 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Benchmarking Is Just Feature Selection and Multiple Regression
May 25, 2026Efficient benchmarking techniques aim to lower the computational cost of evaluating LLMs by predicting full benchmark scores using only a subset of a benchmark's questions. By reframing this problem as an instance of multiple regression with feature selection, we find that existing efficient benchmarking methods can be greatly improved by simply using kernel ridge regression at the prediction stage. Additionally, using an information-theoretic feature-selection algorithm called minimum redundancy maximum relevance (mRMR), we can further improve upon these methods by selecting question subsets that will be maximally useful for prediction. Except in very data-poor settings, these approaches consistently achieve smaller prediction errors (in both MAE and RMSE), and greater ranking correlation between predicted and true scores (in both Spearman $ρ$ and Kendall $τ$) across a range of benchmarks using both binary and continuous metrics. Furthermore, mRMR subsampling is much faster than competitor methods (which often involve fitting probabilistic models or running clustering algorithms), and is more likely to select the same questions under different random seeds or training data splits. Tutorial code can be found at https://github.com/sambowyer/mrmr_eval .
One Tokenizer To Rule Them All: Emergent Language Plasticity via Multilingual Tokenizers
Jun 12, 2025Pretraining massively multilingual Large Language Models (LLMs) for many languages at once is challenging due to limited model capacity, scarce high-quality data, and compute constraints. Moreover, the lack of language coverage of the tokenizer makes it harder to address the gap for new languages purely at the post-training stage. In this work, we study what relatively cheap interventions early on in training improve "language plasticity", or adaptation capabilities of the model post-training to new languages. We focus on tokenizer design and propose using a universal tokenizer that is trained for more languages than the primary pretraining languages to enable efficient adaptation in expanding language coverage after pretraining. Our systematic experiments across diverse groups of languages and different training strategies show that a universal tokenizer enables significantly higher language adaptation, with up to 20.2% increase in win rates compared to tokenizers specific to pretraining languages. Furthermore, a universal tokenizer also leads to better plasticity towards languages that are completely unseen in the tokenizer and pretraining, by up to 5% win rate gain. We achieve this adaptation to an expanded set of languages with minimal compromise in performance on the majority of languages included in pretraining.
Command A: An Enterprise-Ready Large Language Model
Apr 01, 2025



In this report we describe the development of Command A, a powerful large language model purpose-built to excel at real-world enterprise use cases. Command A is an agent-optimised and multilingual-capable model, with support for 23 languages of global business, and a novel hybrid architecture balancing efficiency with top of the range performance. It offers best-in-class Retrieval Augmented Generation (RAG) capabilities with grounding and tool use to automate sophisticated business processes. These abilities are achieved through a decentralised training approach, including self-refinement algorithms and model merging techniques. We also include results for Command R7B which shares capability and architectural similarities to Command A. Weights for both models have been released for research purposes. This technical report details our original training pipeline and presents an extensive evaluation of our models across a suite of enterprise-relevant tasks and public benchmarks, demonstrating excellent performance and efficiency.
Unpacking Tokenization: Evaluating Text Compression and its Correlation with Model Performance
Mar 10, 2024Despite it being the cornerstone of BPE, the most common tokenization algorithm, the importance of compression in the tokenization process is still unclear. In this paper, we argue for the theoretical importance of compression, that can be viewed as 0-gram language modeling where equal probability is assigned to all tokens. We also demonstrate the empirical importance of compression for downstream success of pre-trained language models. We control the compression ability of several BPE tokenizers by varying the amount of documents available during their training: from 1 million documents to a character-based tokenizer equivalent to no training data at all. We then pre-train English language models based on those tokenizers and fine-tune them over several tasks. We show that there is a correlation between tokenizers' compression and models' downstream performance, suggesting that compression is a reliable intrinsic indicator of tokenization quality. These correlations are more pronounced for generation tasks (over classification) or for smaller models (over large ones). We replicated a representative part of our experiments on Turkish and found similar results, confirming that our results hold for languages with typological characteristics dissimilar to English. We conclude that building better compressing tokenizers is a fruitful avenue for further research and for improving overall model performance.
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
What is the best recipe for character-level encoder-only modelling?
