 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLessons from the Trenches on Reproducible Evaluation of Language Models
May 23, 2024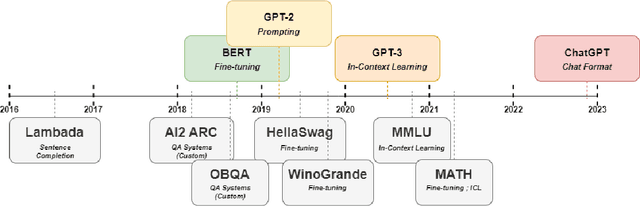
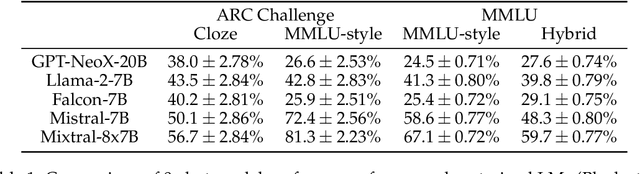
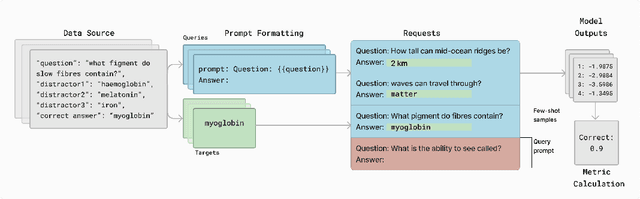

Effective evaluation of language models remains an open challenge in NLP. Researchers and engineers face methodological issues such as the sensitivity of models to evaluation setup, difficulty of proper comparisons across methods, and the lack of reproducibility and transparency. In this paper we draw on three years of experience in evaluating large language models to provide guidance and lessons for researchers. First, we provide an overview of common challenges faced in language model evaluation. Second, we delineate best practices for addressing or lessening the impact of these challenges on research. Third, we present the Language Model Evaluation Harness (lm-eval): an open source library for independent, reproducible, and extensible evaluation of language models that seeks to address these issues. We describe the features of the library as well as case studies in which the library has been used to alleviate these methodological concerns.
The Pile: An 800GB Dataset of Diverse Text for Language Modeling
Dec 31, 2020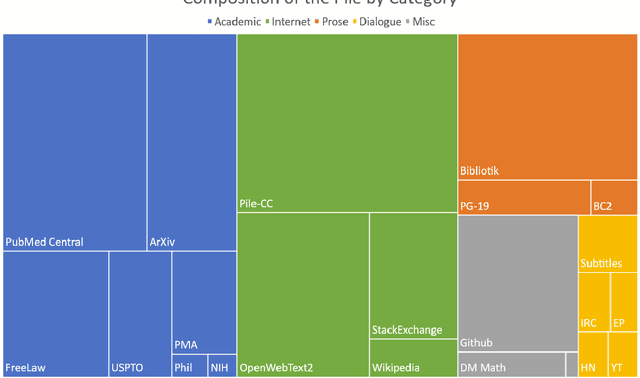
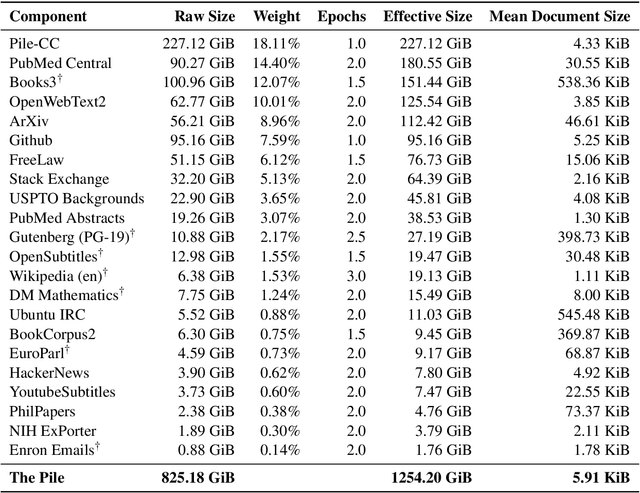
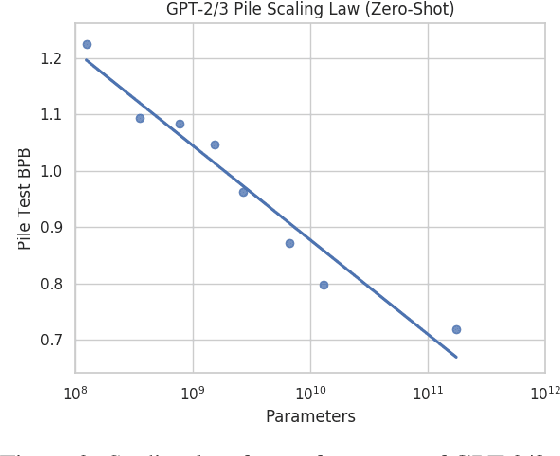
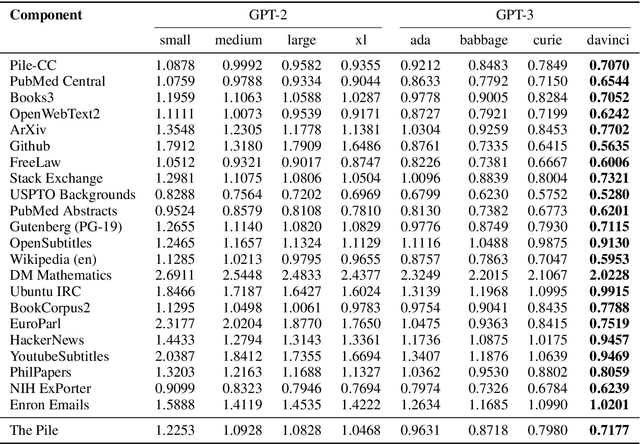
Recent work has demonstrated that increased training dataset diversity improves general cross-domain knowledge and downstream generalization capability for large-scale language models. With this in mind, we present \textit{the Pile}: an 825 GiB English text corpus targeted at training large-scale language models. The Pile is constructed from 22 diverse high-quality subsets -- both existing and newly constructed -- many of which derive from academic or professional