 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArabic Stable LM: Adapting Stable LM 2 1.6B to Arabic
Dec 05, 2024Large Language Models (LLMs) have shown impressive results in multiple domains of natural language processing (NLP) but are mainly focused on the English language. Recently, more LLMs have incorporated a larger proportion of multilingual text to represent low-resource languages. In Arabic NLP, several Arabic-centric LLMs have shown remarkable results on multiple benchmarks in the past two years. However, most Arabic LLMs have more than 7 billion parameters, which increases their hardware requirements and inference latency, when compared to smaller LLMs. This paper introduces Arabic Stable LM 1.6B in a base and chat version as a small but powerful Arabic-centric LLM. Our Arabic Stable LM 1.6B chat model achieves impressive results on several benchmarks beating multiple models with up to 8x the parameters. In addition, we show the benefit of mixing in synthetic instruction tuning data by augmenting our fine-tuning data with a large synthetic dialogue dataset.
Rephrasing natural text data with different languages and quality levels for Large Language Model pre-training
Oct 28, 2024



Recently published work on rephrasing natural text data for pre-training LLMs has shown promising results when combining the original dataset with the synthetically rephrased data. We build upon previous work by replicating existing results on C4 and extending them with our optimized rephrasing pipeline to the English, German, Italian, and Spanish Oscar subsets of CulturaX. Our pipeline leads to increased performance on standard evaluation benchmarks in both the mono- and multilingual setup. In addition, we provide a detailed study of our pipeline, investigating the choice of the base dataset and LLM for the rephrasing, as well as the relationship between the model size and the performance after pre-training. By exploring data with different perceived quality levels, we show that gains decrease with higher quality. Furthermore, we find the difference in performance between model families to be bigger than between different model sizes. This highlights the necessity for detailed tests before choosing an LLM to rephrase large amounts of data. Moreover, we investigate the effect of pre-training with synthetic data on supervised fine-tuning. Here, we find increasing but inconclusive results that highly depend on the used benchmark. These results (again) highlight the need for better benchmarking setups. In summary, we show that rephrasing multilingual and low-quality data is a very promising direction to extend LLM pre-training data.
Lessons from the Trenches on Reproducible Evaluation of Language Models
May 23, 2024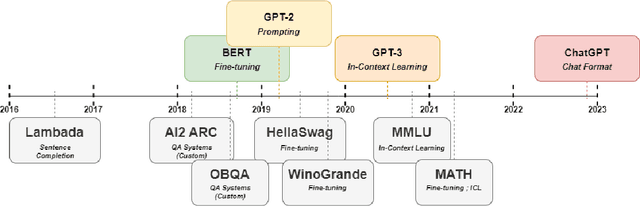
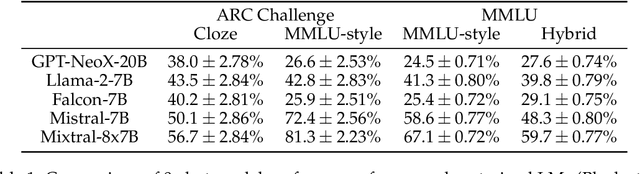
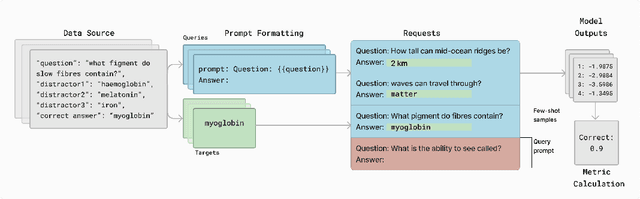

Effective evaluation of language models remains an open challenge in NLP. Researchers and engineers face methodological issues such as the sensitivity of models to evaluation setup, difficulty of proper comparisons across methods, and the lack of reproducibility and transparency. In this paper we draw on three years of experience in evaluating large language models to provide guidance and lessons for researchers. First, we provide an overview of common challenges faced in language model evaluation. Second, we delineate best practices for addressing or lessening the impact of these challenges on research. Third, we present the Language Model Evaluation Harness (lm-eval): an open source library for independent, reproducible, and extensible evaluation of language models that seeks to address these issues. We describe the features of the library as well as case studies in which the library has been used to alleviate these methodological concerns.