May 09, 2023
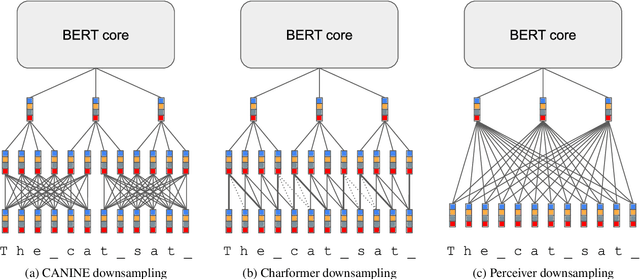

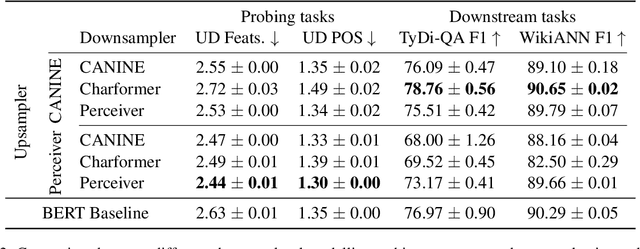
This paper aims to benchmark recent progress in language understanding models that output contextualised representations at the character level. Many such modelling architectures and methods to train those architectures have been proposed, but it is currently unclear what the relative contributions of the architecture vs. the pretraining objective are to final model performance. We explore the design space of such models, comparing architectural innovations and a variety of different pretraining objectives on a suite of evaluation tasks with a fixed training procedure in order to find the currently optimal way to build and train character-level BERT-like models. We find that our best performing character-level model exceeds the performance of a token-based model trained with the same settings on the same data, suggesting that character-level models are ready for more widespread adoption. Unfortunately, the best method to train character-level models still relies on a subword-level tokeniser during pretraining, and final model performance is highly dependent on tokeniser quality. We believe our results demonstrate the readiness of character-level models for multilingual language representation, and encourage NLP practitioners to try them as drop-in replacements for token-based models.
Towards Coherent and Consistent Use of Entities in Narrative Generation
Feb 03, 2022
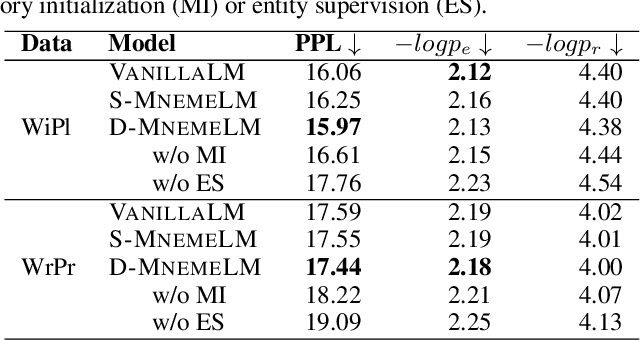
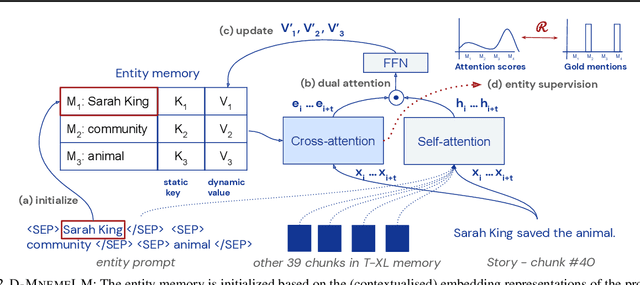
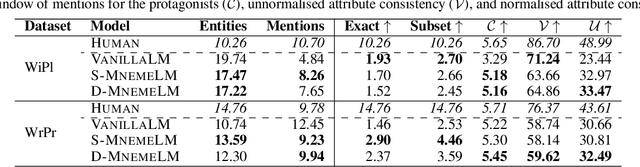
Large pre-trained language models (LMs) have demonstrated impressive capabilities in generating long, fluent text; however, there is little to no analysis on their ability to maintain entity coherence and consistency. In this work, we focus on the end task of narrative generation and systematically analyse the long-range entity coherence and consistency in generated stories. First, we propose a set of automatic metrics for measuring model performance in terms of entity usage. Given these metrics, we quantify the limitations of current LMs. Next, we propose augmenting a pre-trained LM with a dynamic entity memory in an end-to-end manner by using an auxiliary entity-related loss for guiding the reads and writes to the memory. We demonstrate that the dynamic entity memory increases entity coherence according to both automatic and human judgment and helps preserving entity-related information especially in settings with a limited context window. Finally, we also validate that our automatic metrics are correlated with human ratings and serve as a good indicator of the quality of generated stories.
Control Prefixes for Text Generation
Oct 15, 2021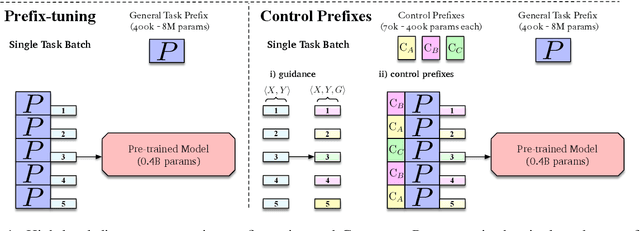

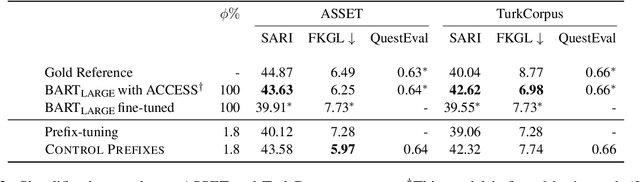
Prompt learning methods adapt pre-trained language models to downstream applications by using a task-specific prompt together with the input. Most of the current work on prompt learning in text generation relies on a shared dataset-level prompt for all examples in the dataset. We extend this approach and propose a dynamic method, Control Prefixes, which allows for the inclusion of conditional input-dependent information in each prompt. Control Prefixes is at the intersection of prompt learning and controlled generation, empowering the model to have finer-grained control during text generation. The method incorporates attribute-level learnable representations into different layers of a pre-trained transformer, allowing for the generated text to be guided in a particular direction. We provide a systematic evaluation of the technique and apply it to five datasets from the GEM benchmark for natural language generation (NLG). We present state-of-the-art results on several data-to-text datasets, including WebNLG.
