 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolysemantic Experts, Monosemantic Paths: Routing as Control in MoEs
Apr 20, 2026An LLM's residual stream is both state and instruction: it encodes the current context and determines the next transformation. We introduce a parameter-free decomposition for Mixture-of-Experts models that splits each layer's hidden state into a control signal that causally drives routing and an orthogonal content channel invisible to the router. Across six MoE architectures, we find that models preserve surface-level features (language, token identity, position) in the content channel, while the control signal encodes an abstract function that rotates from layer to layer. Because each routing decision is low-bandwidth, this hand-off forces compositional specialization across layers. While individual experts remain polysemantic, expert paths become monosemantic, clustering tokens by semantic function across languages and surface forms. The same token (e.g., ":") follows distinct trajectories depending on whether it serves as a type annotation, an introductory colon, or a time separator. Our decomposition identifies the source of this structure: clusters in the control subspace are substantially more monosemantic than those in the full representation. As a result, the natural unit of interpretability in MoEs is not the expert but the trajectory.
Stochastic Parameter Decomposition
Jun 25, 2025



A key step in reverse engineering neural networks is to decompose them into simpler parts that can be studied in relative isolation. Linear parameter decomposition -- a framework that has been proposed to resolve several issues with current decomposition methods -- decomposes neural network parameters into a sum of sparsely used vectors in parameter space. However, the current main method in this framework, Attribution-based Parameter Decomposition (APD), is impractical on account of its computational cost and sensitivity to hyperparameters. In this work, we introduce \textit{Stochastic Parameter Decomposition} (SPD), a method that is more scalable and robust to hyperparameters than APD, which we demonstrate by decomposing models that are slightly larger and more complex than was possible to decompose with APD. We also show that SPD avoids other issues, such as shrinkage of the learned parameters, and better identifies ground truth mechanisms in toy models. By bridging causal mediation analysis and network decomposition methods, this demonstration opens up new research possibilities in mechanistic interpretability by removing barriers to scaling linear parameter decomposition methods to larger models. We release a library for running SPD and reproducing our experiments at https://github.com/goodfire-ai/spd.
Prisma: An Open Source Toolkit for Mechanistic Interpretability in Vision and Video
Apr 28, 2025Robust tooling and publicly available pre-trained models have helped drive recent advances in mechanistic interpretability for language models. However, similar progress in vision mechanistic interpretability has been hindered by the lack of accessible frameworks and pre-trained weights. We present Prisma (Access the codebase here: https://github.com/Prisma-Multimodal/ViT-Prisma), an open-source framework designed to accelerate vision mechanistic interpretability research, providing a unified toolkit for accessing 75+ vision and video transformers; support for sparse autoencoder (SAE), transcoder, and crosscoder training; a suite of 80+ pre-trained SAE weights; activation caching, circuit analysis tools, and visualization tools; and educational resources. Our analysis reveals surprising findings, including that effective vision SAEs can exhibit substantially lower sparsity patterns than language SAEs, and that in some instances, SAE reconstructions can decrease model loss. Prisma enables new research directions for understanding vision model internals while lowering barriers to entry in this emerging field.
Identifying Sparsely Active Circuits Through Local Loss Landscape Decomposition
Mar 31, 2025
Much of mechanistic interpretability has focused on understanding the activation spaces of large neural networks. However, activation space-based approaches reveal little about the underlying circuitry used to compute features. To better understand the circuits employed by models, we introduce a new decomposition method called Local Loss Landscape Decomposition (L3D). L3D identifies a set of low-rank subnetworks: directions in parameter space of which a subset can reconstruct the gradient of the loss between any sample's output and a reference output vector. We design a series of progressively more challenging toy models with well-defined subnetworks and show that L3D can nearly perfectly recover the associated subnetworks. Additionally, we investigate the extent to which perturbing the model in the direction of a given subnetwork affects only the relevant subset of samples. Finally, we apply L3D to a real-world transformer model and a convolutional neural network, demonstrating its potential to identify interpretable and relevant circuits in parameter space.
