 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControl Prefixes for Text Generation
Paper and Code
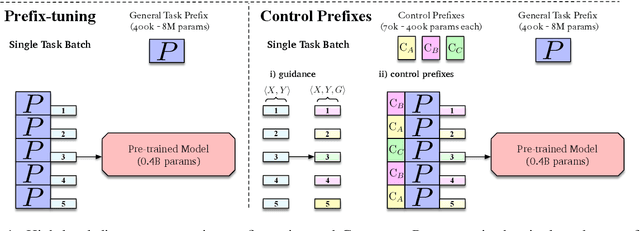

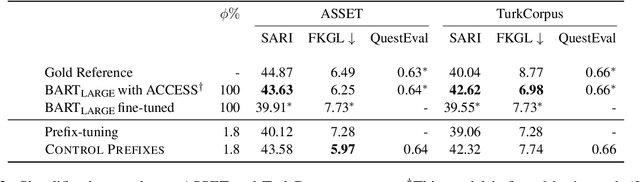
Prompt learning methods adapt pre-trained language models to downstream applications by using a task-specific prompt together with the input. Most of the current work on prompt learning in text generation relies on a shared dataset-level prompt for all examples in the dataset. We extend this approach and propose a dynamic method, Control Prefixes, which allows for the inclusion of conditional input-dependent information in each prompt. Control Prefixes is at the intersection of prompt learning and controlled generation, empowering the model to have finer-grained control during text generation. The method incorporates attribute-level learnable representations into different layers of a pre-trained transformer, allowing for the generated text to be guided in a particular direction. We provide a systematic evaluation of the technique and apply it to five datasets from the GEM benchmark for natural language generation (NLG). We present state-of-the-art results on several data-to-text datasets, including WebNLG.