 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
EvolKV: Evolutionary KV Cache Compression for LLM Inference
Sep 10, 2025Existing key-value (KV) cache compression methods typically rely on heuristics, such as uniform cache allocation across layers or static eviction policies, however, they ignore the critical interplays among layer-specific feature patterns and task performance, which can lead to degraded generalization. In this paper, we propose EvolKV, an adaptive framework for layer-wise, task-driven KV cache compression that jointly optimizes the memory efficiency and task performance. By reformulating cache allocation as a multi-objective optimization problem, EvolKV leverages evolutionary search to dynamically configure layer budgets while directly maximizing downstream performance. Extensive experiments on 11 tasks demonstrate that our approach outperforms all baseline methods across a wide range of KV cache budgets on long-context tasks and surpasses heuristic baselines by up to 7 percentage points on GSM8K. Notably, EvolKV achieves superior performance over the full KV cache setting on code completion while utilizing only 1.5% of the original budget, suggesting the untapped potential in learned compression strategies for KV cache budget allocation.
Debiasing Multilingual LLMs in Cross-lingual Latent Space
Aug 25, 2025Debiasing techniques such as SentDebias aim to reduce bias in large language models (LLMs). Previous studies have evaluated their cross-lingual transferability by directly applying these methods to LLM representations, revealing their limited effectiveness across languages. In this work, we therefore propose to perform debiasing in a joint latent space rather than directly on LLM representations. We construct a well-aligned cross-lingual latent space using an autoencoder trained on parallel TED talk scripts. Our experiments with Aya-expanse and two debiasing techniques across four languages (English, French, German, Dutch) demonstrate that a) autoencoders effectively construct a well-aligned cross-lingual latent space, and b) applying debiasing techniques in the learned cross-lingual latent space significantly improves both the overall debiasing performance and cross-lingual transferability.
Understanding Subword Compositionality of Large Language Models
Aug 25, 2025Large language models (LLMs) take sequences of subwords as input, requiring them to effective compose subword representations into meaningful word-level representations. In this paper, we present a comprehensive set of experiments to probe how LLMs compose subword information, focusing on three key aspects: structural similarity, semantic decomposability, and form retention. Our analysis of the experiments suggests that these five LLM families can be classified into three distinct groups, likely reflecting difference in their underlying composition strategies. Specifically, we observe (i) three distinct patterns in the evolution of structural similarity between subword compositions and whole-word representations across layers; (ii) great performance when probing layer by layer their sensitivity to semantic decompositionality; and (iii) three distinct patterns when probing sensitivity to formal features, e.g., character sequence length. These findings provide valuable insights into the compositional dynamics of LLMs and highlight different compositional pattens in how LLMs encode and integrate subword information.
Curiosity-Driven Reinforcement Learning from Human Feedback
Jan 20, 2025



Reinforcement learning from human feedback (RLHF) has proven effective in aligning large language models (LLMs) with human preferences, but often at the cost of reduced output diversity. This trade-off between diversity and alignment quality remains a significant challenge. Drawing inspiration from curiosity-driven exploration in reinforcement learning, we introduce curiosity-driven RLHF (CD-RLHF), a framework that incorporates intrinsic rewards for novel states, alongside traditional sparse extrinsic rewards, to optimize both output diversity and alignment quality. We demonstrate the effectiveness of CD-RLHF through extensive experiments on a range of tasks, including text summarization and instruction following. Our approach achieves significant gains in diversity on multiple diversity-oriented metrics while maintaining alignment with human preferences comparable to standard RLHF. We make our code publicly available at https://github.com/ernie-research/CD-RLHF.
MA-RLHF: Reinforcement Learning from Human Feedback with Macro Actions
Oct 03, 2024



