 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal Evidence that Language Models use Confidence to Drive Behavior
Mar 23, 2026Metacognition -- the ability to assess one's own cognitive performance -- is documented across species, with internal confidence estimates serving as a key signal for adaptive behavior. While confidence can be extracted from Large Language Model (LLM) outputs, whether models actively use these signals to regulate behavior remains a fundamental question. We investigate this through a four-phase abstention paradigm.Phase 1 established internal confidence estimates in the absence of an abstention option. Phase 2 revealed that LLMs apply implicit thresholds to these estimates when deciding to answer or abstain. Confidence emerged as the dominant predictor of behavior, with effect sizes an order of magnitude larger than knowledge retrieval accessibility (RAG scores) or surface-level semantic features. Phase 3 provided causal evidence through activation steering: manipulating internal confidence signals correspondingly shifted abstention rates. Finally, Phase 4 demonstrated that models can systematically vary abstention policies based on instructed thresholds.Our findings indicate that abstention arises from the joint operation of internal confidence representations and threshold-based policies, mirroring the two-stage metacognitive control found in biological systems. This capacity is essential as LLMs transition into autonomous agents that must recognize their own uncertainty to decide when to act or seek help.
How do LLMs Compute Verbal Confidence
Mar 18, 2026Verbal confidence -- prompting LLMs to state their confidence as a number or category -- is widely used to extract uncertainty estimates from black-box models. However, how LLMs internally generate such scores remains unknown. We address two questions: first, when confidence is computed - just-in-time when requested, or automatically during answer generation and cached for later retrieval; and second, what verbal confidence represents - token log-probabilities, or a richer evaluation of answer quality? Focusing on Gemma 3 27B and Qwen 2.5 7B, we provide convergent evidence for cached retrieval. Activation steering, patching, noising, and swap experiments reveal that confidence representations emerge at answer-adjacent positions before appearing at the verbalization site. Attention blocking pinpoints the information flow: confidence is gathered from answer tokens, cached at the first post-answer position, then retrieved for output. Critically, linear probing and variance partitioning reveal that these cached representations explain substantial variance in verbal confidence beyond token log-probabilities, suggesting a richer answer-quality evaluation rather than a simple fluency readout. These findings demonstrate that verbal confidence reflects automatic, sophisticated self-evaluation -- not post-hoc reconstruction -- with implications for understanding metacognition in LLMs and improving calibration.
TAPNext: Tracking Any Point (TAP) as Next Token Prediction
Apr 08, 2025Tracking Any Point (TAP) in a video is a challenging computer vision problem with many demonstrated applications in robotics, video editing, and 3D reconstruction. Existing methods for TAP rely heavily on complex tracking-specific inductive biases and heuristics, limiting their generality and potential for scaling. To address these challenges, we present TAPNext, a new approach that casts TAP as sequential masked token decoding. Our model is causal, tracks in a purely online fashion, and removes tracking-specific inductive biases. This enables TAPNext to run with minimal latency, and removes the temporal windowing required by many existing state of art trackers. Despite its simplicity, TAPNext achieves a new state-of-the-art tracking performance among both online and offline trackers. Finally, we present evidence that many widely used tracking heuristics emerge naturally in TAPNext through end-to-end training.
A Simple Recipe for Contrastively Pre-training Video-First Encoders Beyond 16 Frames
Dec 12, 2023



Understanding long, real-world videos requires modeling of long-range visual dependencies. To this end, we explore video-first architectures, building on the common paradigm of transferring large-scale, image--text models to video via shallow temporal fusion. However, we expose two limitations to the approach: (1) decreased spatial capabilities, likely due to poor video--language alignment in standard video datasets, and (2) higher memory consumption, bottlenecking the number of frames that can be processed. To mitigate the memory bottleneck, we systematically analyze the memory/accuracy trade-off of various efficient methods: factorized attention, parameter-efficient image-to-video adaptation, input masking, and multi-resolution patchification. Surprisingly, simply masking large portions of the video (up to 75%) during contrastive pre-training proves to be one of the most robust ways to scale encoders to videos up to 4.3 minutes at 1 FPS. Our simple approach for training long video-to-text models, which scales to 1B parameters, does not add new architectural complexity and is able to outperform the popular paradigm of using much larger LLMs as an information aggregator over segment-based information on benchmarks with long-range temporal dependencies (YouCook2, EgoSchema).