Sparse Autoencoders Do Not Find Canonical Units of Analysis
Feb 07, 2025



A common goal of mechanistic interpretability is to decompose the activations of neural networks into features: interpretable properties of the input computed by the model. Sparse autoencoders (SAEs) are a popular method for finding these features in LLMs, and it has been postulated that they can be used to find a \textit{canonical} set of units: a unique and complete list of atomic features. We cast doubt on this belief using two novel techniques: SAE stitching to show they are incomplete, and meta-SAEs to show they are not atomic. SAE stitching involves inserting or swapping latents from a larger SAE into a smaller one. Latents from the larger SAE can be divided into two categories: \emph{novel latents}, which improve performance when added to the smaller SAE, indicating they capture novel information, and \emph{reconstruction latents}, which can replace corresponding latents in the smaller SAE that have similar behavior. The existence of novel features indicates incompleteness of smaller SAEs. Using meta-SAEs -- SAEs trained on the decoder matrix of another SAE -- we find that latents in SAEs often decompose into combinations of latents from a smaller SAE, showing that larger SAE latents are not atomic. The resulting decompositions are often interpretable; e.g. a latent representing ``Einstein'' decomposes into ``scientist'', ``Germany'', and ``famous person''. Even if SAEs do not find canonical units of analysis, they may still be useful tools. We suggest that future research should either pursue different approaches for identifying such units, or pragmatically choose the SAE size suited to their task. We provide an interactive dashboard to explore meta-SAEs: https://metasaes.streamlit.app/
Open Problems in Mechanistic Interpretability
Jan 27, 2025



Mechanistic interpretability aims to understand the computational mechanisms underlying neural networks' capabilities in order to accomplish concrete scientific and engineering goals. Progress in this field thus promises to provide greater assurance over AI system behavior and shed light on exciting scientific questions about the nature of intelligence. Despite recent progress toward these goals, there are many open problems in the field that require solutions before many scientific and practical benefits can be realized: Our methods require both conceptual and practical improvements to reveal deeper insights; we must figure out how best to apply our methods in pursuit of specific goals; and the field must grapple with socio-technical challenges that influence and are influenced by our work. This forward-facing review discusses the current frontier of mechanistic interpretability and the open problems that the field may benefit from prioritizing.
