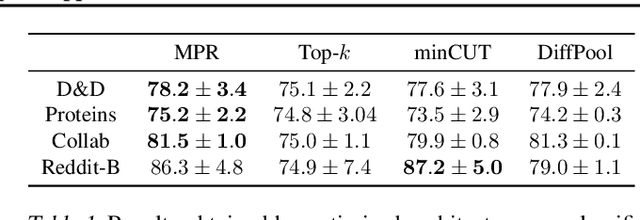
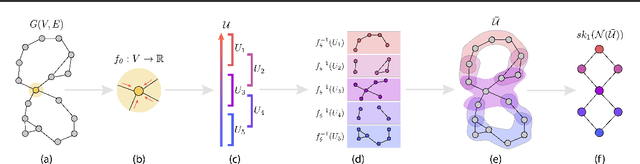
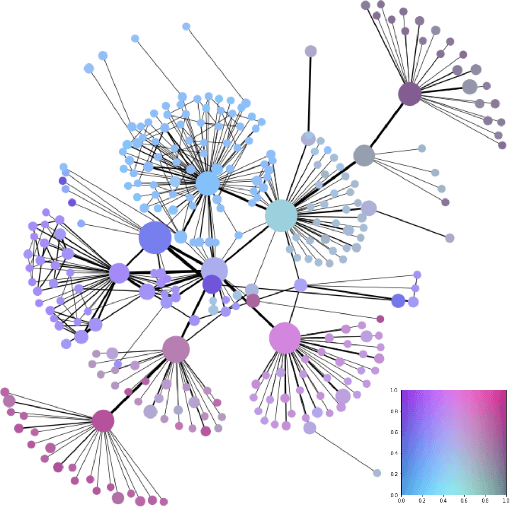
Recent advancements in graph representation learning have led to the emergence of condensed encodings that capture the main properties of a graph. However, even though these abstract representations are powerful for downstream tasks, they are not equally suitable for visualisation purposes. In this work, we merge Mapper, an algorithm from the field of Topological Data Analysis (TDA), with the expressive power of Graph Neural Networks (GNNs) to produce hierarchical, topologically-grounded visualisations of graphs. These visualisations do not only help discern the structure of complex graphs but also provide a means of understanding the models applied to them for solving various tasks. We further demonstrate the suitability of Mapper as a topological framework for graph pooling by mathematically proving an equivalence with Min-Cut and Diff Pool. Building upon this framework, we introduce a novel pooling algorithm based on PageRank, which obtains competitive results with state of the art methods on graph classification benchmarks.
The PlayStation Reinforcement Learning Environment (PSXLE)
Dec 12, 2019
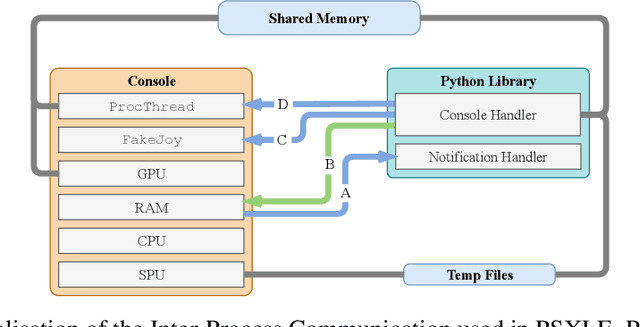
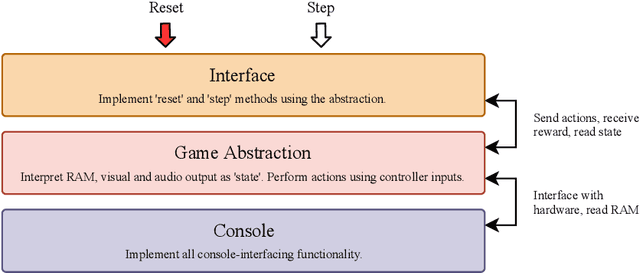

We propose a new benchmark environment for evaluating Reinforcement Learning (RL) algorithms: the PlayStation Learning Environment (PSXLE), a PlayStation emulator modified to expose a simple control API that enables rich game-state representations. We argue that the PlayStation serves as a suitable progression for agent evaluation and propose a framework for such an evaluation. We build an action-driven abstraction for a PlayStation game with support for the OpenAI Gym interface and demonstrate its use by running OpenAI Baselines.