 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpreting Neural Networks through the Polytope Lens
Nov 22, 2022Mechanistic interpretability aims to explain what a neural network has learned at a nuts-and-bolts level. What are the fundamental primitives of neural network representations? Previous mechanistic descriptions have used individual neurons or their linear combinations to understand the representations a network has learned. But there are clues that neurons and their linear combinations are not the correct fundamental units of description: directions cannot describe how neural networks use nonlinearities to structure their representations. Moreover, many instances of individual neurons and their combinations are polysemantic (i.e. they have multiple unrelated meanings). Polysemanticity makes interpreting the network in terms of neurons or directions challenging since we can no longer assign a specific feature to a neural unit. In order to find a basic unit of description that does not suffer from these problems, we zoom in beyond just directions to study the way that piecewise linear activation functions (such as ReLU) partition the activation space into numerous discrete polytopes. We call this perspective the polytope lens. The polytope lens makes concrete predictions about the behavior of neural networks, which we evaluate through experiments on both convolutional image classifiers and language models. Specifically, we show that polytopes can be used to identify monosemantic regions of activation space (while directions are not in general monosemantic) and that the density of polytope boundaries reflect semantic boundaries. We also outline a vision for what mechanistic interpretability might look like through the polytope lens.
GPT-NeoX-20B: An Open-Source Autoregressive Language Model
Apr 14, 2022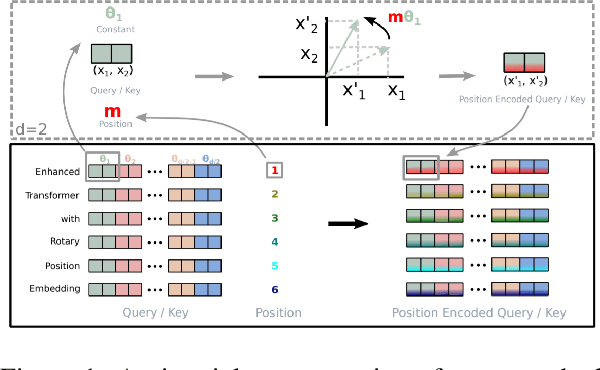
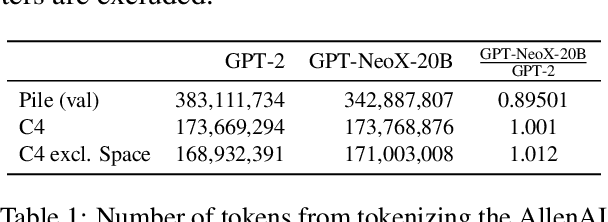
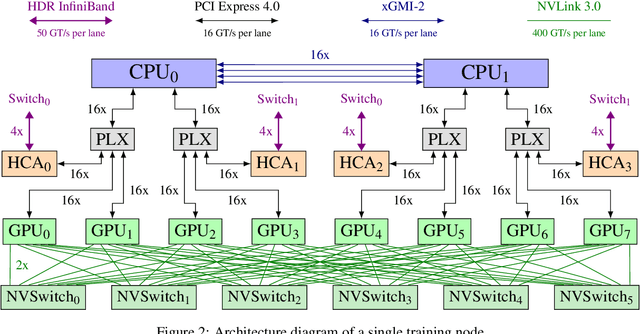

We introduce GPT-NeoX-20B, a 20 billion parameter autoregressive language model trained on the Pile, whose weights will be made freely and openly available to the public through a permissive license. It is, to the best of our knowledge, the largest dense autoregressive model that has publicly available weights at the time of submission. In this work, we describe \model{}'s architecture and training and evaluate its performance on a range of language-understanding, mathematics, and knowledge-based tasks. We find that GPT-NeoX-20B is a particularly powerful few-shot reasoner and gains far more in performance when evaluated five-shot than similarly sized GPT-3 and FairSeq models. We open-source the training and evaluation code, as well as the model weights, at https://github.com/EleutherAI/gpt-neox.
