 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKrwEmd: Revising the Imperfect-Recall Abstraction from Forgetting Everything
Nov 15, 2025Excessive abstraction is a critical challenge in hand abstraction-a task specific to games like Texas hold'em-when solving large-scale imperfect-information games, as it impairs AI performance. This issue arises from extreme implementations of imperfect-recall abstraction, which entirely discard historical information. This paper presents KrwEmd, the first practical algorithm designed to address this problem. We first introduce the k-recall winrate feature, which not only qualitatively distinguishes signal observation infosets by leveraging both future and, crucially, historical game information, but also quantitatively captures their similarity. We then develop the KrwEmd algorithm, which clusters signal observation infosets using earth mover's distance to measure discrepancies between their features. Experimental results demonstrate that KrwEmd significantly improves AI gameplay performance compared to existing algorithms.
WGSR-Bench: Wargame-based Game-theoretic Strategic Reasoning Benchmark for Large Language Models
Jun 12, 2025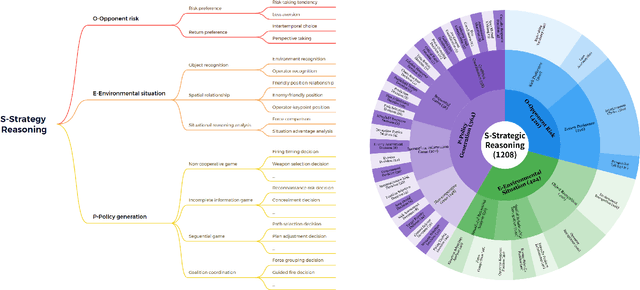
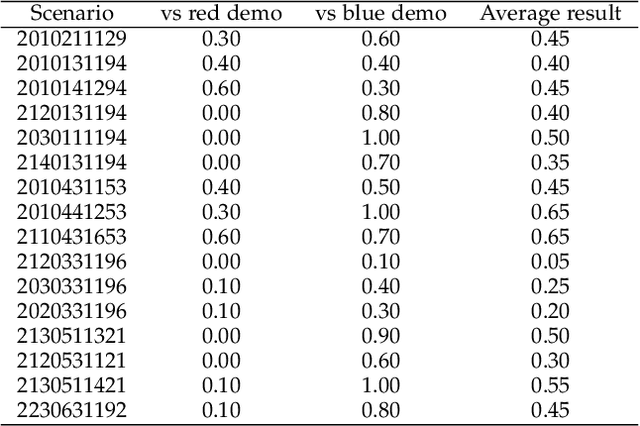
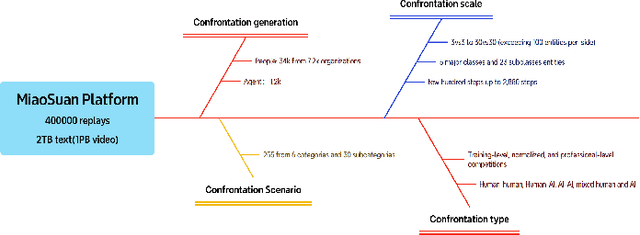
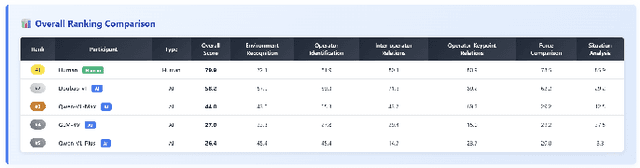
Recent breakthroughs in Large Language Models (LLMs) have led to a qualitative leap in artificial intelligence' s performance on reasoning tasks, particularly demonstrating remarkable capabilities in mathematical, symbolic, and commonsense reasoning. However, as a critical component of advanced human cognition, strategic reasoning, i.e., the ability to assess multi-agent behaviors in dynamic environments, formulate action plans, and adapt strategies, has yet to be systematically evaluated or modeled. To address this gap, this paper introduces WGSR-Bench, the first strategy reasoning benchmark for LLMs using wargame as its evaluation environment. Wargame, a quintessential high-complexity strategic scenario, integrates environmental uncertainty, adversarial dynamics, and non-unique strategic choices, making it an effective testbed for assessing LLMs' capabilities in multi-agent decision-making, intent inference, and counterfactual reasoning. WGSR-Bench designs test samples around three core tasks, i.e., Environmental situation awareness, Opponent risk modeling and Policy generation, which serve as the core S-POE architecture, to systematically assess main abilities of strategic reasoning. Finally, an LLM-based wargame agent is designed to integrate these parts for a comprehensive strategy reasoning assessment. With WGSR-Bench, we hope to assess the strengths and limitations of state-of-the-art LLMs in game-theoretic strategic reasoning and to advance research in large model-driven strategic intelligence.
