 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArabic Stable LM: Adapting Stable LM 2 1.6B to Arabic
Dec 05, 2024Large Language Models (LLMs) have shown impressive results in multiple domains of natural language processing (NLP) but are mainly focused on the English language. Recently, more LLMs have incorporated a larger proportion of multilingual text to represent low-resource languages. In Arabic NLP, several Arabic-centric LLMs have shown remarkable results on multiple benchmarks in the past two years. However, most Arabic LLMs have more than 7 billion parameters, which increases their hardware requirements and inference latency, when compared to smaller LLMs. This paper introduces Arabic Stable LM 1.6B in a base and chat version as a small but powerful Arabic-centric LLM. Our Arabic Stable LM 1.6B chat model achieves impressive results on several benchmarks beating multiple models with up to 8x the parameters. In addition, we show the benefit of mixing in synthetic instruction tuning data by augmenting our fine-tuning data with a large synthetic dialogue dataset.
Rephrasing natural text data with different languages and quality levels for Large Language Model pre-training
Oct 28, 2024



Recently published work on rephrasing natural text data for pre-training LLMs has shown promising results when combining the original dataset with the synthetically rephrased data. We build upon previous work by replicating existing results on C4 and extending them with our optimized rephrasing pipeline to the English, German, Italian, and Spanish Oscar subsets of CulturaX. Our pipeline leads to increased performance on standard evaluation benchmarks in both the mono- and multilingual setup. In addition, we provide a detailed study of our pipeline, investigating the choice of the base dataset and LLM for the rephrasing, as well as the relationship between the model size and the performance after pre-training. By exploring data with different perceived quality levels, we show that gains decrease with higher quality. Furthermore, we find the difference in performance between model families to be bigger than between different model sizes. This highlights the necessity for detailed tests before choosing an LLM to rephrase large amounts of data. Moreover, we investigate the effect of pre-training with synthetic data on supervised fine-tuning. Here, we find increasing but inconclusive results that highly depend on the used benchmark. These results (again) highlight the need for better benchmarking setups. In summary, we show that rephrasing multilingual and low-quality data is a very promising direction to extend LLM pre-training data.
Stable LM 2 1.6B Technical Report
Feb 27, 2024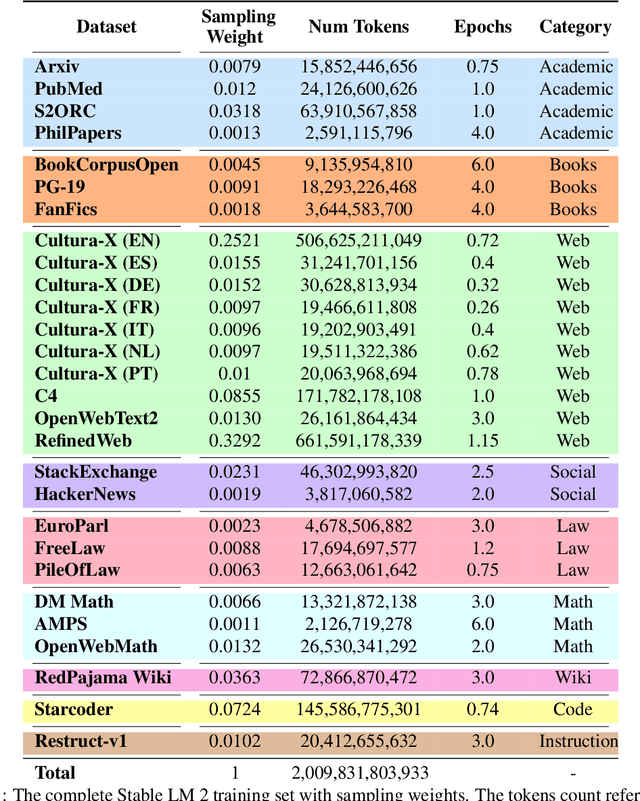
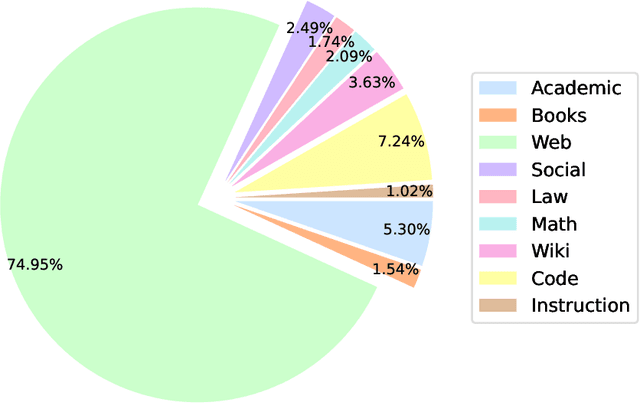
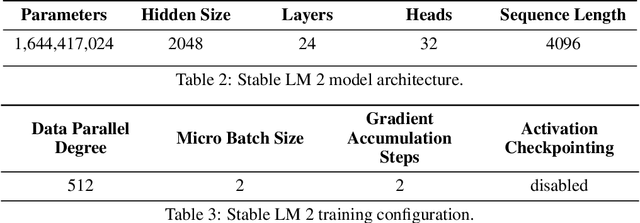
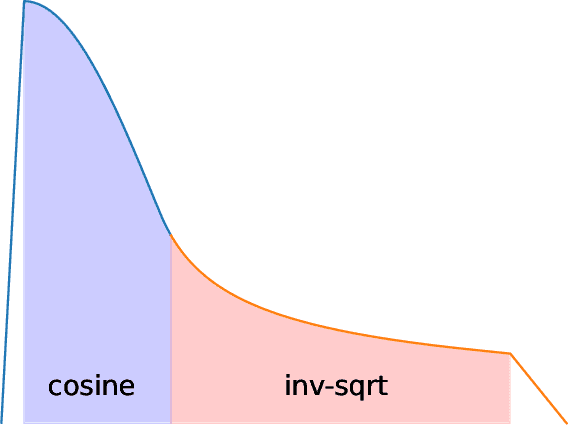
We introduce StableLM 2 1.6B, the first in a new generation of our language model series. In this technical report, we present in detail the data and training procedure leading to the base and instruction-tuned versions of StableLM 2 1.6B. The weights for both models are available via Hugging Face for anyone to download and use. The report contains thorough evaluations of these models, including zero- and few-shot benchmarks, multilingual benchmarks, and the MT benchmark focusing on multi-turn dialogues. At the time of publishing this report, StableLM 2 1.6B was the state-of-the-art open model under 2B parameters by a significant margin. Given its appealing small size, we also provide throughput measurements on a number of edge devices. In addition, we open source several quantized checkpoints and provide their performance metrics compared to the original model.