Interpretability in Parameter Space: Minimizing Mechanistic Description Length with Attribution-based Parameter Decomposition
Jan 24, 2025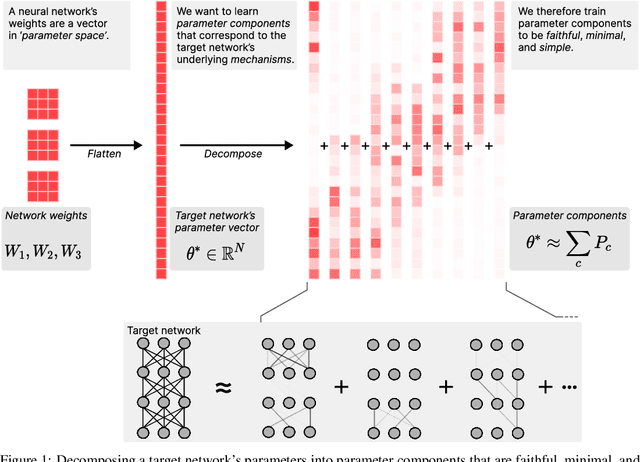
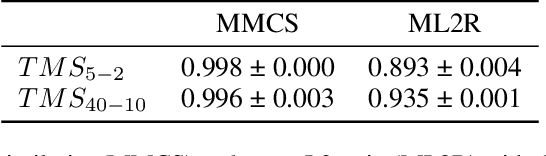
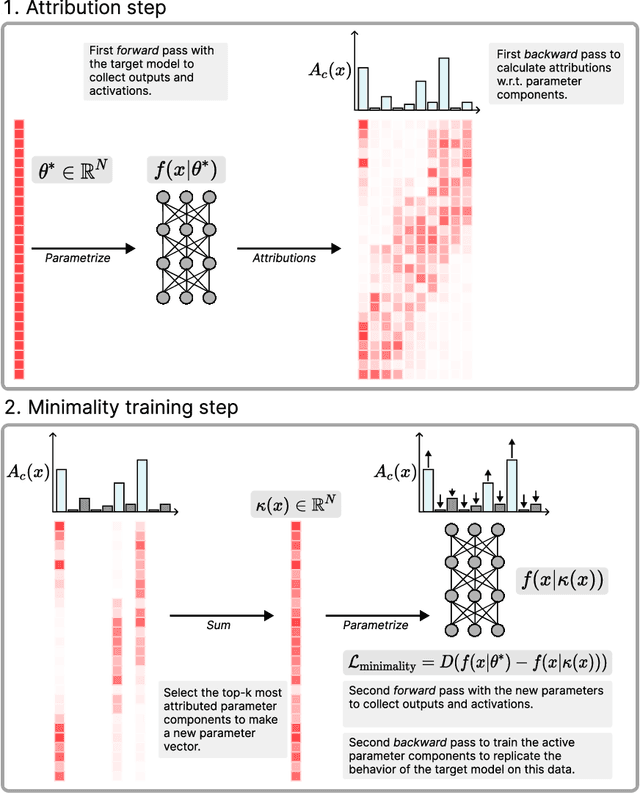
Mechanistic interpretability aims to understand the internal mechanisms learned by neural networks. Despite recent progress toward this goal, it remains unclear how best to decompose neural network parameters into mechanistic components. We introduce Attribution-based Parameter Decomposition (APD), a method that directly decomposes a neural network's parameters into components that (i) are faithful to the parameters of the original network, (ii) require a minimal number of components to process any input, and (iii) are maximally simple. Our approach thus optimizes for a minimal length description of the network's mechanisms. We demonstrate APD's effectiveness by successfully identifying ground truth mechanisms in multiple toy experimental settings: Recovering features from superposition; separating compressed computations; and identifying cross-layer distributed representations. While challenges remain to scaling APD to non-toy models, our results suggest solutions to several open problems in mechanistic interpretability, including identifying minimal circuits in superposition, offering a conceptual foundation for 'features', and providing an architecture-agnostic framework for neural network decomposition.
Interpretability as Compression: Reconsidering SAE Explanations of Neural Activations with MDL-SAEs
Oct 15, 2024



Sparse Autoencoders (SAEs) have emerged as a useful tool for interpreting the internal representations of neural networks. However, naively optimising SAEs for reconstruction loss and sparsity results in a preference for SAEs that are extremely wide and sparse. We present an information-theoretic framework for interpreting SAEs as lossy compression algorithms for communicating explanations of neural activations. We appeal to the Minimal Description Length (MDL) principle to motivate explanations of activations which are both accurate and concise. We further argue that interpretable SAEs require an additional property, "independent additivity": features should be able to be understood separately. We demonstrate an example of applying our MDL-inspired framework by training SAEs on MNIST handwritten digits and find that SAE features representing significant line segments are optimal, as opposed to SAEs with features for memorised digits from the dataset or small digit fragments. We argue that using MDL rather than sparsity may avoid potential pitfalls with naively maximising sparsity such as undesirable feature splitting and that this framework naturally suggests new hierarchical SAE architectures which provide more concise explanations.
