 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Automatic Clustering Analysis using Traces of Information Gain: The InfoGuide Method
Jan 23, 2020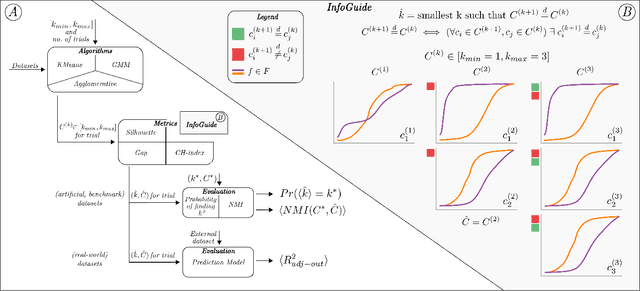
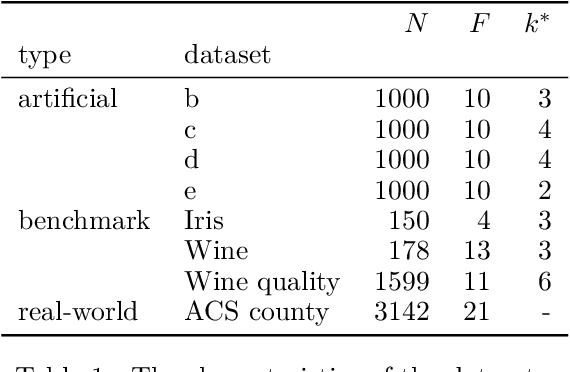
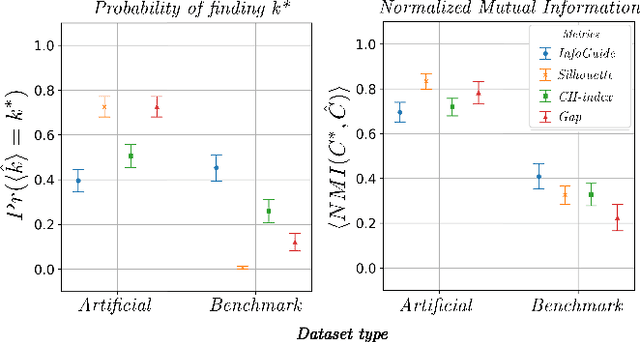
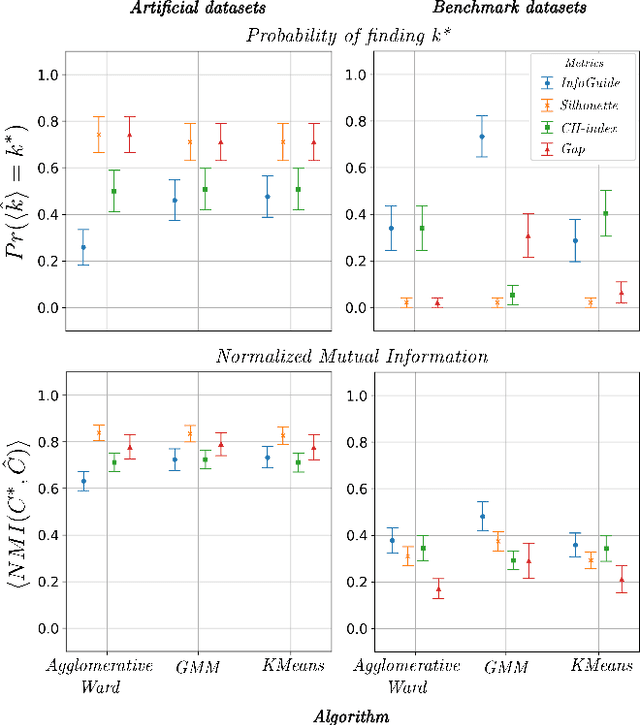
Clustering analysis has become a ubiquitous information retrieval tool in a wide range of domains, but a more automatic framework is still lacking. Though internal metrics are the key players towards a successful retrieval of clusters, their effectiveness on real-world datasets remains not fully understood, mainly because of their unrealistic assumptions underlying datasets. We hypothesized that capturing {\it traces of information gain} between increasingly complex clustering retrievals---{\it InfoGuide}---enables an automatic clustering analysis with improved clustering retrievals. We validated the {\it InfoGuide} hypothesis by capturing the traces of information gain using the Kolmogorov-Smirnov statistic and comparing the clusters retrieved by {\it InfoGuide} against those retrieved by other commonly used internal metrics in artificially-generated, benchmarks, and real-world datasets. Our results suggested that {\it InfoGuide} can enable a more automatic clustering analysis and may be more suitable for retrieving clusters in real-world datasets displaying nontrivial statistical properties.