Stable Code Technical Report
Apr 01, 2024



We introduce Stable Code, the first in our new-generation of code language models series, which serves as a general-purpose base code language model targeting code completion, reasoning, math, and other software engineering-based tasks. Additionally, we introduce an instruction variant named Stable Code Instruct that allows conversing with the model in a natural chat interface for performing question-answering and instruction-based tasks. In this technical report, we detail the data and training procedure leading to both models. Their weights are available via Hugging Face for anyone to download and use at https://huggingface.co/stabilityai/stable-code-3b and https://huggingface.co/stabilityai/stable-code-instruct-3b. This report contains thorough evaluations of the models, including multilingual programming benchmarks, and the MT benchmark focusing on multi-turn dialogues. At the time of its release, Stable Code is the state-of-the-art open model under 3B parameters and even performs comparably to larger models of sizes 7 billion and 15 billion parameters on the popular Multi-PL benchmark. Stable Code Instruct also exhibits state-of-the-art performance on the MT-Bench coding tasks and on Multi-PL completion compared to other instruction tuned models. Given its appealing small size, we also provide throughput measurements on a number of edge devices. In addition, we open source several quantized checkpoints and provide their performance metrics compared to the original model.
Stable LM 2 1.6B Technical Report
Feb 27, 2024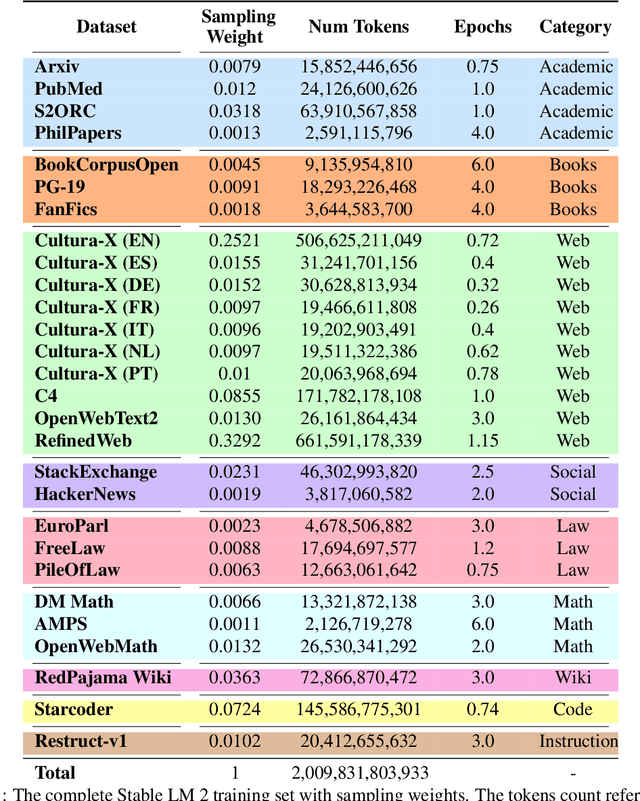
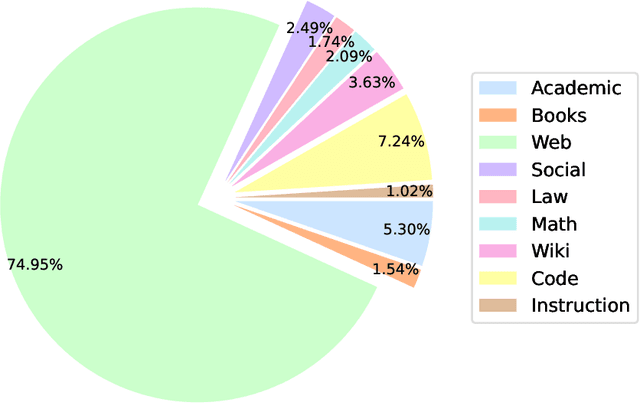
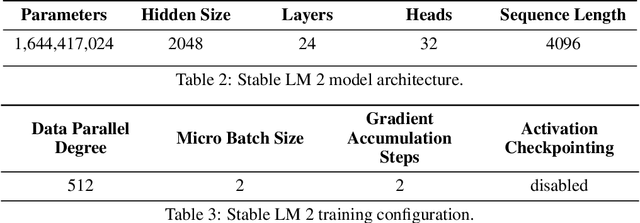
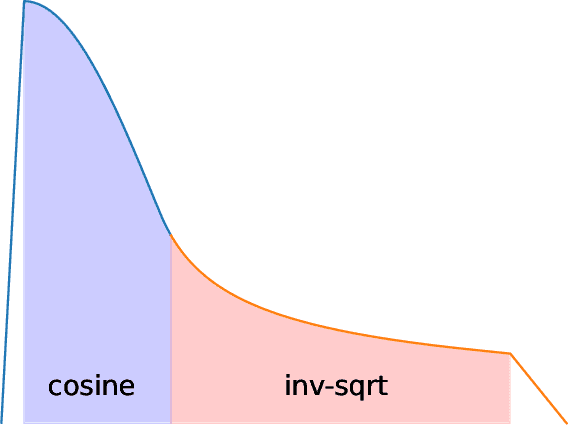
We introduce StableLM 2 1.6B, the first in a new generation of our language model series. In this technical report, we present in detail the data and training procedure leading to the base and instruction-tuned versions of StableLM 2 1.6B. The weights for both models are available via Hugging Face for anyone to download and use. The report contains thorough evaluations of these models, including zero- and few-shot benchmarks, multilingual benchmarks, and the MT benchmark focusing on multi-turn dialogues. At the time of publishing this report, StableLM 2 1.6B was the state-of-the-art open model under 2B parameters by a significant margin. Given its appealing small size, we also provide throughput measurements on a number of edge devices. In addition, we open source several quantized checkpoints and provide their performance metrics compared to the original model.
