 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo LLMs Really Need 10+ Thoughts for "Find the Time 1000 Days Later"? Towards Structural Understanding of LLM Overthinking
Oct 09, 2025



Models employing long chain-of-thought (CoT) reasoning have shown superior performance on complex reasoning tasks. Yet, this capability introduces a critical and often overlooked inefficiency -- overthinking -- models often engage in unnecessarily extensive reasoning even for simple queries, incurring significant computations without accuracy improvements. While prior work has explored solutions to mitigate overthinking, a fundamental gap remains in our understanding of its underlying causes. Most existing analyses are limited to superficial, profiling-based observations, failing to delve into LLMs' inner workings. This study introduces a systematic, fine-grained analyzer of LLMs' thought process to bridge the gap, TRACE. We first benchmark the overthinking issue, confirming that long-thinking models are five to twenty times slower on simple tasks with no substantial gains. We then use TRACE to first decompose the thought process into minimally complete sub-thoughts. Next, by inferring discourse relationships among sub-thoughts, we construct granular thought progression graphs and subsequently identify common thinking patterns for topically similar queries. Our analysis reveals two major patterns for open-weight thinking models -- Explorer and Late Landing. This finding provides evidence that over-verification and over-exploration are the primary drivers of overthinking in LLMs. Grounded in thought structures, we propose a utility-based definition of overthinking, which moves beyond length-based metrics. This revised definition offers a more insightful understanding of LLMs' thought progression, as well as practical guidelines for principled overthinking management.
Dynamic Classifier-Free Diffusion Guidance via Online Feedback
Sep 19, 2025



Classifier-free guidance (CFG) is a cornerstone of text-to-image diffusion models, yet its effectiveness is limited by the use of static guidance scales. This "one-size-fits-all" approach fails to adapt to the diverse requirements of different prompts; moreover, prior solutions like gradient-based correction or fixed heuristic schedules introduce additional complexities and fail to generalize. In this work, we challeng this static paradigm by introducing a framework for dynamic CFG scheduling. Our method leverages online feedback from a suite of general-purpose and specialized small-scale latent-space evaluations, such as CLIP for alignment, a discriminator for fidelity and a human preference reward model, to assess generation quality at each step of the reverse diffusion process. Based on this feedback, we perform a greedy search to select the optimal CFG scale for each timestep, creating a unique guidance schedule tailored to every prompt and sample. We demonstrate the effectiveness of our approach on both small-scale models and the state-of-the-art Imagen 3, showing significant improvements in text alignment, visual quality, text rendering and numerical reasoning. Notably, when compared against the default Imagen 3 baseline, our method achieves up to 53.8% human preference win-rate for overall preference, a figure that increases up to to 55.5% on prompts targeting specific capabilities like text rendering. Our work establishes that the optimal guidance schedule is inherently dynamic and prompt-dependent, and provides an efficient and generalizable framework to achieve it.
PaliGemma: A versatile 3B VLM for transfer
Jul 10, 2024



PaliGemma is an open Vision-Language Model (VLM) that is based on the SigLIP-So400m vision encoder and the Gemma-2B language model. It is trained to be a versatile and broadly knowledgeable base model that is effective to transfer. It achieves strong performance on a wide variety of open-world tasks. We evaluate PaliGemma on almost 40 diverse tasks including standard VLM benchmarks, but also more specialized tasks such as remote-sensing and segmentation.
Memory Consolidation Enables Long-Context Video Understanding
Feb 08, 2024



Most transformer-based video encoders are limited to short temporal contexts due to their quadratic complexity. While various attempts have been made to extend this context, this has often come at the cost of both conceptual and computational complexity. We propose to instead re-purpose existing pre-trained video transformers by simply fine-tuning them to attend to memories derived non-parametrically from past activations. By leveraging redundancy reduction, our memory-consolidated vision transformer (MC-ViT) effortlessly extends its context far into the past and exhibits excellent scaling behavior when learning from longer videos. In doing so, MC-ViT sets a new state-of-the-art in long-context video understanding on EgoSchema, Perception Test, and Diving48, outperforming methods that benefit from orders of magnitude more parameters.
