 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantifying the Effect of Test Set Contamination on Generative Evaluations
Jan 07, 2026As frontier AI systems are pretrained on web-scale data, test set contamination has become a critical concern for accurately assessing their capabilities. While research has thoroughly investigated the impact of test set contamination on discriminative evaluations like multiple-choice question-answering, comparatively little research has studied the impact of test set contamination on generative evaluations. In this work, we quantitatively assess the effect of test set contamination on generative evaluations through the language model lifecycle. We pretrain language models on mixtures of web data and the MATH benchmark, sweeping model sizes and number of test set replicas contaminating the pretraining corpus; performance improves with contamination and model size. Using scaling laws, we make a surprising discovery: including even a single test set replica enables models to achieve lower loss than the irreducible error of training on the uncontaminated corpus. We then study further training: overtraining with fresh data reduces the effects of contamination, whereas supervised finetuning on the training set can either increase or decrease performance on test data, depending on the amount of pretraining contamination. Finally, at inference, we identify factors that modulate memorization: high sampling temperatures mitigate contamination effects, and longer solutions are exponentially more difficult to memorize than shorter ones, presenting a contrast with discriminative evaluations, where solutions are only a few tokens in length. By characterizing how generation and memorization interact, we highlight a new layer of complexity for trustworthy evaluation of AI systems.
The Common Pile v0.1: An 8TB Dataset of Public Domain and Openly Licensed Text
Jun 05, 2025Large language models (LLMs) are typically trained on enormous quantities of unlicensed text, a practice that has led to scrutiny due to possible intellectual property infringement and ethical concerns. Training LLMs on openly licensed text presents a first step towards addressing these issues, but prior data collection efforts have yielded datasets too small or low-quality to produce performant LLMs. To address this gap, we collect, curate, and release the Common Pile v0.1, an eight terabyte collection of openly licensed text designed for LLM pretraining. The Common Pile comprises content from 30 sources that span diverse domains including research papers, code, books, encyclopedias, educational materials, audio transcripts, and more. Crucially, we validate our efforts by training two 7 billion parameter LLMs on text from the Common Pile: Comma v0.1-1T and Comma v0.1-2T, trained on 1 and 2 trillion tokens respectively. Both models attain competitive performance to LLMs trained on unlicensed text with similar computational budgets, such as Llama 1 and 2 7B. In addition to releasing the Common Pile v0.1 itself, we also release the code used in its creation as well as the training mixture and checkpoints for the Comma v0.1 models.
Surveying the Effects of Quality, Diversity, and Complexity in Synthetic Data From Large Language Models
Dec 04, 2024



Synthetic data generation with Large Language Models is a promising paradigm for augmenting natural data over a nearly infinite range of tasks. Given this variety, direct comparisons among synthetic data generation algorithms are scarce, making it difficult to understand where improvement comes from and what bottlenecks exist. We propose to evaluate algorithms via the makeup of synthetic data generated by each algorithm in terms of data quality, diversity, and complexity. We choose these three characteristics for their significance in open-ended processes and the impact each has on the capabilities of downstream models. We find quality to be essential for in-distribution model generalization, diversity to be essential for out-of-distribution generalization, and complexity to be beneficial for both. Further, we emphasize the existence of Quality-Diversity trade-offs in training data and the downstream effects on model performance. We then examine the effect of various components in the synthetic data pipeline on each data characteristic. This examination allows us to taxonomize and compare synthetic data generation algorithms through the components they utilize and the resulting effects on data QDC composition. This analysis extends into a discussion on the importance of balancing QDC in synthetic data for efficient reinforcement learning and self-improvement algorithms. Analogous to the QD trade-offs in training data, often there exist trade-offs between model output quality and output diversity which impact the composition of synthetic data. We observe that many models are currently evaluated and optimized only for output quality, thereby limiting output diversity and the potential for self-improvement. We argue that balancing these trade-offs is essential to the development of future self-improvement algorithms and highlight a number of works making progress in this direction.
Lessons from the Trenches on Reproducible Evaluation of Language Models
May 23, 2024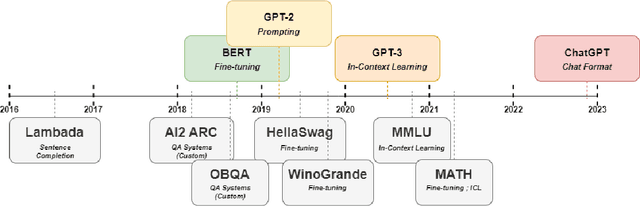
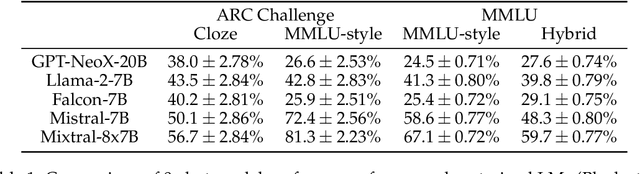
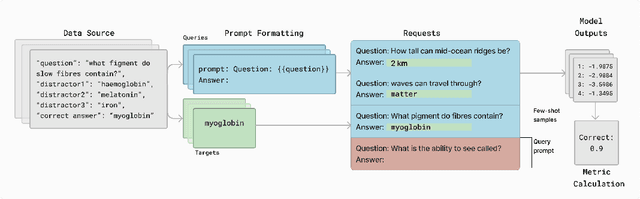

Effective evaluation of language models remains an open challenge in NLP. Researchers and engineers face methodological issues such as the sensitivity of models to evaluation setup, difficulty of proper comparisons across methods, and the lack of reproducibility and transparency. In this paper we draw on three years of experience in evaluating large language models to provide guidance and lessons for researchers. First, we provide an overview of common challenges faced in language model evaluation. Second, we delineate best practices for addressing or lessening the impact of these challenges on research. Third, we present the Language Model Evaluation Harness (lm-eval): an open source library for independent, reproducible, and extensible evaluation of language models that seeks to address these issues. We describe the features of the library as well as case studies in which the library has been used to alleviate these methodological concerns.