Beyond the First Error: Process Reward Models for Reflective Mathematical Reasoning
May 20, 2025Many studies focus on data annotation techniques for training effective PRMs. However, current methods encounter a significant issue when applied to long CoT reasoning processes: they tend to focus solely on the first incorrect step and all preceding steps, assuming that all subsequent steps are incorrect. These methods overlook the unique self-correction and reflection mechanisms inherent in long CoT, where correct reasoning steps may still occur after initial reasoning mistakes. To address this issue, we propose a novel data annotation method for PRMs specifically designed to score the long CoT reasoning process. Given that under the reflection pattern, correct and incorrect steps often alternate, we introduce the concepts of Error Propagation and Error Cessation, enhancing PRMs' ability to identify both effective self-correction behaviors and reasoning based on erroneous steps. Leveraging an LLM-based judger for annotation, we collect 1.7 million data samples to train a 7B PRM and evaluate it at both solution and step levels. Experimental results demonstrate that compared to existing open-source PRMs and PRMs trained on open-source datasets, our PRM achieves superior performance across various metrics, including search guidance, BoN, and F1 scores. Compared to widely used MC-based annotation methods, our annotation approach not only achieves higher data efficiency but also delivers superior performance. Detailed analysis is also conducted to demonstrate the stability and generalizability of our method.
Improve the efficiency of deep reinforcement learning through semantic exploration guided by natural language
Sep 21, 2023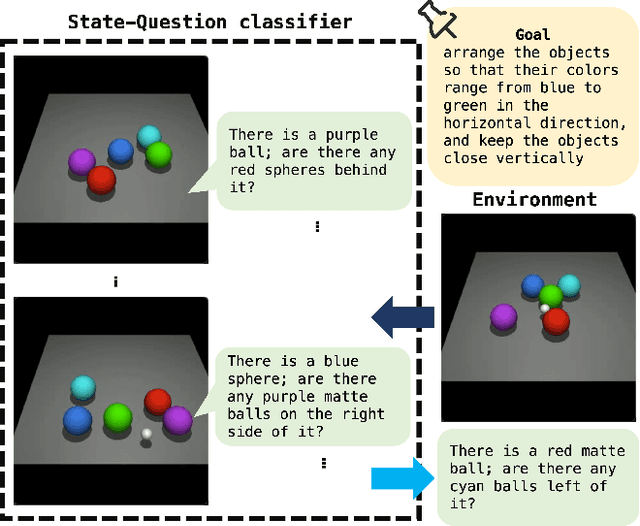
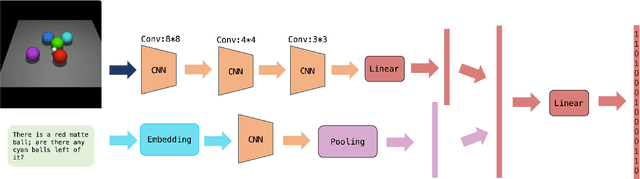
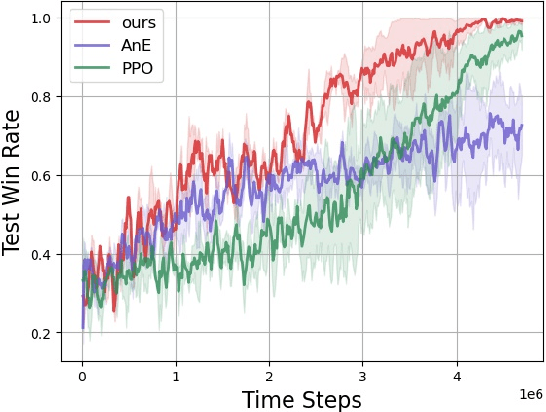
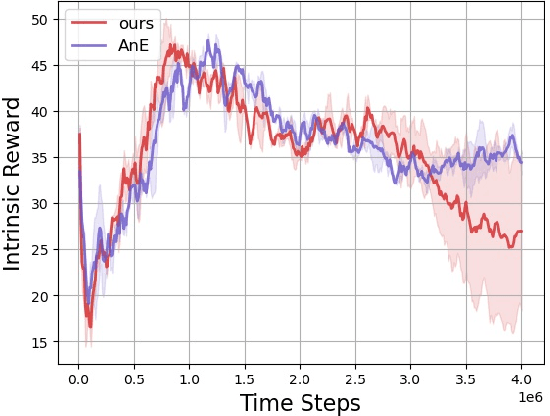
Reinforcement learning is a powerful technique for learning from trial and error, but it often requires a large number of interactions to achieve good performance. In some domains, such as sparse-reward tasks, an oracle that can provide useful feedback or guidance to the agent during the learning process is really of great importance. However, querying the oracle too frequently may be costly or impractical, and the oracle may not always have a clear answer for every situation. Therefore, we propose a novel method for interacting with the oracle in a selective and efficient way, using a retrieval-based approach. We assume that the interaction can be modeled as a sequence of templated questions and answers, and that there is a large corpus of previous interactions available. We use a neural network to encode the current state of the agent and the oracle, and retrieve the most relevant question from the corpus to ask the oracle. We then use the oracle's answer to update the agent's policy and value function. We evaluate our method on an object manipulation task. We show that our method can significantly improve the efficiency of RL by reducing the number of interactions needed to reach a certain level of performance, compared to baselines that do not use the oracle or use it in a naive way.