sources. Our evaluation of the untuned performance of GPT-2 and GPT-3 on the Pile shows that these models struggle on many of its components, such as academic writing. Conversely, models trained on the Pile improve significantly over both Raw CC and CC-100 on all components of the Pile, while improving performance on downstream evaluations. Through an in-depth exploratory analysis, we document potentially concerning aspects of the data for prospective users. We make publicly available the code used in its construction.
Sampled Image Tagging and Retrieval Methods on User Generated Content
Dec 02, 2016



Traditional image tagging and retrieval algorithms have limited value as a result of being trained with heavily curated datasets. These limitations are most evident when arbitrary search words are used that do not intersect with training set labels. Weak labels from user generated content (UGC) found in the wild (e.g., Google Photos, FlickR, etc.) have an almost unlimited number of unique words in the metadata tags. Prior work on word embeddings successfully leveraged unstructured text with large vocabularies, and our proposed method seeks to apply similar cost functions to open source imagery. Specifically, we train a deep learning image tagging and retrieval system on large scale, user generated content (UGC) using sampling methods and joint optimization of word embeddings. By using the Yahoo! FlickR Creative Commons (YFCC100M) dataset, such an approach builds robustness to common unstructured data issues that include but are not limited to irrelevant tags, misspellings, multiple languages, polysemy, and tag imbalance. As a result, the final proposed algorithm will not only yield comparable results to state of the art in conventional image tagging, but will enable new capability to train algorithms on large, scale unstructured text in the YFCC100M dataset and outperform cited work in zero-shot capability.