Network-Based Delineation of Health Service Areas: A Comparative Analysis of Community Detection Algorithms
Dec 08, 2019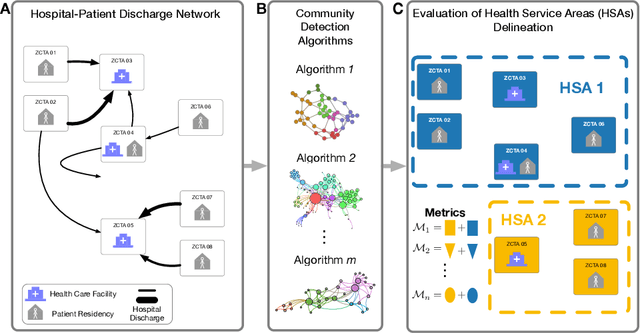

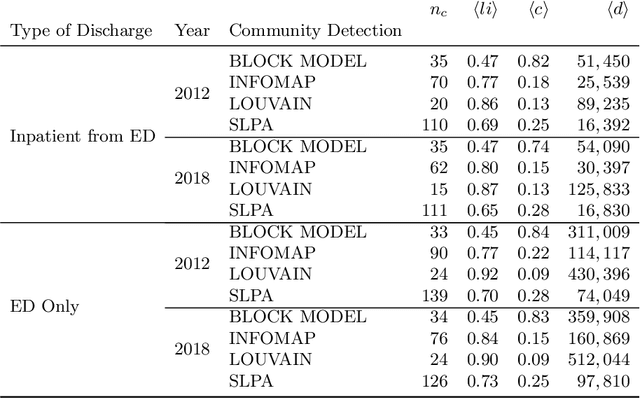
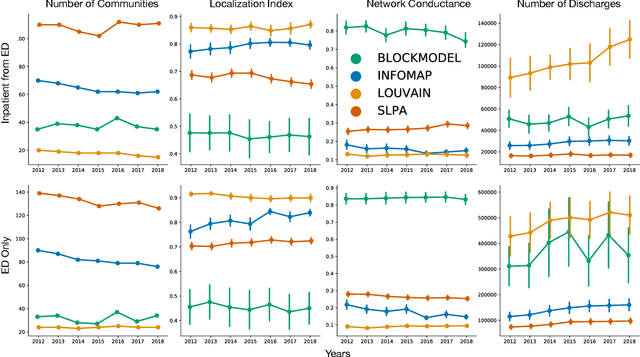
A Health Service Area (HSA) is a group of geographic regions served by similar health care facilities. The delineation of HSAs plays a pivotal role in the characterization of health care services available in an area, enabling a better planning and regulation of health care services. Though Dartmouth HSAs have been the standard delineation for decades, previous work has recently shown an improved HSA delineation using a network-based approach, in which HSAs are the communities extracted by the Louvain algorithm in hospital-patient discharge networks. Given the existent heterogeneity of communities extracted by different community detection algorithms, a comparative analysis of community detection algorithms for optimal HSA delineation is lacking. In this work, we compared HSA delineations produced by community detection algorithms using a large-scale dataset containing different types of hospital-patient discharges spanning a 7-year period in US. Our results replicated the heterogeneity among community detection algorithms found in previous works, the improved HSA delineation obtained by a network-based, and suggested that Infomap may be a more suitable community detection for HSA delineation since it finds a high number of HSAs with high localization index and a low network conductance.
Personalized Donor-Recipient Matching for Organ Transplantation
Nov 12, 2016


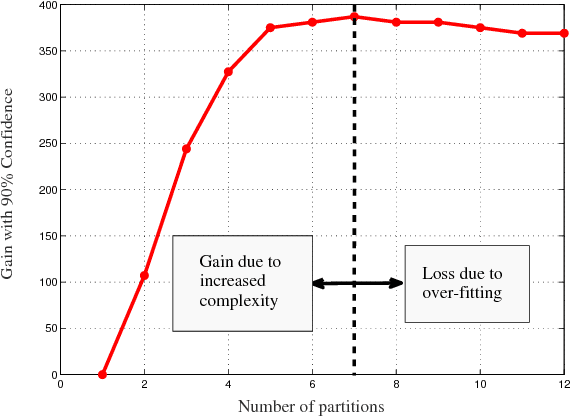
Organ transplants can improve the life expectancy and quality of life for the recipient but carries the risk of serious post-operative complications, such as septic shock and organ rejection. The probability of a successful transplant depends in a very subtle fashion on compatibility between the donor and the recipient but current medical practice is short of domain knowledge regarding the complex nature of recipient-donor compatibility. Hence a data-driven approach for learning compatibility has the potential for significant improvements in match quality. This paper proposes a novel system (ConfidentMatch) that is trained using data from electronic health records. ConfidentMatch predicts the success of an organ transplant (in terms of the 3 year survival rates) on the basis of clinical and demographic traits of the donor and recipient. ConfidentMatch captures the heterogeneity of the donor and recipient traits by optimally dividing the feature space into clusters and constructing different optimal predictive models to each cluster. The system controls the complexity of the learned predictive model in a way that allows for assuring more granular and confident predictions for a larger number of potential recipient-donor pairs, thereby ensuring that predictions are "personalized" and tailored to individual characteristics to the finest possible granularity. Experiments conducted on the UNOS heart transplant dataset show the superiority of the prognostic value of ConfidentMatch to other competing benchmarks; ConfidentMatch can provide predictions of success with 95% confidence for 5,489 patients of a total population of 9,620 patients, which corresponds to 410 more patients than the most competitive benchmark algorithm (DeepBoost).