Reinforcement learning from human feedback (RLHF) has demonstrated effectiveness in aligning large language models (LLMs) with human preferences. However, token-level RLHF suffers from the credit assignment problem over long sequences, where delayed rewards make it challenging for the model to discern which actions contributed to successful outcomes. This hinders learning efficiency and slows convergence. In this paper, we propose MA-RLHF, a simple yet effective RLHF framework that incorporates macro actions -- sequences of tokens or higher-level language constructs -- into the learning process. By operating at this higher level of abstraction, our approach reduces the temporal distance between actions and rewards, facilitating faster and more accurate credit assignment. This results in more stable policy gradient estimates and enhances learning efficiency within each episode, all without increasing computational complexity during training or inference. We validate our approach through extensive experiments across various model sizes and tasks, including text summarization, dialogue generation, question answering, and program synthesis. Our method achieves substantial performance improvements over standard RLHF, with performance gains of up to 30% in text summarization and code generation, 18% in dialogue, and 8% in question answering tasks. Notably, our approach reaches parity with vanilla RLHF 1.7x to 2x faster in terms of training time and continues to outperform it with further training. We will make our code and data publicly available at https://github.com/ernie-research/MA-RLHF .
Tokenization Falling Short: The Curse of Tokenization
Jun 17, 2024Language models typically tokenize raw text into sequences of subword identifiers from a predefined vocabulary, a process inherently sensitive to typographical errors, length variations, and largely oblivious to the internal structure of tokens-issues we term the curse of tokenization. In this study, we delve into these drawbacks and demonstrate that large language models (LLMs) remain susceptible to these problems. This study systematically investigates these challenges and their impact on LLMs through three critical research questions: (1) complex problem solving, (2) token structure probing, and (3) resilience to typographical variation. Our findings reveal that scaling model parameters can mitigate the issue of tokenization; however, LLMs still suffer from biases induced by typos and other text format variations. Our experiments show that subword regularization such as BPE-dropout can mitigate this issue. We will release our code and data to facilitate further research.
Dual Modalities of Text: Visual and Textual Generative Pre-training
Apr 17, 2024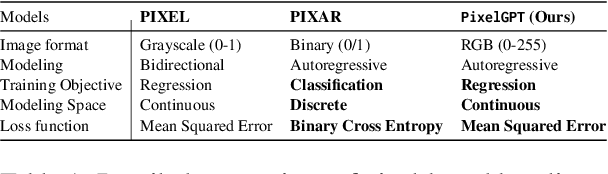
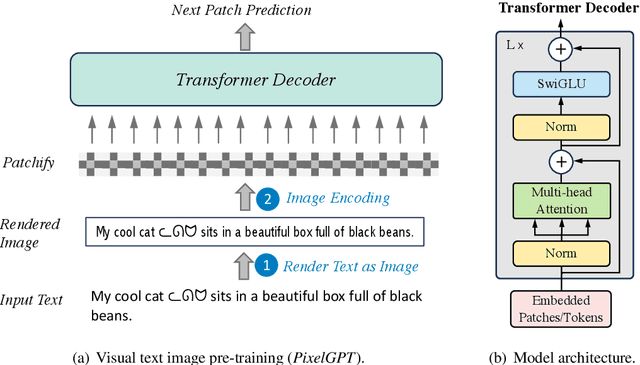
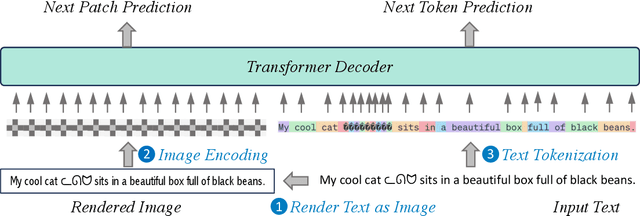

Harnessing visual texts represents a burgeoning frontier in the evolution of language modeling. In this paper, we introduce a novel pre-training framework for a suite of pixel-based autoregressive language models, pre-training on a corpus of over 400 million documents rendered as RGB images. Our approach is characterized by a dual-modality training regimen, engaging both visual data through next patch prediction with a regression head and textual data via next token prediction with a classification head. This study is particularly focused on investigating the synergistic interplay between visual and textual modalities of language. Our comprehensive evaluation across a diverse array of benchmarks reveals that the confluence of visual and textual data substantially augments the efficacy of pixel-based language models. Notably, our findings show that a unidirectional pixel-based model, devoid of textual data during training, can match the performance levels of advanced bidirectional pixel-based models on various language understanding benchmarks. This work highlights the considerable untapped potential of integrating visual and textual information for language modeling purposes. We will release our code, data, and checkpoints to inspire further research advancement.
On Training Data Influence of GPT Models
Apr 11, 2024