Towards Automatic Clustering Analysis using Traces of Information Gain: The InfoGuide Method
Jan 23, 2020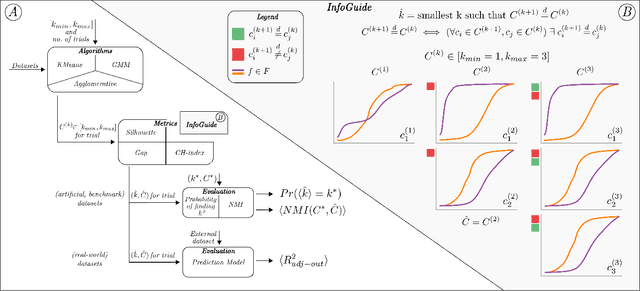
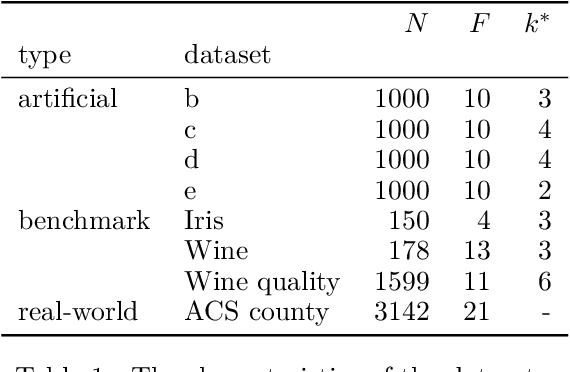
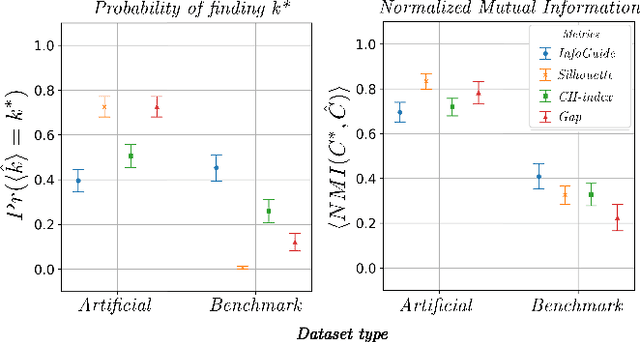
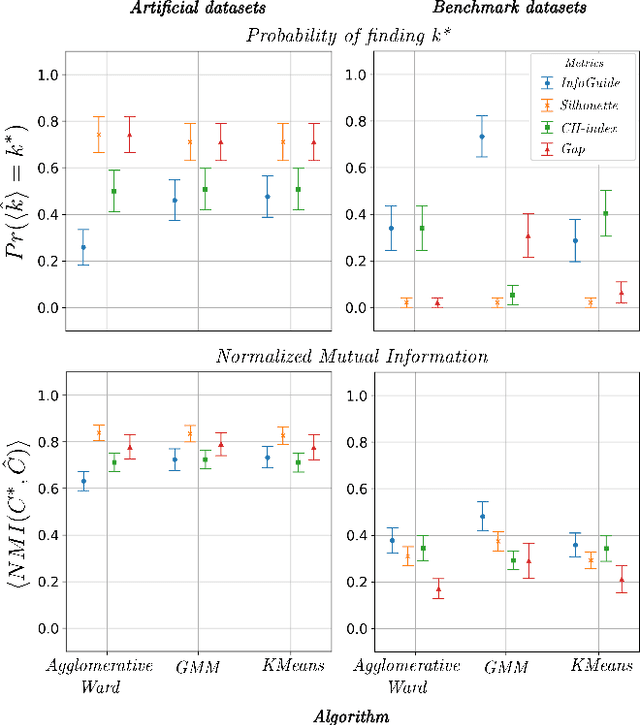
Clustering analysis has become a ubiquitous information retrieval tool in a wide range of domains, but a more automatic framework is still lacking. Though internal metrics are the key players towards a successful retrieval of clusters, their effectiveness on real-world datasets remains not fully understood, mainly because of their unrealistic assumptions underlying datasets. We hypothesized that capturing {\it traces of information gain} between increasingly complex clustering retrievals---{\it InfoGuide}---enables an automatic clustering analysis with improved clustering retrievals. We validated the {\it InfoGuide} hypothesis by capturing the traces of information gain using the Kolmogorov-Smirnov statistic and comparing the clusters retrieved by {\it InfoGuide} against those retrieved by other commonly used internal metrics in artificially-generated, benchmarks, and real-world datasets. Our results suggested that {\it InfoGuide} can enable a more automatic clustering analysis and may be more suitable for retrieving clusters in real-world datasets displaying nontrivial statistical properties.