You should evaluate your language model on marginal likelihood over tokenisations
Sep 21, 2021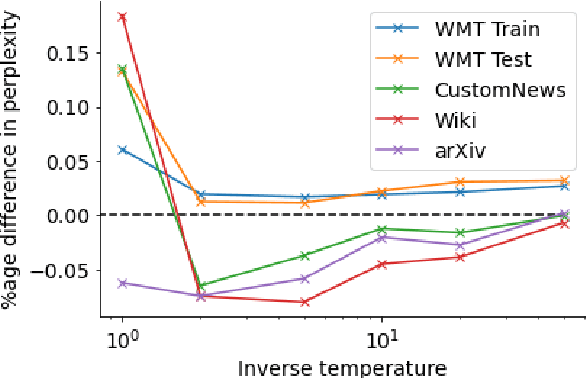
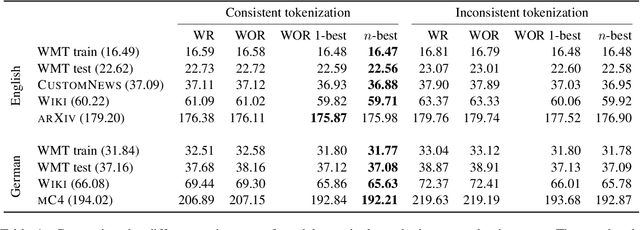
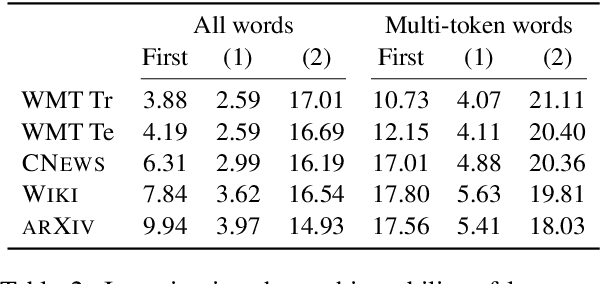
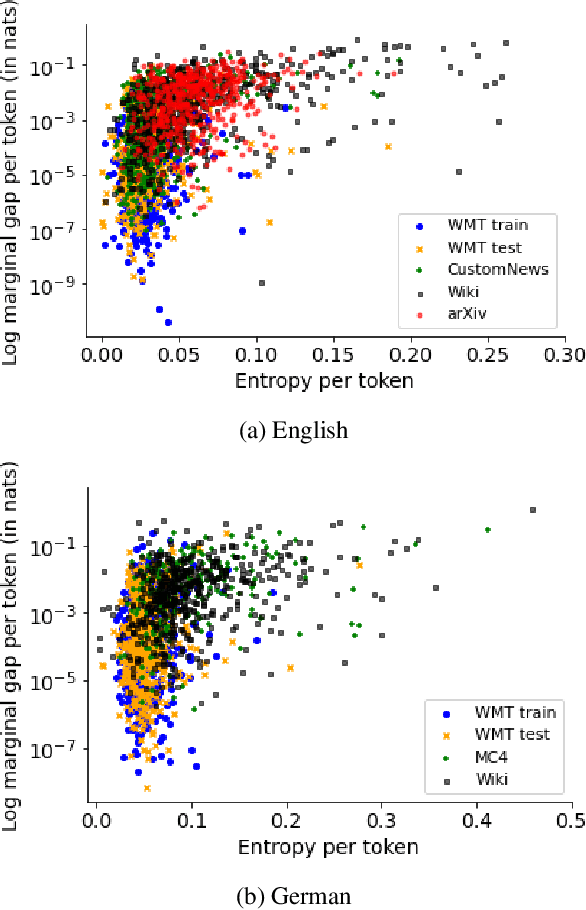
Neural language models typically tokenise input text into sub-word units to achieve an open vocabulary. The standard approach is to use a single canonical tokenisation at both train and test time. We suggest that this approach is unsatisfactory and may bottleneck our evaluation of language model performance. Using only the one-best tokenisation ignores tokeniser uncertainty over alternative tokenisations, which may hurt model out-of-domain performance. In this paper, we argue that instead, language models should be evaluated on their marginal likelihood over tokenisations. We compare different estimators for the marginal likelihood based on sampling, and show that it is feasible to estimate the marginal likelihood with a manageable number of samples. We then evaluate pretrained English and German language models on both the one-best-tokenisation and marginal perplexities, and show that the marginal perplexity can be significantly better than the one best, especially on out-of-domain data. We link this difference in perplexity to the tokeniser uncertainty as measured by tokeniser entropy. We discuss some implications of our results for language model training and evaluation, particularly with regard to tokenisation robustness.