Active Acquisition for Multimodal Temporal Data: A Challenging Decision-Making Task
Nov 09, 2022

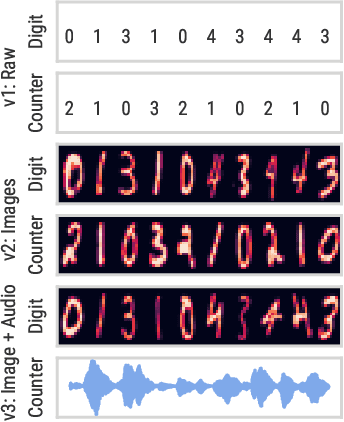

We introduce a challenging decision-making task that we call active acquisition for multimodal temporal data (A2MT). In many real-world scenarios, input features are not readily available at test time and must instead be acquired at significant cost. With A2MT, we aim to learn agents that actively select which modalities of an input to acquire, trading off acquisition cost and predictive performance. A2MT extends a previous task called active feature acquisition to temporal decision making about high-dimensional inputs. Further, we propose a method based on the Perceiver IO architecture to address A2MT in practice. Our agents are able to solve a novel synthetic scenario requiring practically relevant cross-modal reasoning skills. On two large-scale, real-world datasets, Kinetics-700 and AudioSet, our agents successfully learn cost-reactive acquisition behavior. However, an ablation reveals they are unable to learn to learn adaptive acquisition strategies, emphasizing the difficulty of the task even for state-of-the-art models. Applications of A2MT may be impactful in domains like medicine, robotics, or finance, where modalities differ in acquisition cost and informativeness.
Gradient Forward-Propagation for Large-Scale Temporal Video Modelling
Jul 12, 2021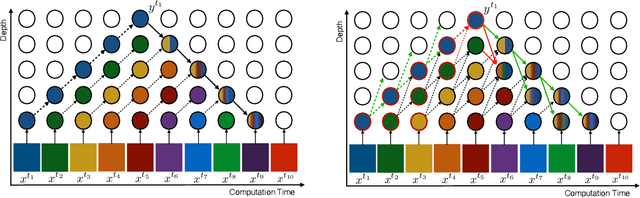
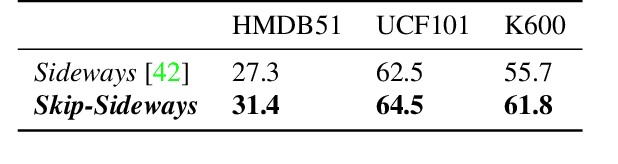
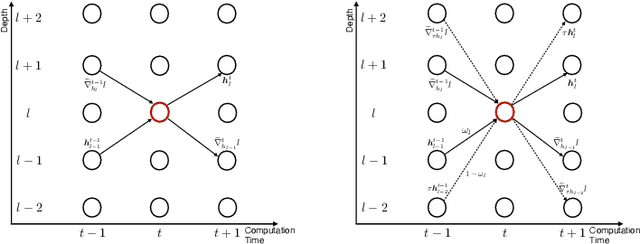

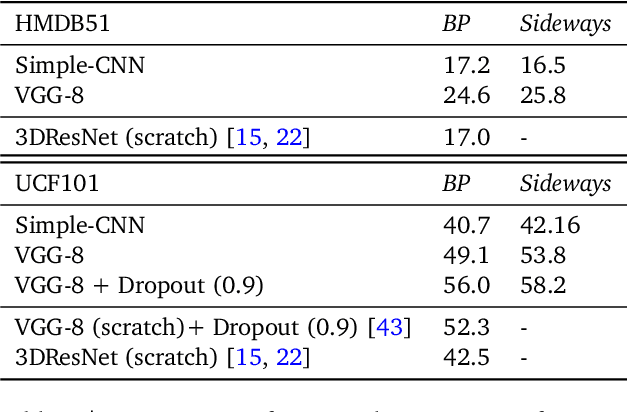
How can neural networks be trained on large-volume temporal data efficiently? To compute the gradients required to update parameters, backpropagation blocks computations until the forward and backward passes are completed. For temporal signals, this introduces high latency and hinders real-time learning. It also creates a coupling between consecutive layers, which limits model parallelism and increases memory consumption. In this paper, we build upon Sideways, which avoids blocking by propagating