 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe TUB Sign Language Corpus Collection
Aug 07, 2025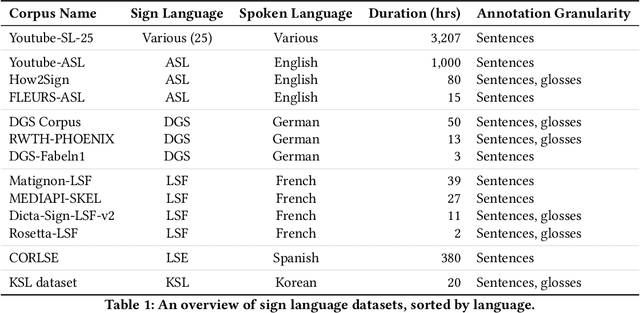
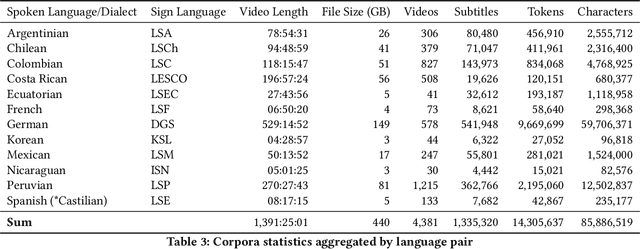
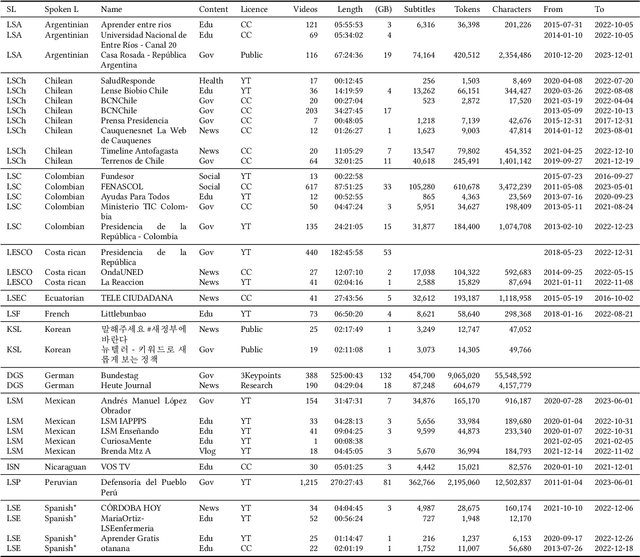
We present a collection of parallel corpora of 12 sign languages in video format, together with subtitles in the dominant spoken languages of the corresponding countries. The entire collection includes more than 1,300 hours in 4,381 video files, accompanied by 1,3~M subtitles containing 14~M tokens. Most notably, it includes the first consistent parallel corpora for 8 Latin American sign languages, whereas the size of the German Sign Language corpora is ten times the size of the previously available corpora. The collection was created by collecting and processing videos of multiple sign languages from various online sources, mainly broadcast material of news shows, governmental bodies and educational channels. The preparation involved several stages, including data collection, informing the content creators and seeking usage approvals, scraping, and cropping. The paper provides statistics on the collection and an overview of the methods used to collect the data.
From What to How: Attributing CLIP's Latent Components Reveals Unexpected Semantic Reliance
May 26, 2025



Transformer-based CLIP models are widely used for text-image probing and feature extraction, making it relevant to understand the internal mechanisms behind their predictions. While recent works show that Sparse Autoencoders (SAEs) yield interpretable latent components, they focus on what these encode and miss how they drive predictions. We introduce a scalable framework that reveals what latent components activate for, how they align with expected semantics, and how important they are to predictions. To achieve this, we adapt attribution patching for instance-wise component attributions in CLIP and highlight key faithfulness limitations of the widely used Logit Lens technique. By combining attributions with semantic alignment scores, we can automatically uncover reliance on components that encode semantically unexpected or spurious concepts. Applied across multiple CLIP variants, our method uncovers hundreds of surprising components linked to polysemous words, compound nouns, visual typography and dataset artifacts. While text embeddings remain prone to semantic ambiguity, they are more robust to spurious correlations compared to linear classifiers trained on image embeddings. A case study on skin lesion detection highlights how such classifiers can amplify hidden shortcuts, underscoring the need for holistic, mechanistic interpretability. We provide code at https://github.com/maxdreyer/attributing-clip.
Prisma: An Open Source Toolkit for Mechanistic Interpretability in Vision and Video
Apr 28, 2025Robust tooling and publicly available pre-trained models have helped drive recent advances in mechanistic interpretability for language models. However, similar progress in vision mechanistic interpretability has been hindered by the lack of accessible frameworks and pre-trained weights. We present Prisma (Access the codebase here: https://github.com/Prisma-Multimodal/ViT-Prisma), an open-source framework designed to accelerate vision mechanistic interpretability research, providing a unified toolkit for accessing 75+ vision and video transformers; support for sparse autoencoder (SAE), transcoder, and crosscoder training; a suite of 80+ pre-trained SAE weights; activation caching, circuit analysis tools, and visualization tools; and educational resources. Our analysis reveals surprising findings, including that effective vision SAEs can exhibit substantially lower sparsity patterns than language SAEs, and that in some instances, SAE reconstructions can decrease model loss. Prisma enables new research directions for understanding vision model internals while lowering barriers to entry in this emerging field.
Steering CLIP's vision transformer with sparse autoencoders
Apr 11, 2025



While vision models are highly capable, their internal mechanisms remain poorly understood -- a challenge which sparse autoencoders (SAEs) have helped address in language, but which remains underexplored in vision. We address this gap by training SAEs on CLIP's vision transformer and uncover key differences between vision and language processing, including distinct sparsity patterns for SAEs trained across layers and token types. We then provide the first systematic analysis on the steerability of CLIP's vision transformer by introducing metrics to quantify how precisely SAE features can be steered to affect the model's output. We find that 10-15\% of neurons and features are steerable, with SAEs providing thousands more steerable features than the base model. Through targeted suppression of SAE features, we then demonstrate improved performance on three vision disentanglement tasks (CelebA, Waterbirds, and typographic attacks), finding optimal disentanglement in middle model layers, and achieving state-of-the-art performance on defense against typographic attacks.
SCAM: A Real-World Typographic Robustness Evaluation for Multimodal Foundation Models
Apr 07, 2025Typographic attacks exploit the interplay between text and visual content in multimodal foundation models, causing misclassifications when misleading text is embedded within images. However, existing datasets are limited in size and diversity, making it difficult to study such vulnerabilities. In this paper, we introduce SCAM, the largest and most diverse dataset of real-world typographic attack images to date, containing 1,162 images across hundreds of object categories and attack words. Through extensive benchmarking of Vision-Language Models (VLMs) on SCAM, we demonstrate that typographic attacks significantly degrade performance, and identify that training data and model architecture influence the susceptibility to these attacks. Our findings reveal that typographic attacks persist in state-of-the-art Large Vision-Language Models (LVLMs) due to the choice of their vision encoder, though larger Large Language Models (LLMs) backbones help mitigate their vulnerability. Additionally, we demonstrate that synthetic attacks closely resemble real-world (handwritten) attacks, validating their use in research. Our work provides a comprehensive resource and empirical insights to facilitate future research toward robust and trustworthy multimodal AI systems. We publicly release the datasets introduced in this paper under https://huggingface.co/datasets/BLISS-e-V/SCAM, along with the code for evaluations at https://github.com/Bliss-e-V/SCAM.