 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMTEB: Massive Multilingual Text Embedding Benchmark
Feb 19, 2025Text embeddings are typically evaluated on a limited set of tasks, which are constrained by language, domain, and task diversity. To address these limitations and provide a more comprehensive evaluation, we introduce the Massive Multilingual Text Embedding Benchmark (MMTEB) - a large-scale, community-driven expansion of MTEB, covering over 500 quality-controlled evaluation tasks across 250+ languages. MMTEB includes a diverse set of challenging, novel tasks such as instruction following, long-document retrieval, and code retrieval, representing the largest multilingual collection of evaluation tasks for embedding models to date. Using this collection, we develop several highly multilingual benchmarks, which we use to evaluate a representative set of models. We find that while large language models (LLMs) with billions of parameters can achieve state-of-the-art performance on certain language subsets and task categories, the best-performing publicly available model is multilingual-e5-large-instruct with only 560 million parameters. To facilitate accessibility and reduce computational cost, we introduce a novel downsampling method based on inter-task correlation, ensuring a diverse selection while preserving relative model rankings. Furthermore, we optimize tasks such as retrieval by sampling hard negatives, creating smaller but effective splits. These optimizations allow us to introduce benchmarks that drastically reduce computational demands. For instance, our newly introduced zero-shot English benchmark maintains a ranking order similar to the full-scale version but at a fraction of the computational cost.
Lessons from the Trenches on Reproducible Evaluation of Language Models
May 23, 2024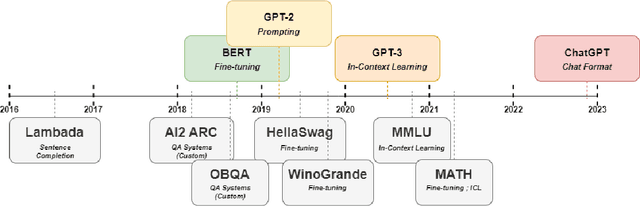
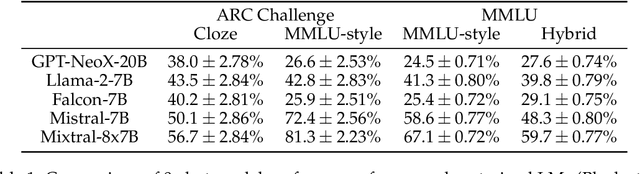
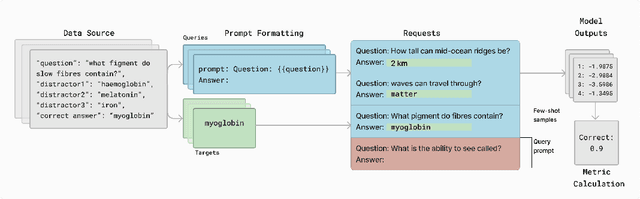

Effective evaluation of language models remains an open challenge in NLP. Researchers and engineers face methodological issues such as the sensitivity of models to evaluation setup, difficulty of proper comparisons across methods, and the lack of reproducibility and transparency. In this paper we draw on three years of experience in evaluating large language models to provide guidance and lessons for researchers. First, we provide an overview of common challenges faced in language model evaluation. Second, we delineate best practices for addressing or lessening the impact of these challenges on research. Third, we present the Language Model Evaluation Harness (lm-eval): an open source library for independent, reproducible, and extensible evaluation of language models that seeks to address these issues. We describe the features of the library as well as case studies in which the library has been used to alleviate these methodological concerns.
Aurora-M: The First Open Source Multilingual Language Model Red-teamed according to the U.S. Executive Order
Mar 30, 2024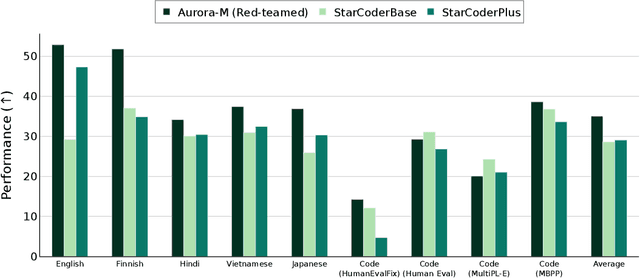