Bilinear MLPs enable weight-based mechanistic interpretability
Oct 10, 2024A mechanistic understanding of how MLPs do computation in deep neural networks remains elusive. Current interpretability work can extract features from hidden activations over an input dataset but generally cannot explain how MLP weights construct features. One challenge is that element-wise nonlinearities introduce higher-order interactions and make it difficult to trace computations through the MLP layer. In this paper, we analyze bilinear MLPs, a type of Gated Linear Unit (GLU) without any element-wise nonlinearity that nevertheless achieves competitive performance. Bilinear MLPs can be fully expressed in terms of linear operations using a third-order tensor, allowing flexible analysis of the weights. Analyzing the spectra of bilinear MLP weights using eigendecomposition reveals interpretable low-rank structure across toy tasks, image classification, and language modeling. We use this understanding to craft adversarial examples, uncover overfitting, and identify small language model circuits directly from the weights alone. Our results demonstrate that bilinear layers serve as an interpretable drop-in replacement for current activation functions and that weight-based interpretability is viable for understanding deep-learning models.
Identifying Functionally Important Features with End-to-End Sparse Dictionary Learning
May 17, 2024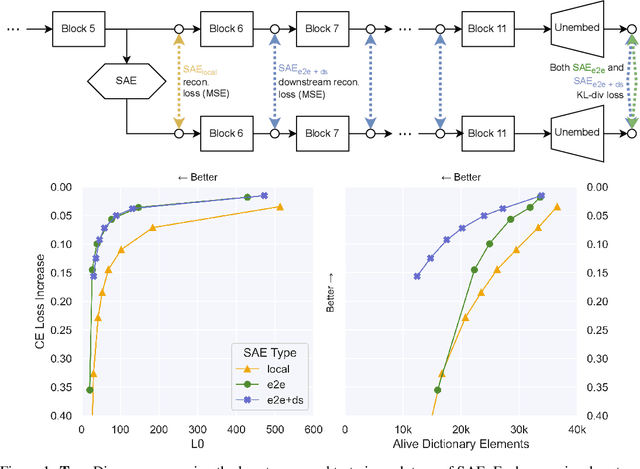

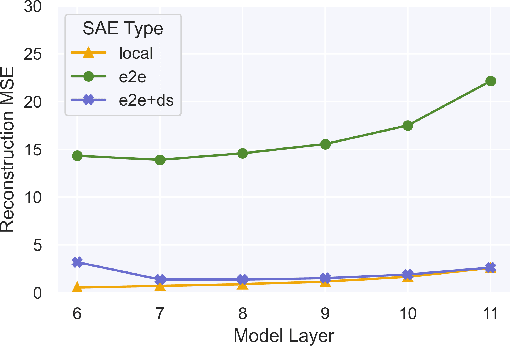
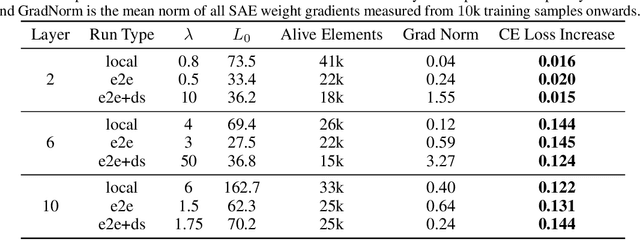
Identifying the features learned by neural networks is a core challenge in mechanistic interpretability. Sparse autoencoders (SAEs), which learn a sparse, overcomplete dictionary that reconstructs a network's internal activations, have been used to identify these features. However, SAEs may learn more about the structure of the datatset than the computational structure of the network. There is therefore only indirect reason to believe that the directions found in these dictionaries are functionally important to the network. We propose end-to-end (e2e) sparse dictionary learning, a method for training SAEs that ensures the features learned are functionally important by minimizing the KL divergence between the output distributions of the original model and the model with SAE activations inserted. Compared to standard SAEs, e2e SAEs offer a Pareto improvement: They explain more network performance, require fewer total features, and require fewer simultaneously active features per datapoint, all with no cost to interpretability. We explore geometric and qualitative differences between e2e SAE features and standard SAE features. E2e dictionary learning brings us closer to methods that can explain network behavior concisely and accurately. We release our library for training e2e SAEs and reproducing our analysis at https://github.com/ApolloResearch/e2e_sae