A Simple Recipe for Contrastively Pre-training Video-First Encoders Beyond 16 Frames
Dec 12, 2023



Understanding long, real-world videos requires modeling of long-range visual dependencies. To this end, we explore video-first architectures, building on the common paradigm of transferring large-scale, image--text models to video via shallow temporal fusion. However, we expose two limitations to the approach: (1) decreased spatial capabilities, likely due to poor video--language alignment in standard video datasets, and (2) higher memory consumption, bottlenecking the number of frames that can be processed. To mitigate the memory bottleneck, we systematically analyze the memory/accuracy trade-off of various efficient methods: factorized attention, parameter-efficient image-to-video adaptation, input masking, and multi-resolution patchification. Surprisingly, simply masking large portions of the video (up to 75%) during contrastive pre-training proves to be one of the most robust ways to scale encoders to videos up to 4.3 minutes at 1 FPS. Our simple approach for training long video-to-text models, which scales to 1B parameters, does not add new architectural complexity and is able to outperform the popular paradigm of using much larger LLMs as an information aggregator over segment-based information on benchmarks with long-range temporal dependencies (YouCook2, EgoSchema).
Hierarchical3D Adapters for Long Video-to-text Summarization
Oct 10, 2022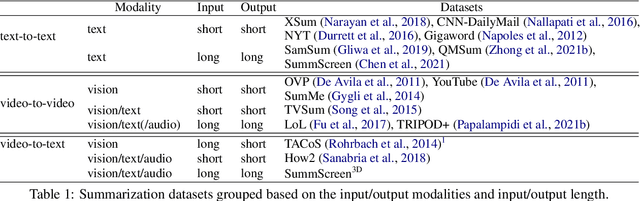
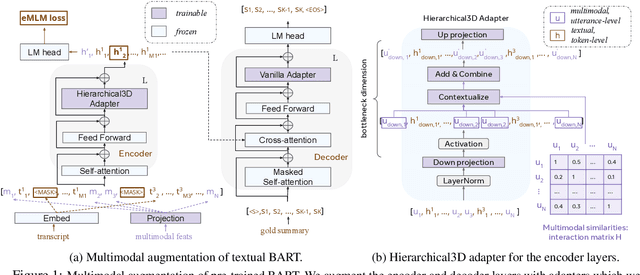
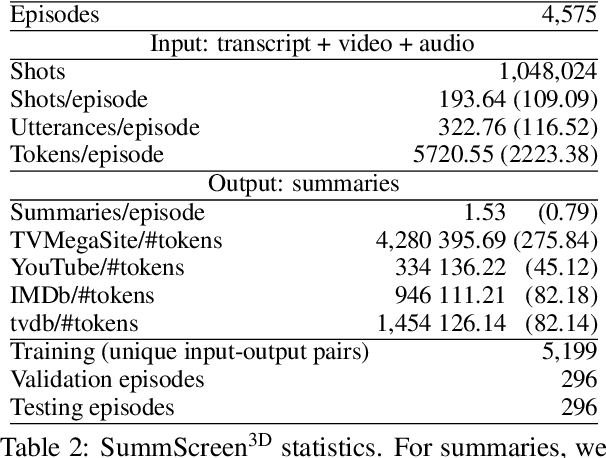
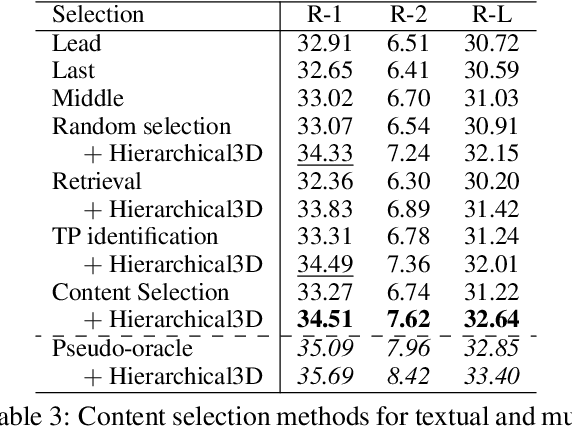
In this paper, we focus on video-to-text summarization and investigate how to best utilize multimodal information for summarizing long inputs (e.g., an hour-long TV show) into long outputs (e.g., a multi-sentence summary). We extend SummScreen (Chen et al., 2021), a dialogue summarization dataset consisting of transcripts of TV episodes with reference summaries, and create a multimodal variant by collecting corresponding full-length videos. We incorporate multimodal information into a pre-trained textual summarizer efficiently using adapter modules augmented with a hierarchical structure while tuning only 3.8\% of model parameters. Our experiments demonstrate that multimodal information offers superior performance over more memory-heavy and fully fine-tuned textual summarization methods.