approximate gradients forward in time, and we propose mechanisms for temporal integration of information based on different variants of skip connections. We also show how to decouple computation and delegate individual neural modules to different devices, allowing distributed and parallel training. The proposed Skip-Sideways achieves low latency training, model parallelism, and, importantly, is capable of extracting temporal features, leading to more stable training and improved performance on real-world action recognition video datasets such as HMDB51, UCF101, and the large-scale Kinetics-600. Finally, we also show that models trained with Skip-Sideways generate better future frames than Sideways models, and hence they can better utilize motion cues.
Broaden Your Views for Self-Supervised Video Learning
Mar 30, 2021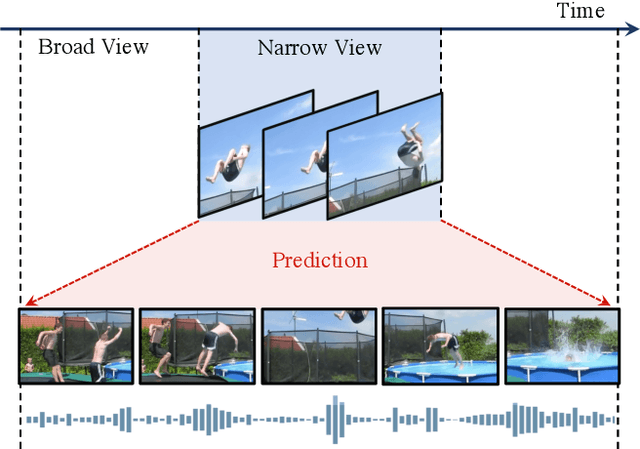
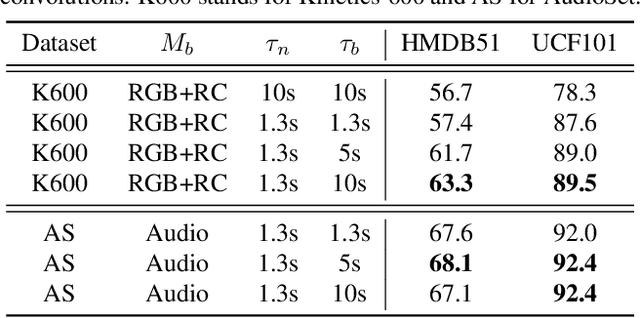
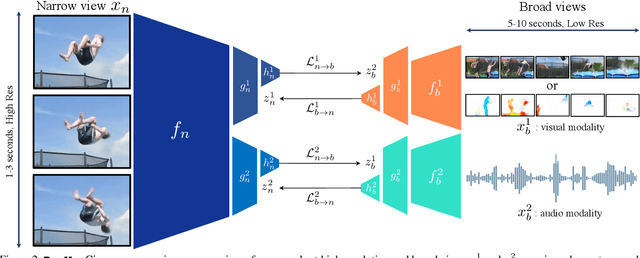
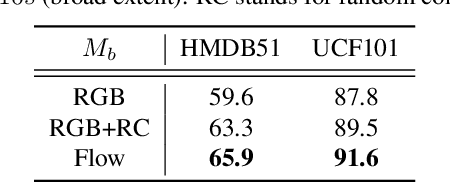
Most successful self-supervised learning methods are trained to align the representations of two independent views from the data. State-of-the-art methods in video are inspired by image techniques, where these two views are similarly extracted by cropping and augmenting the resulting crop. However, these methods miss a crucial element in the video domain: time. We introduce BraVe, a self-supervised learning framework for video. In BraVe, one of the views has access to a narrow temporal window of the video while the other view has a broad access to the video content. Our models learn to generalise from the narrow view to the general content of the video. Furthermore, BraVe processes the views with different backbones, enabling the use of alternative augmentations or modalities into the broad view such as optical flow, randomly convolved RGB frames, audio or their combinations. We demonstrate that BraVe achieves state-of-the-art results in self-supervised representation learning on standard video and audio classification benchmarks including UCF101, HMDB51, Kinetics, ESC-50 and AudioSet.
