 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnvironmental Insights: Democratizing Access to Ambient Air Pollution Data and Predictive Analytics with an Open-Source Python Package
Mar 06, 2024



Ambient air pollution is a pervasive issue with wide-ranging effects on human health, ecosystem vitality, and economic structures. Utilizing data on ambient air pollution concentrations, researchers can perform comprehensive analyses to uncover the multifaceted impacts of air pollution across society. To this end, we introduce Environmental Insights, an open-source Python package designed to democratize access to air pollution concentration data. This tool enables users to easily retrieve historical air pollution data and employ a Machine Learning model for forecasting potential future conditions. Moreover, Environmental Insights includes a suite of tools aimed at facilitating the dissemination of analytical findings and enhancing user engagement through dynamic visualizations. This comprehensive approach ensures that the package caters to the diverse needs of individuals looking to explore and understand air pollution trends and their implications.
A Data-Driven Supervised Machine Learning Approach to Estimating Global Ambient Air Pollution Concentrations With Associated Prediction Intervals
Feb 15, 2024



Global ambient air pollution, a transboundary challenge, is typically addressed through interventions relying on data from spatially sparse and heterogeneously placed monitoring stations. These stations often encounter temporal data gaps due to issues such as power outages. In response, we have developed a scalable, data-driven, supervised machine learning framework. This model is designed to impute missing temporal and spatial measurements, thereby generating a comprehensive dataset for pollutants including NO$_2$, O$_3$, PM$_{10}$, PM$_{2.5}$, and SO$_2$. The dataset, with a fine granularity of 0.25$^{\circ}$ at hourly intervals and accompanied by prediction intervals for each estimate, caters to a wide range of stakeholders relying on outdoor air pollution data for downstream assessments. This enables more detailed studies. Additionally, the model's performance across various geographical locations is examined, providing insights and recommendations for strategic placement of future monitoring stations to further enhance the model's accuracy.
A Framework for Scalable Ambient Air Pollution Concentration Estimation
Jan 16, 2024Ambient air pollution remains a critical issue in the United Kingdom, where data on air pollution concentrations form the foundation for interventions aimed at improving air quality. However, the current air pollution monitoring station network in the UK is characterized by spatial sparsity, heterogeneous placement, and frequent temporal data gaps, often due to issues such as power outages. We introduce a scalable data-driven supervised machine learning model framework designed to address temporal and spatial data gaps by filling missing measurements. This approach provides a comprehensive dataset for England throughout 2018 at a 1kmx1km hourly resolution. Leveraging machine learning techniques and real-world data from the sparsely distributed monitoring stations, we generate 355,827 synthetic monitoring stations across the study area, yielding data valued at approximately \pounds70 billion. Validation was conducted to assess the model's performance in forecasting, estimating missing locations, and capturing peak concentrations. The resulting dataset is of particular interest to a diverse range of stakeholders engaged in downstream assessments supported by outdoor air pollution concentration data for NO2, O3, PM10, PM2.5, and SO2. This resource empowers stakeholders to conduct studies at a higher resolution than was previously possible.