Improved Training of Mixture-of-Experts Language GANs
Feb 23, 2023



Despite the dramatic success in image generation, Generative Adversarial Networks (GANs) still face great challenges in synthesizing sequences of discrete elements, in particular human language. The difficulty in generator training arises from the limited representation capacity and uninformative learning signals obtained from the discriminator. In this work, we (1) first empirically show that the mixture-of-experts approach is able to enhance the representation capacity of the generator for language GANs and (2) harness the Feature Statistics Alignment (FSA) paradigm to render fine-grained learning signals to advance the generator training. Specifically, FSA forces the mean statistics of the distribution of fake data to approach that of real samples as close as possible in the finite-dimensional feature space. Empirical study on synthetic and real benchmarks shows the superior performance in quantitative evaluation and demonstrates the effectiveness of our approach to adversarial text generation.
Distributed Deep Reinforcement Learning: A Survey and A Multi-Player Multi-Agent Learning Toolbox
Dec 01, 2022With the breakthrough of AlphaGo, deep reinforcement learning becomes a recognized technique for solving sequential decision-making problems. Despite its reputation, data inefficiency caused by its trial and error learning mechanism makes deep reinforcement learning hard to be practical in a wide range of areas. Plenty of methods have been developed for sample efficient deep reinforcement learning, such as environment modeling, experience transfer, and distributed modifications, amongst which, distributed deep reinforcement learning has shown its potential in various applications, such as human-computer gaming, and intelligent transportation. In this paper, we conclude the state of this exciting field, by comparing the classical distributed deep reinforcement learning methods, and studying important components to achieve efficient distributed learning, covering single player single agent distributed deep reinforcement learning to the most complex multiple players multiple agents distributed deep reinforcement learning. Furthermore, we review recently released toolboxes that help to realize distributed deep reinforcement learning without many modifications of their non-distributed versions. By analyzing their strengths and weaknesses, a multi-player multi-agent distributed deep reinforcement learning toolbox is developed and released, which is further validated on Wargame, a complex environment, showing usability of the proposed toolbox for multiple players and multiple agents distributed deep reinforcement learning under complex games. Finally, we try to point out challenges and future trends, hoping this brief review can provide a guide or a spark for researchers who are interested in distributed deep reinforcement learning.