Sideways: Depth-Parallel Training of Video Models
Jan 17, 2020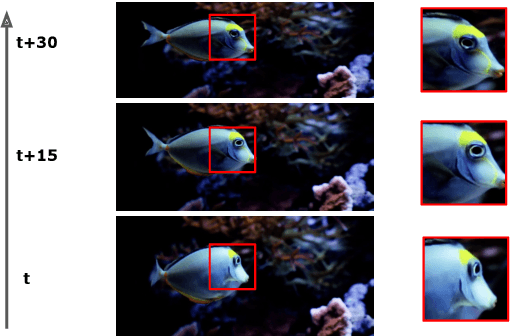
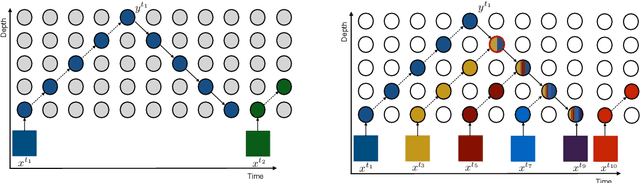
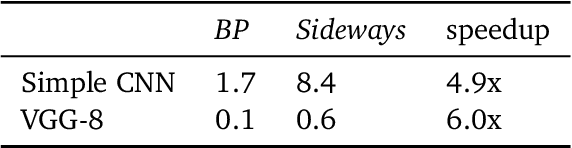
We propose Sideways, an approximate backpropagation scheme for training video models. In standard backpropagation, the gradients and activations at every computation step through the model are temporally synchronized. The forward activations need to be stored until the backward pass is executed, preventing inter-layer (depth) parallelization. However, can we leverage smooth, redundant input streams such as videos to develop a more efficient training scheme? Here, we explore an alternative to backpropagation; we overwrite network activations whenever new ones, i.e., from new frames, become available. Such a more gradual accumulation of information from both passes breaks the precise correspondence between gradients and activations, leading to theoretically more noisy weight updates. Counter-intuitively, we show that Sideways training of deep convolutional video networks not only still converges, but can also potentially exhibit better generalization compared to standard synchronized backpropagation.