Towards Coherent and Consistent Use of Entities in Narrative Generation
Feb 03, 2022
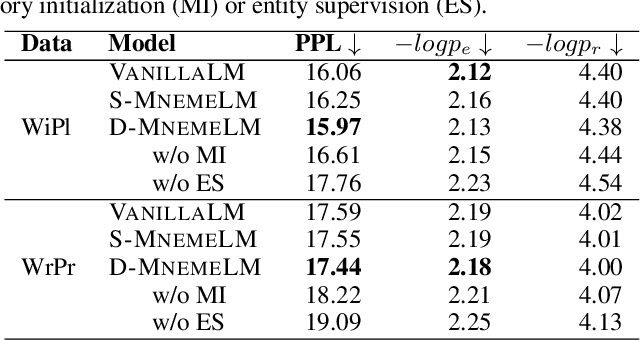
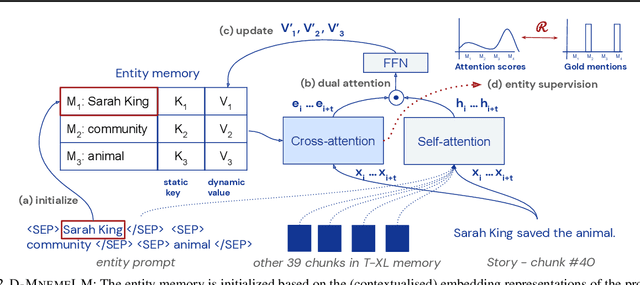
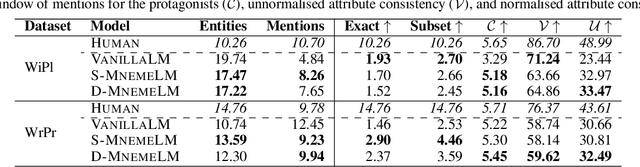
Large pre-trained language models (LMs) have demonstrated impressive capabilities in generating long, fluent text; however, there is little to no analysis on their ability to maintain entity coherence and consistency. In this work, we focus on the end task of narrative generation and systematically analyse the long-range entity coherence and consistency in generated stories. First, we propose a set of automatic metrics for measuring model performance in terms of entity usage. Given these metrics, we quantify the limitations of current LMs. Next, we propose augmenting a pre-trained LM with a dynamic entity memory in an end-to-end manner by using an auxiliary entity-related loss for guiding the reads and writes to the memory. We demonstrate that the dynamic entity memory increases entity coherence according to both automatic and human judgment and helps preserving entity-related information especially in settings with a limited context window. Finally, we also validate that our automatic metrics are correlated with human ratings and serve as a good indicator of the quality of generated stories.
Film Trailer Generation via Task Decomposition
Nov 16, 2021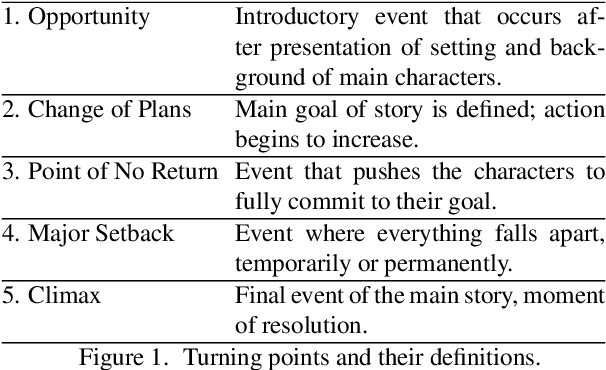
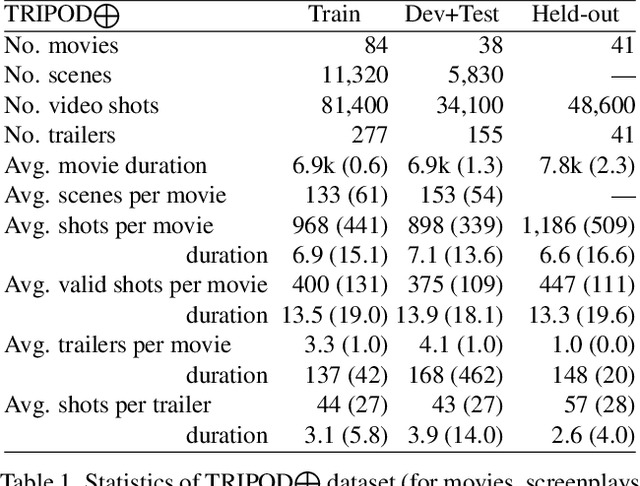
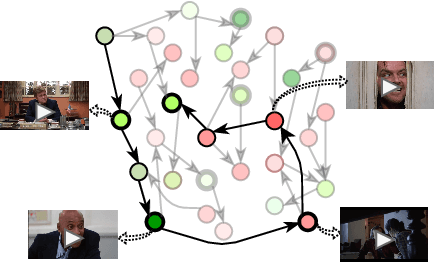
Movie trailers perform multiple functions: they introduce viewers to the story, convey the mood and artistic style of the film, and encourage audiences to see the movie. These diverse functions make automatic trailer generation a challenging endeavor. We decompose it into two subtasks: narrative structure identification and sentiment prediction. We model movies as graphs, where nodes are shots and edges denote semantic relations between them. We learn these relations using joint contrastive training which leverages privileged textual information (e.g., characters, actions, situations) from screenplays. An unsupervised algorithm then traverses the graph and generates trailers that human judges prefer to ones generated by competitive supervised approaches.