Network-Based Delineation of Health Service Areas: A Comparative Analysis of Community Detection Algorithms
Dec 08, 2019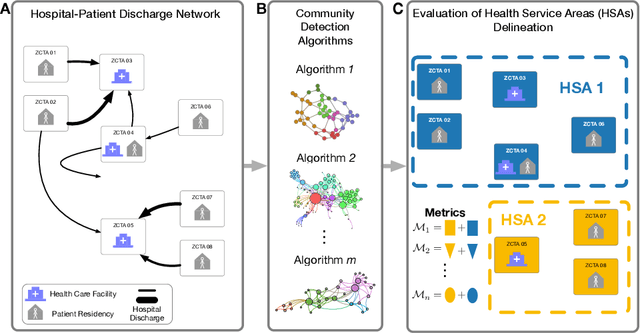

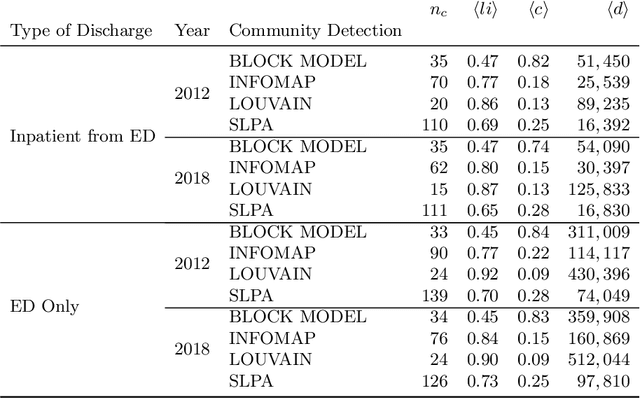
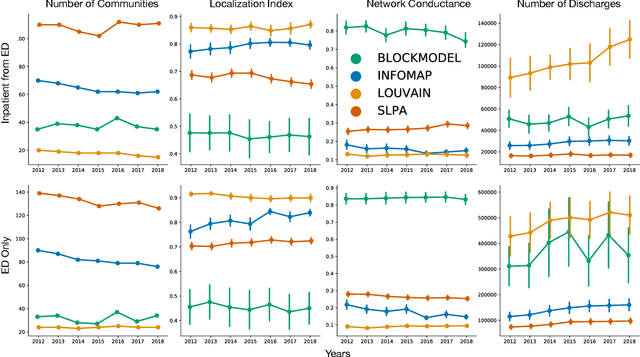
A Health Service Area (HSA) is a group of geographic regions served by similar health care facilities. The delineation of HSAs plays a pivotal role in the characterization of health care services available in an area, enabling a better planning and regulation of health care services. Though Dartmouth HSAs have been the standard delineation for decades, previous work has recently shown an improved HSA delineation using a network-based approach, in which HSAs are the communities extracted by the Louvain algorithm in hospital-patient discharge networks. Given the existent heterogeneity of communities extracted by different community detection algorithms, a comparative analysis of community detection algorithms for optimal HSA delineation is lacking. In this work, we compared HSA delineations produced by community detection algorithms using a large-scale dataset containing different types of hospital-patient discharges spanning a 7-year period in US. Our results replicated the heterogeneity among community detection algorithms found in previous works, the improved HSA delineation obtained by a network-based, and suggested that Infomap may be a more suitable community detection for HSA delineation since it finds a high number of HSAs with high localization index and a low network conductance.
Characterizing the Social Interactions in the Artificial Bee Colony Algorithm
Apr 08, 2019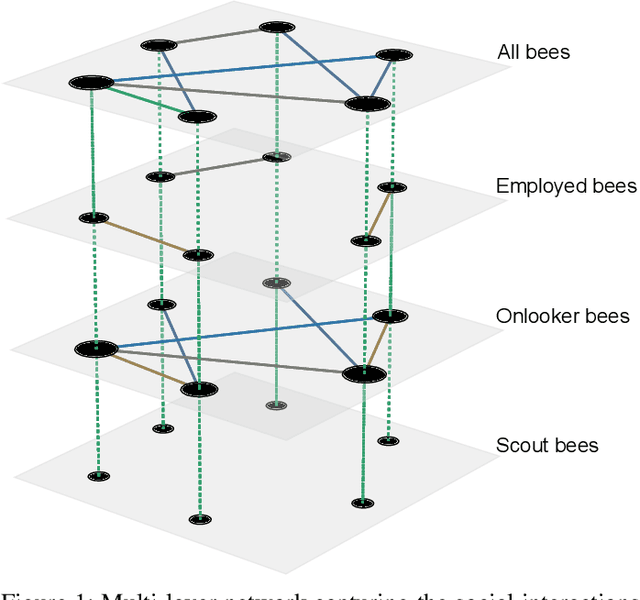


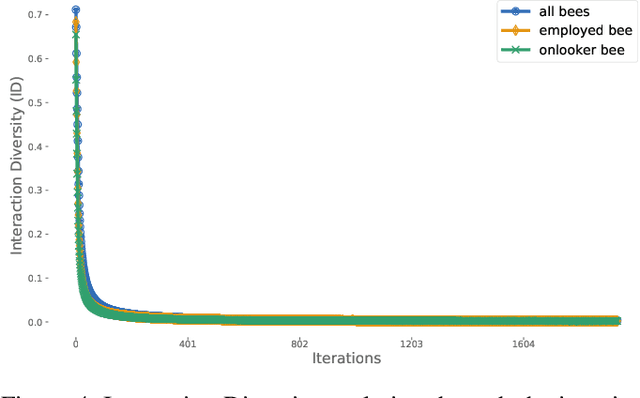
Computational swarm intelligence consists of multiple artificial simple agents exchanging information while exploring a search space. Despite a rich literature in the field, with works improving old approaches and proposing new ones, the mechanism by which complex behavior emerges in these systems is still not well understood. This literature gap hinders the researchers' ability to deal with known problems in swarms intelligence such as premature convergence, and the balance of