The Pile: An 800GB Dataset of Diverse Text for Language Modeling
Dec 31, 2020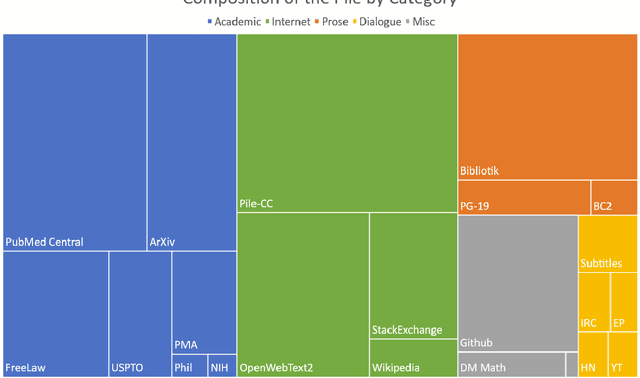
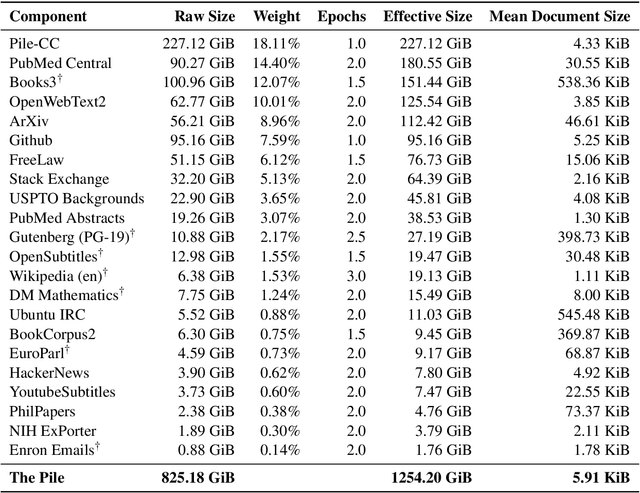
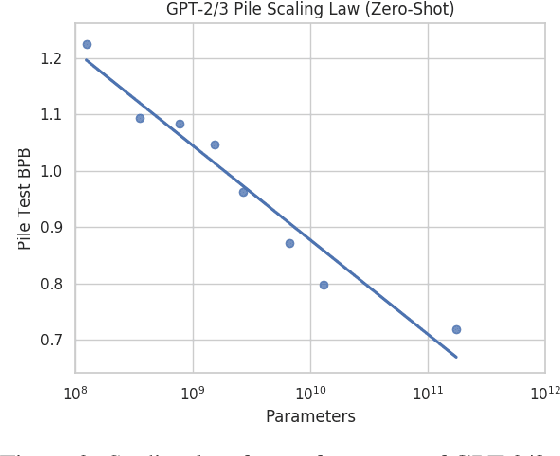
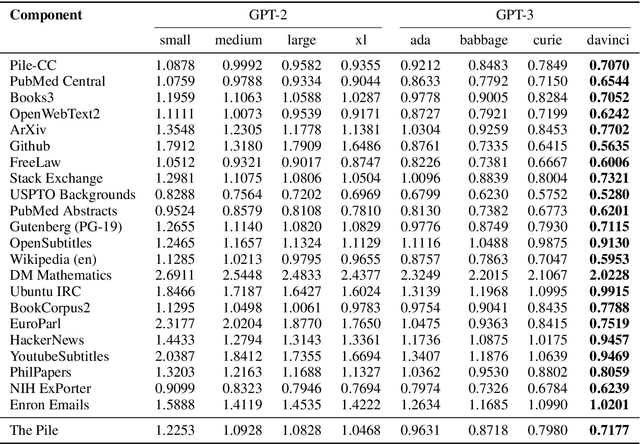
Recent work has demonstrated that increased training dataset diversity improves general cross-domain knowledge and downstream generalization capability for large-scale language models. With this in mind, we present \textit{the Pile}: an 825 GiB English text corpus targeted at training large-scale language models. The Pile is constructed from 22 diverse high-quality subsets -- both existing and newly constructed -- many of which derive from academic or professional sources. Our evaluation of the untuned performance of GPT-2 and GPT-3 on the Pile shows that these models struggle on many of its components, such as academic writing. Conversely, models trained on the Pile improve significantly over both Raw CC and CC-100 on all components of the Pile, while improving performance on downstream evaluations. Through an in-depth exploratory analysis, we document potentially concerning aspects of the data for prospective users. We make publicly available the code used in its construction.