Movie Summarization via Sparse Graph Construction
Dec 14, 2020
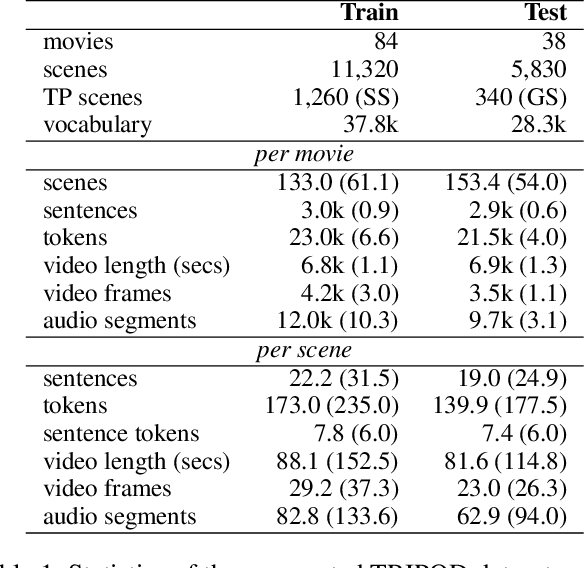
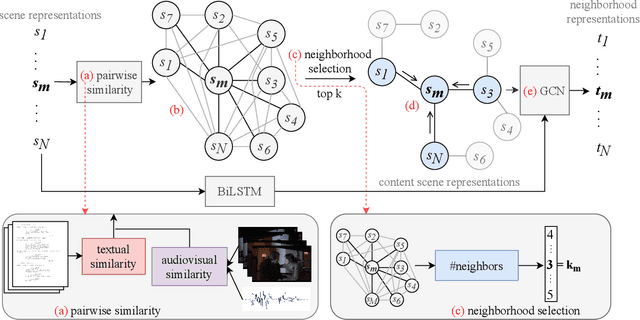
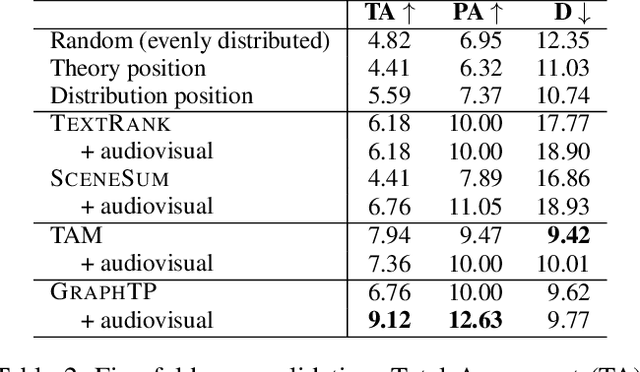
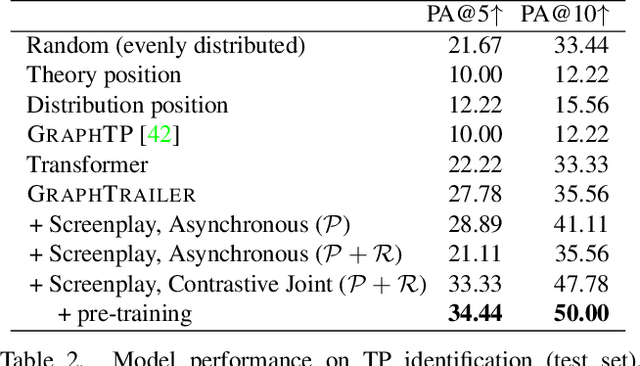
We summarize full-length movies by creating shorter videos containing their most informative scenes. We explore the hypothesis that a summary can be created by assembling scenes which are turning points (TPs), i.e., key events in a movie that describe its storyline. We propose a model that identifies TP scenes by building a sparse movie graph that represents relations between scenes and is constructed using multimodal information. According to human judges, the summaries created by our approach are more informative and complete, and receive higher ratings, than the outputs of sequence-based models and general-purpose summarization algorithms. The induced graphs are interpretable, displaying different topology for different movie genres.