coordination and diversity among agents. Recent advances in the literature, however, have proposed to study these systems via the network that emerges from the social interactions within the swarm (i.e., the interaction network). In our work, we propose a definition of the interaction network for the Artificial Bee Colony (ABC) algorithm. With our approach, we captured striking idiosyncrasies of the algorithm. We uncovered the different patterns of social interactions that emerge from each type of bee, revealing the importance of the bees variations throughout the iterations of the algorithm. We found that ABC exhibits a dynamic information flow through the use of different bees but lacks continuous coordination between the agents.
Unveiling Swarm Intelligence with Network Science$-$the Metaphor Explained
Nov 08, 2018
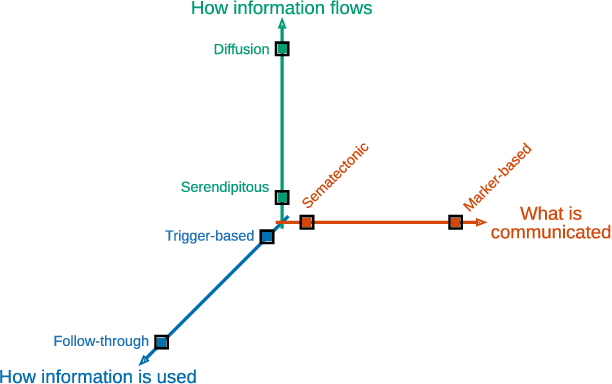
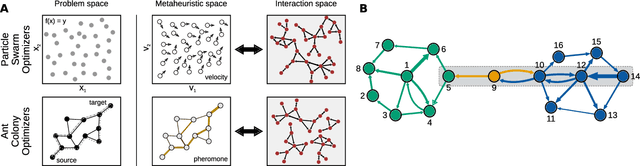
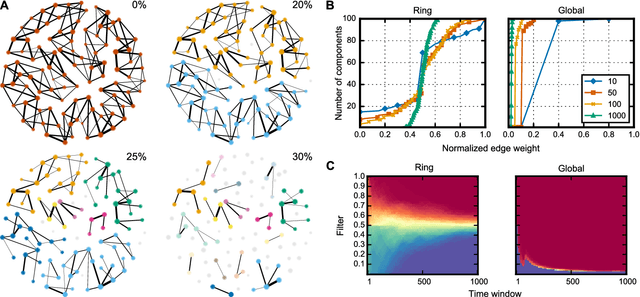
Self-organization is a natural phenomenon that emerges in systems with a large number of interacting components. Self-organized systems show robustness, scalability, and flexibility, which are essential properties when handling real-world problems. Swarm intelligence seeks to design nature-inspired algorithms with a high degree of self-organization. Yet, we do not know why swarm-based algorithms work well and neither we can compare the different approaches in the literature. The lack of a common framework capable of characterizing these several swarm-based algorithms, transcending their particularities, has led to a stream of publications inspired by different aspects of nature without much regard as to whether they are similar to already existing approaches. We address this gap by introducing a network-based framework$-$the interaction network$-$to examine computational swarm-based systems via the optics of social dynamics. We discuss the social dimension of several swarm classes and provide a case study of the Particle Swarm Optimization. The interaction network enables a better understanding of the plethora of approaches currently available by looking at them from a general perspective focusing on the structure of the social interactions.