RACA: Relation-Aware Credit Assignment for Ad-Hoc Cooperation in Multi-Agent Deep Reinforcement Learning
Jun 02, 2022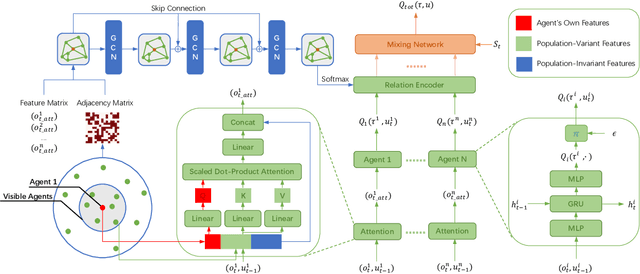
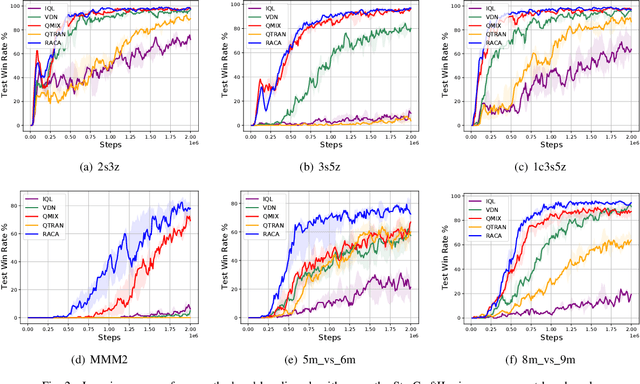
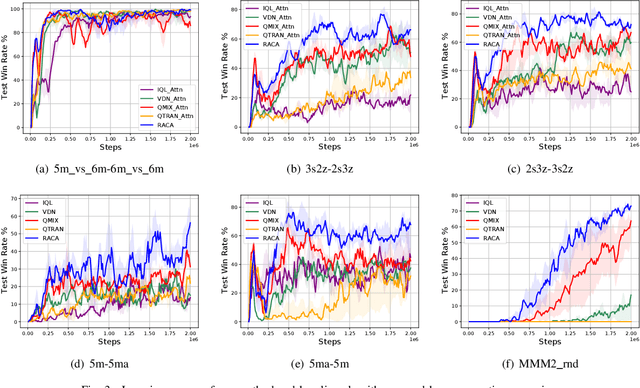
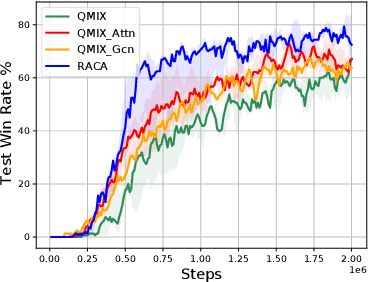
In recent years, reinforcement learning has faced several challenges in the multi-agent domain, such as the credit assignment issue. Value function factorization emerges as a promising way to handle the credit assignment issue under the centralized training with decentralized execution (CTDE) paradigm. However, existing value function factorization methods cannot deal with ad-hoc cooperation, that is, adapting to new configurations of teammates at test time. Specifically, these methods do not explicitly utilize the relationship between agents and cannot adapt to different sizes of inputs. To address these limitations, we propose a novel method, called Relation-Aware Credit Assignment (RACA), which achieves zero-shot generalization in ad-hoc cooperation scenarios. RACA takes advantage of a graph-based relation encoder to encode the topological structure between agents. Furthermore, RACA utilizes an attention-based observation abstraction mechanism that can generalize to an arbitrary number of teammates with a fixed number of parameters. Experiments demonstrate that our method outperforms baseline methods on the StarCraftII micromanagement benchmark and ad-hoc cooperation scenarios.