Screenplay Summarization Using Latent Narrative Structure
Apr 27, 2020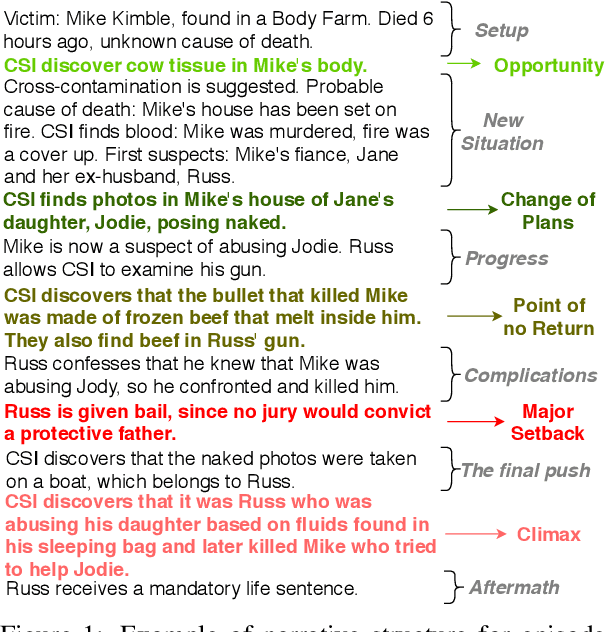

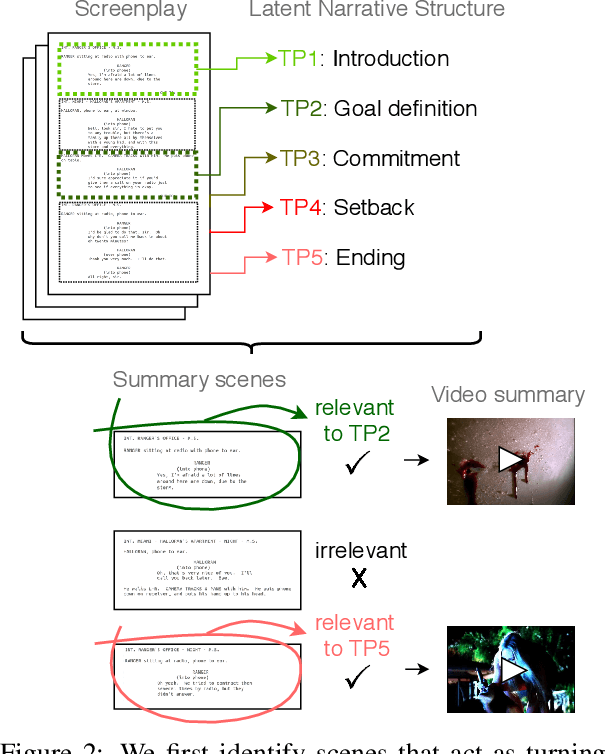
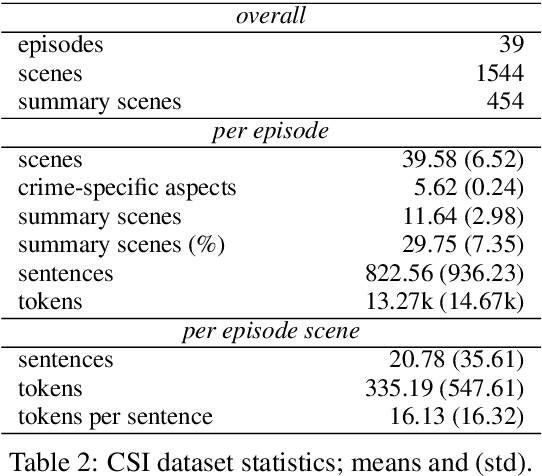
Most general-purpose extractive summarization models are trained on news articles, which are short and present all important information upfront. As a result, such models are biased on position and often perform a smart selection of sentences from the beginning of the document. When summarizing long narratives, which have complex structure and present information piecemeal, simple position heuristics are not sufficient. In this paper, we propose to explicitly incorporate the underlying structure of narratives into general unsupervised and supervised extractive summarization models. We formalize narrative structure in terms of key narrative events (turning points) and treat it as latent in order to summarize screenplays (i.e., extract an optimal sequence of scenes). Experimental results on the CSI corpus of TV screenplays, which we augment with scene-level summarization labels, show that latent turning points correlate with important aspects of a CSI episode and improve summarization performance over general extractive algorithms leading to more complete and diverse summaries.