BLOOM: A 176B-Parameter Open-Access Multilingual Language Model
Nov 09, 2022Large language models (LLMs) have been shown to be able to perform new tasks based on a few demonstrations or natural language instructions. While these capabilities have led to widespread adoption, most LLMs are developed by resource-rich organizations and are frequently kept from the public. As a step towards democratizing this powerful technology, we present BLOOM, a 176B-parameter open-access language model designed and built thanks to a collaboration of hundreds of researchers. BLOOM is a decoder-only Transformer language model that was trained on the ROOTS corpus, a dataset comprising hundreds of sources in 46 natural and 13 programming languages (59 in total). We find that BLOOM achieves competitive performance on a wide variety of benchmarks, with stronger results after undergoing multitask prompted finetuning. To facilitate future research and applications using LLMs, we publicly release our models and code under the Responsible AI License.
GPT-NeoX-20B: An Open-Source Autoregressive Language Model
Apr 14, 2022
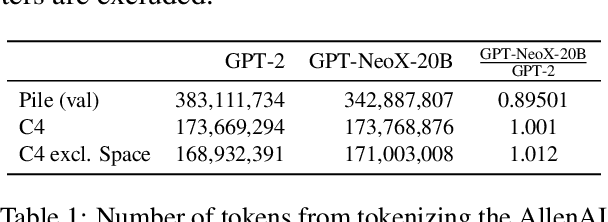
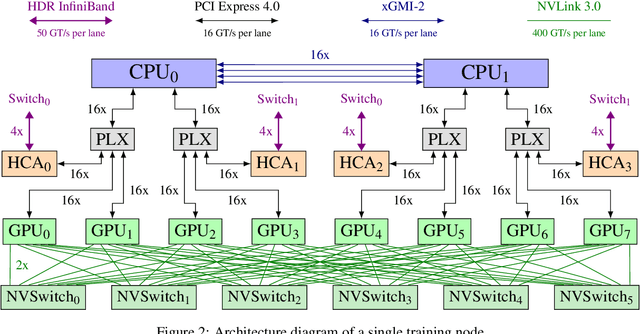

We introduce GPT-NeoX-20B, a 20 billion parameter autoregressive language model trained on the Pile, whose weights will be made freely and openly available to the public through a permissive license. It is, to the best of our knowledge, the largest dense autoregressive model that has publicly available weights at the time of submission. In this work, we describe \model{}'s architecture and training and evaluate its performance on a range of language-understanding, mathematics, and knowledge-based tasks. We find that GPT-NeoX-20B is a particularly powerful few-shot reasoner and gains far more in performance when evaluated five-shot than similarly sized GPT-3 and FairSeq models. We open-source the training and evaluation code, as well as the model weights, at https://github.com/EleutherAI/gpt-neox.