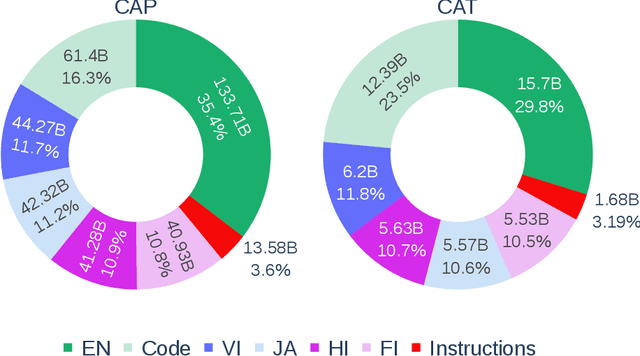
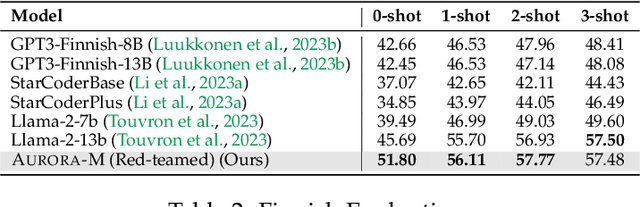
Pretrained language models underpin several AI applications, but their high computational cost for training limits accessibility. Initiatives such as BLOOM and StarCoder aim to democratize access to pretrained models for collaborative community development. However, such existing models face challenges: limited multilingual capabilities, continual pretraining causing catastrophic forgetting, whereas pretraining from scratch is computationally expensive, and compliance with AI safety and development laws. This paper presents Aurora-M, a 15B parameter multilingual open-source model trained on English, Finnish, Hindi, Japanese, Vietnamese, and code. Continually pretrained from StarCoderPlus on 435 billion additional tokens, Aurora-M surpasses 2 trillion tokens in total training token count. It is the first open-source multilingual model fine-tuned on human-reviewed safety instructions, thus aligning its development not only with conventional red-teaming considerations, but also with the specific concerns articulated in the Biden-Harris Executive Order on the Safe, Secure, and Trustworthy Development and Use of Artificial Intelligence. Aurora-M is rigorously evaluated across various tasks and languages, demonstrating robustness against catastrophic forgetting and outperforming alternatives in multilingual settings, particularly in safety evaluations. To promote responsible open-source LLM development, Aurora-M and its variants are released at https://huggingface.co/collections/aurora-m/aurora-m-models-65fdfdff62471e09812f5407 .
BLOOM: A 176B-Parameter Open-Access Multilingual Language Model
Nov 09, 2022Large language models (LLMs) have been shown to be able to perform new tasks based on a few demonstrations or natural language instructions. While these capabilities have led to widespread adoption, most LLMs are developed by resource-rich organizations and are frequently kept from the public. As a step towards democratizing this powerful technology, we present BLOOM, a 176B-parameter open-access language model designed and built thanks to a collaboration of hundreds of researchers. BLOOM is a decoder-only Transformer language model that was trained on the ROOTS corpus, a dataset comprising hundreds of sources in 46 natural and 13 programming languages (59 in total). We find that BLOOM achieves competitive performance on a wide variety of benchmarks, with stronger results after undergoing multitask prompted finetuning. To facilitate future research and applications using LLMs, we publicly release our models and code under the Responsible AI License.
GEMv2: Multilingual NLG Benchmarking in a Single Line of Code
Jun 24, 2022



Evaluation in machine learning is usually informed by past choices, for example which datasets or metrics to use. This standardization enables the comparison on equal footing using leaderboards, but the evaluation choices become sub-optimal as better alternatives arise. This problem is especially pertinent in natural language generation which requires ever-improving suites of datasets, metrics, and human evaluation to make definitive claims. To make following best model evaluation practices easier, we introduce GEMv2. The new version of the Generation, Evaluation, and Metrics Benchmark introduces a modular infrastructure for dataset, model, and metric developers to benefit from each others work. GEMv2 supports 40 documented datasets in 51 languages. Models for all datasets can be evaluated online and our interactive data card creation and rendering tools make it easier to add new datasets to the living benchmark.
Control Prefixes for Text Generation
Oct 15, 2021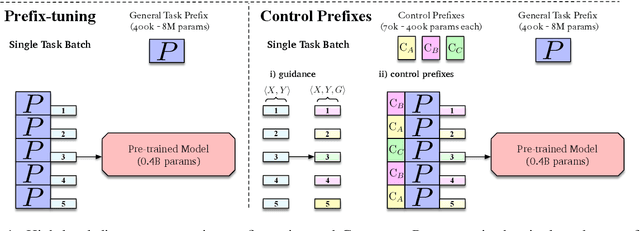

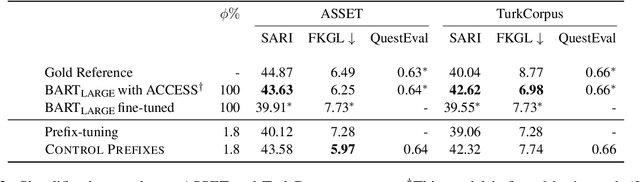
Prompt learning methods adapt pre-trained language models to downstream applications by using a task-specific prompt together with the input. Most of the current work on prompt learning in text generation relies on a shared dataset-level prompt for all examples in the dataset. We extend this approach and propose a dynamic method, Control Prefixes, which allows for the inclusion of conditional input-dependent information in each prompt. Control Prefixes is at the intersection of prompt learning and controlled generation, empowering the model to have finer-grained control during text generation. The method incorporates attribute-level learnable representations into different layers of a pre-trained transformer, allowing for the generated text to be guided in a particular direction. We provide a systematic evaluation of the technique and apply it to five datasets from the GEM benchmark for natural language generation (NLG). We present state-of-the-art results on several data-to-text datasets, including WebNLG.