Amidst the rapid advancements in generative language models, the investigation of how training data shapes the performance of GPT models is still emerging. This paper presents GPTfluence, a novel approach that leverages a featurized simulation to assess the impact of training examples on the training dynamics of GPT models. Our approach not only traces the influence of individual training instances on performance trajectories, such as loss and other key metrics, on targeted test points but also enables a comprehensive comparison with existing methods across various training scenarios in GPT models, ranging from 14 million to 2.8 billion parameters, across a range of downstream tasks. Contrary to earlier methods that struggle with generalization to new data, GPTfluence introduces a parameterized simulation of training dynamics, demonstrating robust generalization capabilities to unseen training data. This adaptability is evident across both fine-tuning and instruction-tuning scenarios, spanning tasks in natural language understanding and generation. We will make our code and data publicly available.
Aurora-M: The First Open Source Multilingual Language Model Red-teamed according to the U.S. Executive Order
Mar 30, 2024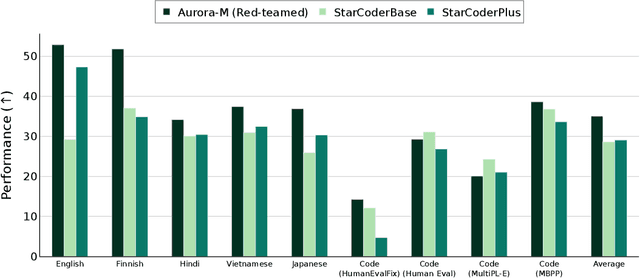

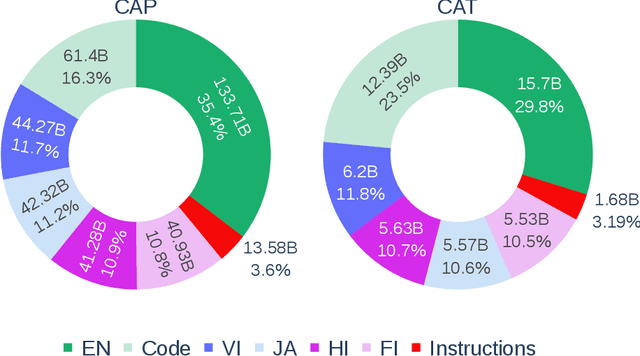
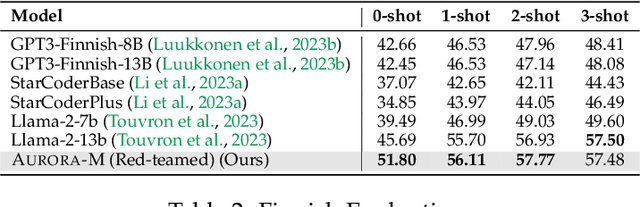
Pretrained language models underpin several AI applications, but their high computational cost for training limits accessibility. Initiatives such as BLOOM and StarCoder aim to democratize access to pretrained models for collaborative community development. However, such existing models face challenges: limited multilingual capabilities, continual pretraining causing catastrophic forgetting, whereas pretraining from scratch is computationally expensive, and compliance with AI safety and development laws. This paper presents Aurora-M, a 15B parameter multilingual open-source model trained on English, Finnish, Hindi, Japanese, Vietnamese, and code. Continually pretrained from StarCoderPlus on 435 billion additional tokens, Aurora-M surpasses 2 trillion tokens in total training token count. It is the first open-source multilingual model fine-tuned on human-reviewed safety instructions, thus aligning its development not only with conventional red-teaming considerations, but also with the specific concerns articulated in the Biden-Harris Executive Order on the Safe, Secure, and Trustworthy Development and Use of Artificial Intelligence. Aurora-M is rigorously evaluated across various tasks and languages, demonstrating robustness against catastrophic forgetting and outperforming alternatives in multilingual settings, particularly in safety evaluations. To promote responsible open-source LLM development, Aurora-M and its variants are released at https://huggingface.co/collections/aurora-m/aurora-m-models-65fdfdff62471e09812f5407 .