Massively Parallel Video Networks
Sep 05, 2018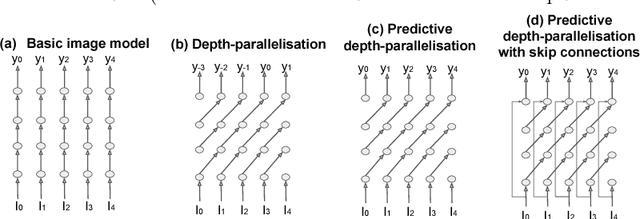

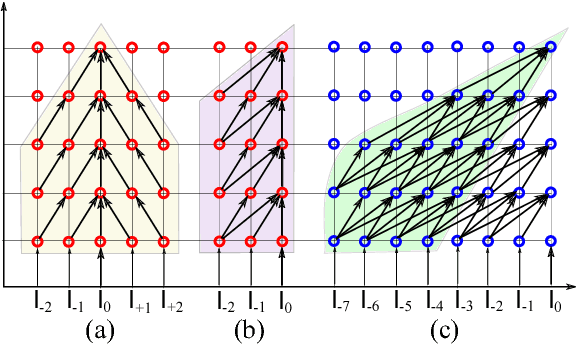
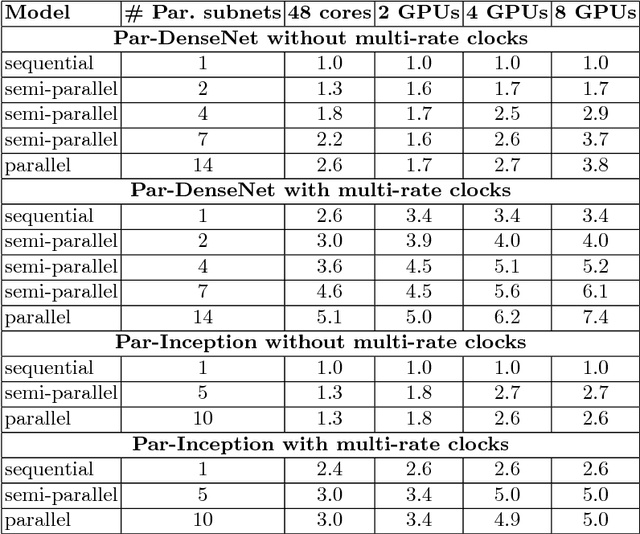
We introduce a class of causal video understanding models that aims to improve efficiency of video processing by maximising throughput, minimising latency, and reducing the number of clock cycles. Leveraging operation pipelining and multi-rate clocks, these models perform a minimal amount of computation (e.g. as few as four convolutional layers) for each frame per timestep to produce an output. The models are still very deep, with dozens of such operations being performed but in a pipelined fashion that enables depth-parallel computation. We illustrate the proposed principles by applying them to existing image architectures and analyse their behaviour on two video tasks: action recognition and human keypoint localisation. The results show that a significant degree of parallelism, and implicitly speedup, can be achieved with little loss in performance.
Spatio-temporal video autoencoder with differentiable memory
Sep 01, 2016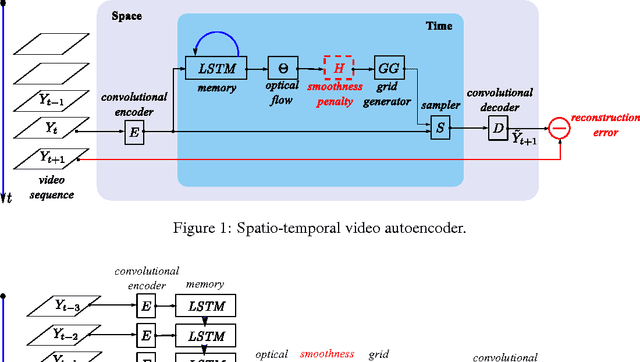
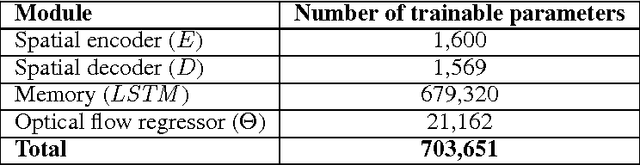


We describe a new spatio-temporal video autoencoder, based on a classic spatial image autoencoder and a novel nested temporal autoencoder. The temporal encoder is represented by a differentiable visual memory composed of convolutional long short-term memory (LSTM) cells that integrate changes over time. Here we target motion changes and use as temporal decoder a robust optical flow prediction module together with an image sampler serving as built-in feedback loop. The architecture is end-to-end differentiable. At each time step, the system receives as input a video frame, predicts the optical flow based on the current observation and the LSTM memory state as a dense transformation map, and applies it to the current frame to generate the next frame. By minimising the reconstruction error between the predicted next frame and the corresponding ground truth next frame, we train the whole system to extract features useful for motion estimation without any supervision effort. We present one direct application of the proposed framework in weakly-supervised semantic segmentation of videos through label propagation using optical flow.