AI in Games: Techniques, Challenges and Opportunities
Nov 15, 2021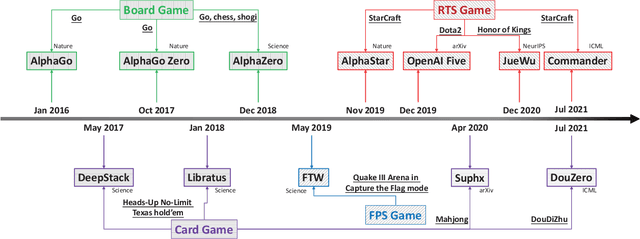

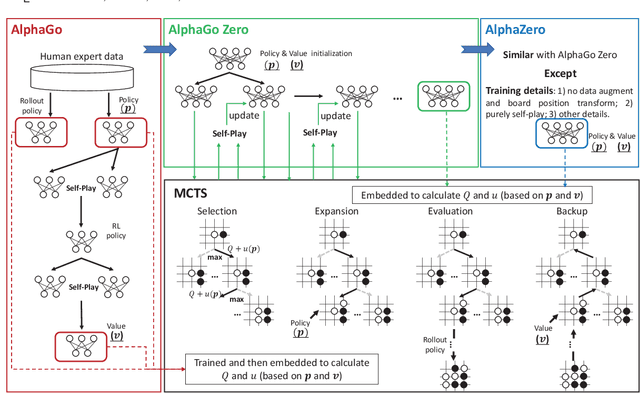
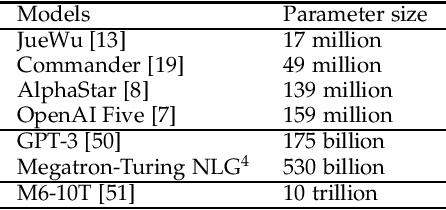
With breakthrough of AlphaGo, AI in human-computer game has become a very hot topic attracting researchers all around the world, which usually serves as an effective standard for testing artificial intelligence. Various game AI systems (AIs) have been developed such as Libratus, OpenAI Five and AlphaStar, beating professional human players. In this paper, we survey recent successful game AIs, covering board game AIs, card game AIs, first-person shooting game AIs and real time strategy game AIs. Through this survey, we 1) compare the main difficulties among different kinds of games for the intelligent decision making field ; 2) illustrate the mainstream frameworks and techniques for developing professional level AIs; 3) raise the challenges or drawbacks in the current AIs for intelligent decision making; and 4) try to propose future trends in the games and intelligent decision making techniques. Finally, we hope this brief review can provide an introduction for beginners, inspire insights for researchers in the filed of AI in games.
Learning to Reweight Imaginary Transitions for Model-Based Reinforcement Learning
Apr 09, 2021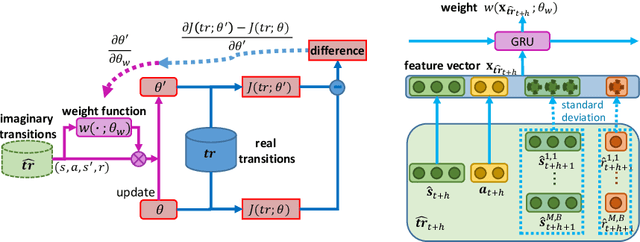
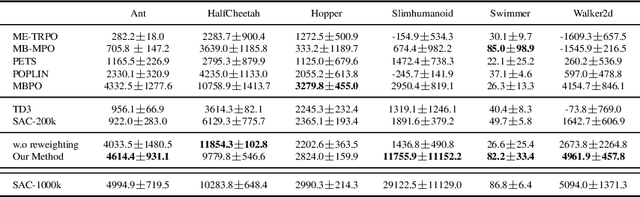
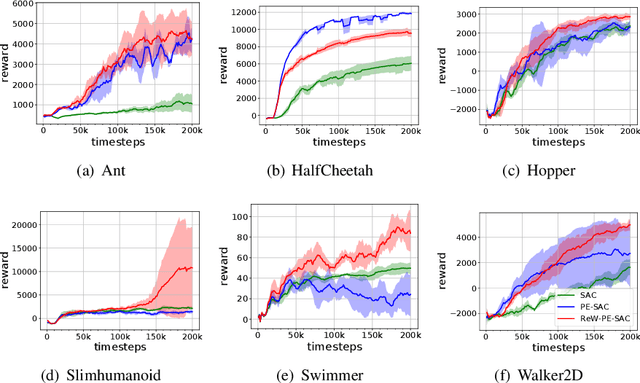
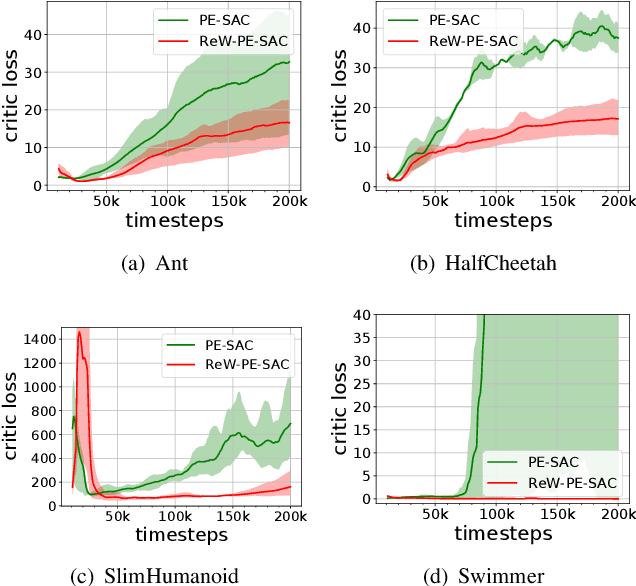
Model-based reinforcement learning (RL) is more sample efficient than model-free RL by using imaginary trajectories generated by the learned dynamics model. When the model is inaccurate or biased, imaginary trajectories may be deleterious for training the action-value and policy functions. To alleviate such problem, this paper proposes to adaptively reweight the imaginary transitions, so as to reduce the negative effects of poorly generated trajectories. More specifically, we evaluate the effect of an imaginary transition by calculating the change of the loss computed on the real samples when we use the transition to train the action-value and policy functions. Based on this evaluation criterion, we construct the idea of reweighting each imaginary transition by a well-designed meta-gradient algorithm. Extensive experimental results demonstrate that our method outperforms state-of-the-art model-based and model-free RL algorithms on multiple tasks. Visualization of our changing weights further validates the necessity of utilizing reweight scheme.
Planning with Exploration: Addressing Dynamics Bottleneck in Model-based Reinforcement Learning
Oct 24, 2020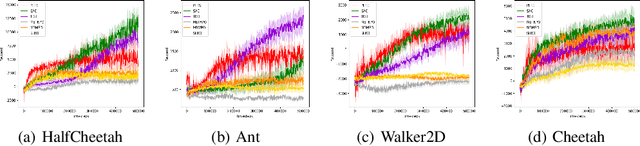

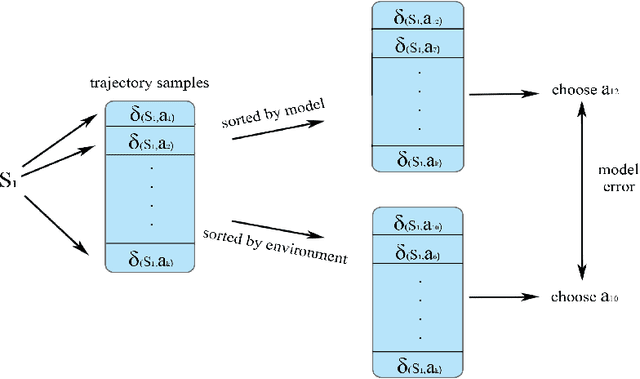
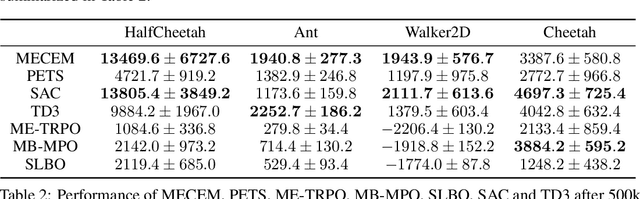
Model-based reinforcement learning is a framework in which an agent learns an environment model, makes planning and decision-making in this model, and finally interacts with the real environment. Model-based reinforcement learning has high sample efficiency compared with model-free reinforcement learning, and shows great potential in the real-world application. However, model-based reinforcement learning has been plagued by dynamics bottleneck. Dynamics bottleneck is the phenomenon that when the timestep to interact with the environment increases, the reward of the agent falls into the local optimum instead of increasing. In this paper, we analyze and explain how the coupling relationship between model and policy causes the dynamics bottleneck and shows improving the exploration ability of the agent can alleviate this issue. We then propose a new planning algorithm called Maximum Entropy Cross-Entropy Method (MECEM). MECEM can improve the agent's exploration ability by maximizing the distribution of action entropy in the planning process. We conduct experiments on fourteen well-recognized benchmark environments such as HalfCheetah, Ant and Swimmer. The results verify that our approach obtains the state-of-the-art performance on eleven benchmark environments and can effectively alleviate dynamics bottleneck on HalfCheetah, Ant and Walker2D.